我在谷歌实习时发现了一个模型 bug,于是有了这篇 ACL

文 | AlbertYang
编 | 小轶
表格的自动理解与检索已经成为 NLP 以及多模态任务中重要的一环。如果我们给模型一个冬奥会的奖牌榜并且问,“哪个国家的金牌最多?”,现有的模型已经可以毫不费力地输出正确的答案(通常都是表格首行的国家金牌最多)。
但是如果我们把表格的所有行顺序打乱,模型还能输出正确答案吗?又或者模型依然无脑选择首行的国家呢?
小编在谷歌实习期间,发现模型在理解表格时总是通过行列顺序的线索作弊。于是乎,为了解决这个问题,我在 ACL2022 的这篇文章里提出了 TableFormer,一种对表格行列顺序扰动严格鲁棒的架构,引入了 13 种可学习的注意力偏置标量。
由此,TableFormer 还能够更好地编码表格结构,以及对齐表格和相应的文本描述(例如自动问答中的问题)。
TableFormer 在基于表格的自动问答和事实核查的三个常用数据集中都取得了不俗的表现,并在基于表格的连续问答任务中实现SOTA。当面临表格行列扰动时,TableFormer由于其严格的鲁棒性,比之前最好的模型得到6%-10%的绝对提升!
下面我们来看看这篇文章的具体细节吧。
论文题目:
TableFormer: Robust Transformer Modeling for Table-Text Encoding
论文链接:
https://arxiv.org/pdf/2203.00274.pdf
代码将于以下地址开源:
https://github.com/google-research/tapas
![]() 关于表格理解
关于表格理解![]()
 关于表格理解
关于表格理解需要模型编码表格的典型任务包括:
-
基于表格的语义解析(如文本转SQL),输出常常是能够 在表格上执行的SQL语句 -
基于表格的自动问答,输出是 从表格中提取或者生成的答案 -
基于表格的事实核查,输出是 二分类标签(表示语言表述是否符合表格事实)
模型除了要编码半结构化的表格数据,还需要具有能够同时编码表格与文本的能力。
很多图片与文本编码的多模态模型也被用来编码表格与文本。
同时,为了在表格理解推理的任务上实现SOTA结果,需要在预先收集的表格文本对上大规模预训练,甚至数据扩增。
最新的方法与文章可以参考本文的相关工作,或者作者整理的论文列表:
https://github.com/JingfengYang/Multi-modal-Deep-Learning#table
此前应用最广泛的架构是 TAPAS [4],也是很长时间里 huggingface transformers 里唯一存在的表格问答模型 [2]。为了编码表格结构,TAPAS 以及之前的工作都需要将表格序列化并和文本拼接起来当作 BERT(或者 BART)的输入。
为了在序列化的表格中加入表格结构信息,在编码单元格时,TAPAS使用了行 ID 向量和列 ID 向量作为额外的特征,其他很多模型把表头中相应的列名当作额外的特征或者单元格的前置 token。
然而,行列 ID 以及 BERT(BART)中存在的序列相对位置或者绝对位置编码会引入表格行列顺序的虚假偏置(spurious bias)。
在回答绝大多数问题时,我们希望模型真正理解表格内容,而不是根据行列顺序的虚假偏置来作出判断。理想情况下,模型只需要知道同行同列信息即可,不需要知道额外的行及列的顺序信息。
实验表明,用TAPAS执行表格问答任务时,如果在预测阶段加入随机的行列扰动,模型的表现会下降4%-6%。
![]() TableFormer结构
TableFormer结构![]()
为了解决上述问题,并且进行更好的表格结构编码以及文本表格内容对齐,本文引入了13种结构化注意力偏置,每种偏置用一个可学习的标量表示,与self-attention 中key value计算好并且scaling之后的similarity score相加,以针对不同的结构位置自动调整注意力程度。
举例来说,表格中某个token对同一行或者同一列的token会有特定的注意力分数,对文本token会有特定的注意力分数,对表头相应的列名称也会有特定的注意力分数。
用公式表示的话,就是对Transfomer中的self-attention机制做了如下调整:
其中, 是序列中第i个query 的向量表示, 是序列中第j个key的向量表示, 是query和key的关系对应的归纳偏置标量。前面提到,共有13种关系对应13种偏置:

其中同行注意力偏置能够帮助编码token位于表格同一行的信息,同列注意力偏置、当前token对相应表头列名的注意力偏置、表头列名对该列单元格token的注意力偏置能够帮助编码同一列信息,当前token对相应表头列名的偏置能够让单元格注意到表头信息而不需要多次重复地将表头前置于每个单元格,表头对文本以及单元格对文本的注意力偏置能够帮助对齐文本描述和相应表格内容(grounding)。
为了实现对行列扰动的严格鲁棒性,本文删除了 TAPAS 的表格行 ID 以及列ID,并把BERT的全序列位置编码改成每个单元格独立的位置编码,即每个单元格的 token 序列从 0 开始编码。
删除这些行列顺序相关的信息后,表格结构的编码完全由行列注意力偏置实现。这样,无论如何扰动表格行列顺序,在 TableFormer 的视角,输入总是完全相同的,由此可以保证扰动前后预测的完全一致性。
TableFormer 的模型输入以及注意力偏置结构如图所示:

![]() 实验与分析
实验与分析![]()
本文在三个表格理解与推理的数据集上进行了实验,分别为SQA(基于表格的连续问答),WTQ(基于表格的复杂问答),和TabFact(基于表格的事实核查)。
除了标准的评测数据,本文还将SQA和TabFact的测试集中的表格行列施加随机扰动,构造了扰动测评的场景。
除了标准的评测指标,本文还提出了一个 VP(variation percentage)指标来度量所有测试样例中扰动前后预测出现变化的比例的下界,可以作为样例水平鲁棒性的上界(VP越低越鲁棒)。
其中 t2t, t2f, f2t, f2f 分别表示扰动后预测从正确变为正确,从正确变为错误,从错误变为正确,从错误变为错误的样例数目。
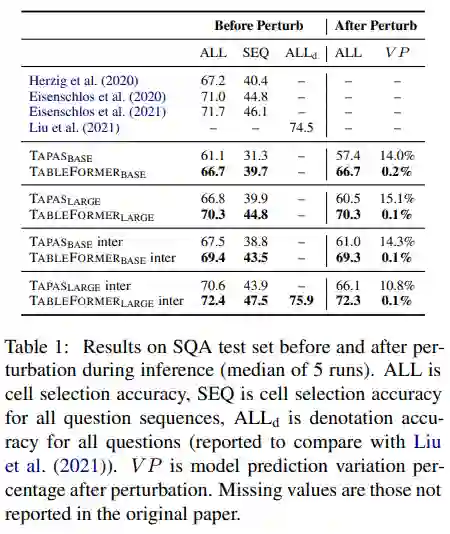
在SQA的标准测试集上,TableFormer超过了所有baseline实现了SOTA,在扰动测试的场景下取得了比相应TAPAS模型高出6% - 10%的绝对提升:
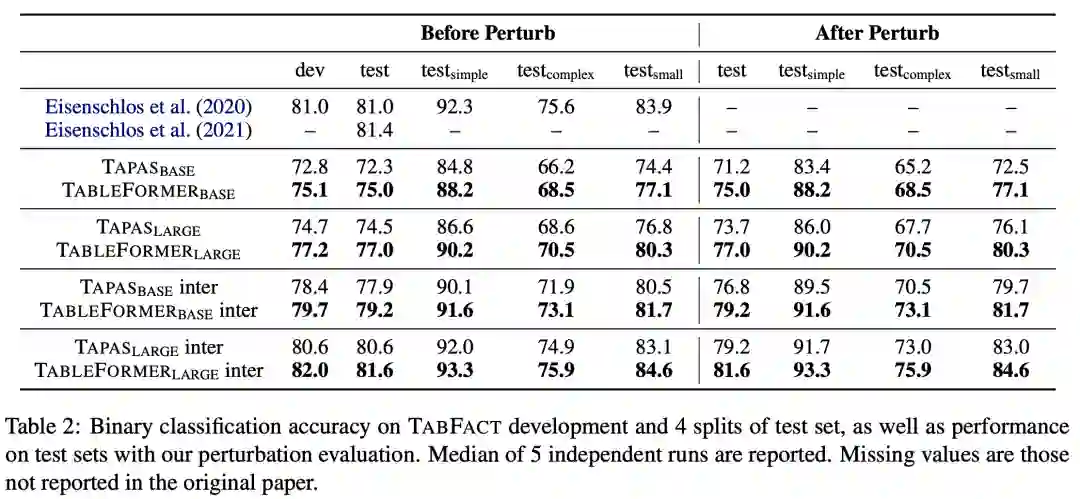
在TabFact上同样取得了比TAPAS显著的提升,在扰动测试的场景下提升更为明显:
同样,在WTQ上TableFormer也稳定超越了TAPAS(具体实验结果可见原文)。
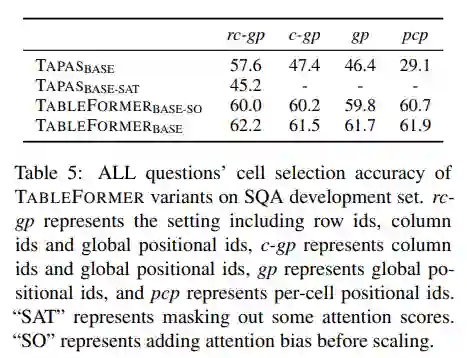
本文还设计了一系列对比实验,指出在设计TableFormer时,有一些重要的启示:
-
可学习的注意力偏置比注意力掩码更适合表格结构编码,可能是因为严格的行列掩码限制了token注意到非同行同列单元格token的能力。 -
施加注意力偏置的位置很重要,要在计算key value 的相似分数以及scaling之后加注意力偏置标量,而非在scaling之前。即 优于 ,这是因为scaling的目的是为了调整key value 高维向量点积后向量的模长,而注意力偏置是一个标量,不需要scaling,注意力偏置的 scaling会导致偏置分数缩小,从而限制偏置对于最终注意力分数的影响,并且影响表格结构偏置的注入效果。 -
TAPAS删除行列ID以及将序列全局位置编码改成单元格内部位置编码后,模型效果显著下降,而TableFormer在这些改动之后可以维持效果,说明TableFormer的注意力偏置已经足够用来编码表格结构,而不需要额外的行列信息。
相关实验数据如下表:
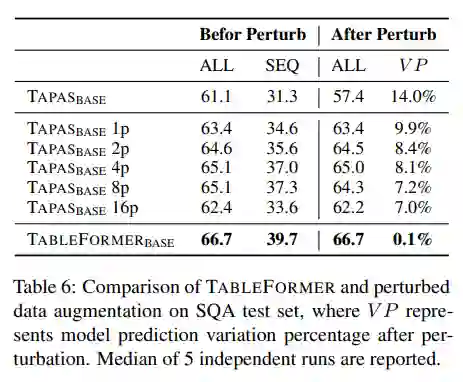
另一个很自然的想法来解决表格行列顺序扰动带来的影响是在训练时随机扰动表格进行数据扩增,而不改变TAPAS的模型结构。
本文也对TableFormer和这种数据扩增进行了对比实验。实验表明,数据扩增虽然可以减小扰动对于模型总体效果的影响,但最好的表现依然逊色于TableFormer,可能由于TableFormer带来了额外的有效偏置信息(如文本表格对齐等)。
并且,数据扩增无法保证样例水平模型预测对扰动的鲁棒性,从而VP远远高于TableFormer接近于0的VP:
![]() 启示
启示![]()
本文除了发现表格行列扰动下模型的鲁棒性问题以及提出TableFormer严格的解决方案外,还带给我们一些启示:
-
类似TableFormer、Graphomer [3],很多结构化与半结构化的数据都可以用注意力偏置标量来编码token间的关系。 -
结构化数据编码模型的鲁棒性问题应该被重视。 -
设计模型时每一个component的选择都要非常用心,例如归纳偏置加在scaling之后或者之前,对模型表现就有很大的影响。
作者简介:
本科毕业于北大,Georgia Tech硕士毕业后,暂时放弃UW CS NLP的PhD,去工业界Amazon做了Applied Scientist。不管在哪里,还是希望能做一些扎实的研究或者应用问题。
后台回复关键词【入群】
加入卖萌屋NLP、CV与搜推广求职讨论群
后台回复关键词【顶会】
获取ACL、CIKM等各大顶会论文集!
![]()
[1] Yang, Jingfeng, et al. "TableFormer: Robust Transformer Modeling for Table-Text Encoding." ACL 2022.
[2] https://huggingface.co/models?pipeline_tag=table-question-answering&sort=downloads
[3] Ying, Chengxuan, et al. "Do Transformers Really Perform Badly for Graph Representation?." Advances in Neural Information Processing Systems 34 (2021).
[4] Herzig, Jonathan, et al. "TaPas: Weakly supervised table parsing via pre-training." ACL 2020.
 后台回复关键词【
后台回复关键词【