猿桌会总结 | 圣路易斯华盛顿大学刘晨:室内场景的结构化重建

随着增强现实,家务机器人等应用的普及,室内场景重建研究正在得到越来越广泛的关注。与传统底层密集重建方法不同,讲者的研究集中在分析重建场景中的高层结构化信息。
在本次AI研习社大讲堂上,来自圣路易斯华盛顿大学的计算机系在读博士刘晨分享了其结构化重建的最新工作。
分享嘉宾:
刘晨,圣路易斯华盛顿大学计算机系在读博士,导师是Yasutaka Furukawa教授,主要研究方向为三维视觉,场景理解等。其研究工作曾在 CVPR、ICCV、ECCV等会议发表。
公开课回放地址:
http://www.mooc.ai/open/course/538?=Leiphone
分享主题:室内场景的结构化重建
分享提纲:
结构化场景重建的定义及意义
单目结构化重建
俯视图结构化重建
多目结构化重建
雷锋网AI研习社将其分享内容整理如下:
非常高兴能在这个平台上和大家分享我们组的最新研究成果,这次的分享题目是《室内场景的结构化重建》。
大家都知道,从一个场景中理解分析三维的几何信息是一个非常重要的计算机视觉问题。传统的方法多是用一些底层次的三维表示,比如说密集的点云、密集网格模型或者是深度图。这些低层次的三维表示虽然看起来很美观,但是却不好分析和理解,因此并不是很实用。

我们的研究希望出一个中看也中用的表示。作为人类,我们会及时辨别一个场景中哪些部分是完整的地面,哪些部分是完整的墙,我们希望计算机也能做到。
在俯视图结构化重建上,由于墙和地面往往是垂直的,所以俯视图能够给我们提供非常多的信息,我们的目标是希望能够得到矢量图形平面图,主要是基于墙角的点以及所有墙角之间的连线,这将对我们理解整个室内结构提供非常多的有用信息。
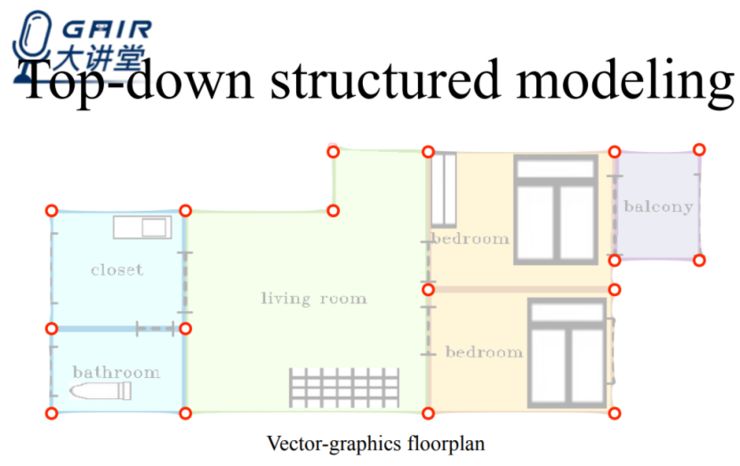
为了获得矢量图形平面图,我们会考虑使用 PNG 图像、点云、镭射扫描作为输入。
对于结构化的定义,有以下这三点:
一、 场景与结构的表示是简洁的
二、 场景是根据语义来分割的
三、 分析理解的方式与人类保持一致
结构化表示可以在机器人导航、室内装饰、虚拟购房导航以及虚拟现实效果优化等方面起作用。
单目结构化重建
目前实现结构化表示方面我们遇到哪些挑战呢?
首先,高层次的场景理解需要提取整个平面;
其次,室内存在许多造成干扰的遮挡物体;
最后,室内场景的平面往往缺乏纹理。
为了应对挑战,我们提取了室内场景的特性:平面性与正交性,利用这两点来做单目结构化重建的工作。我们试图从照片中提取出所需要的平面,并估计每个平面的三维参数,进而确定平面的三维结构信息。
过去虽然有一些底层次的三维重建工作也取得了不错的效果,却面临着不够直观和平滑的问题。
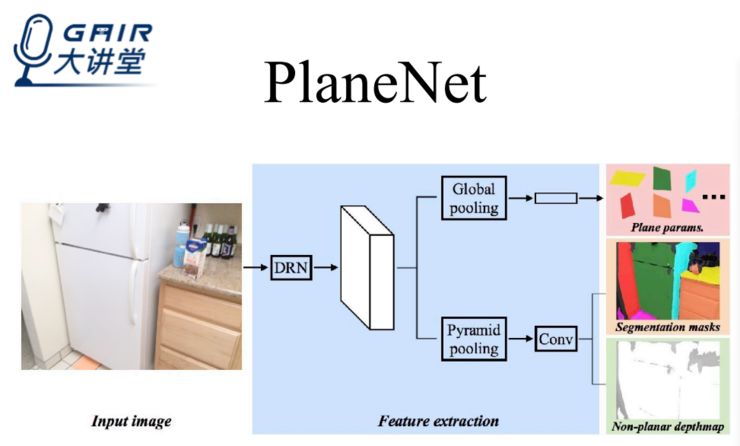
在我们的工作中,我们假定一个图像拥有十个平面,每个平面分别用三维空间中的三个参数来表示,最终确定三维结构;为了进一步确认在三维空间中的范围,我们会计算 segmentation masks;至于非平面区域,则估算 pixel-wise 的 depth map。
这三种信息合起来便是图片的三维场景信息。
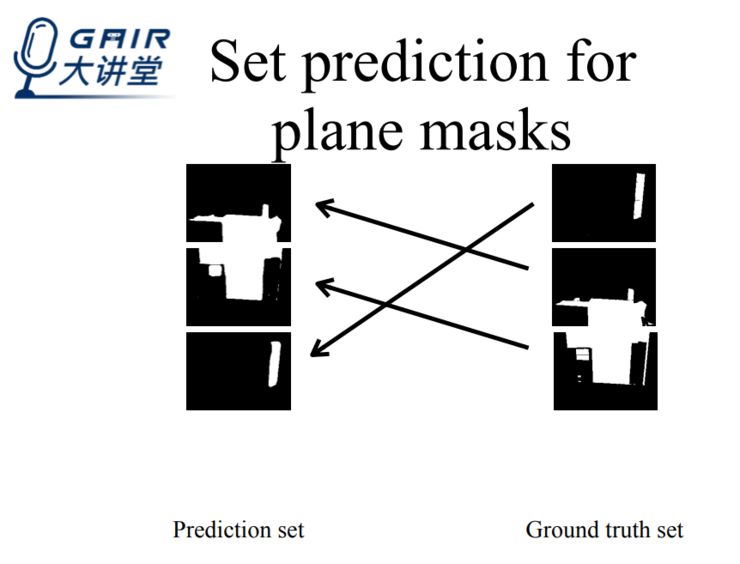
这样做会遇到什么挑战呢?那就是我们无法确认第一个输出的平面长什么样,因为我们是根据 geometry 来做分割。
于是我们使用 set matching 解决以上问题——在确认 prediction 以后,我们在 Ground truth 里为每个 prediction 找到最近零作为监督。为了进一步提升重建效果,我们还用 ground truth 的 text 来做监督学习。
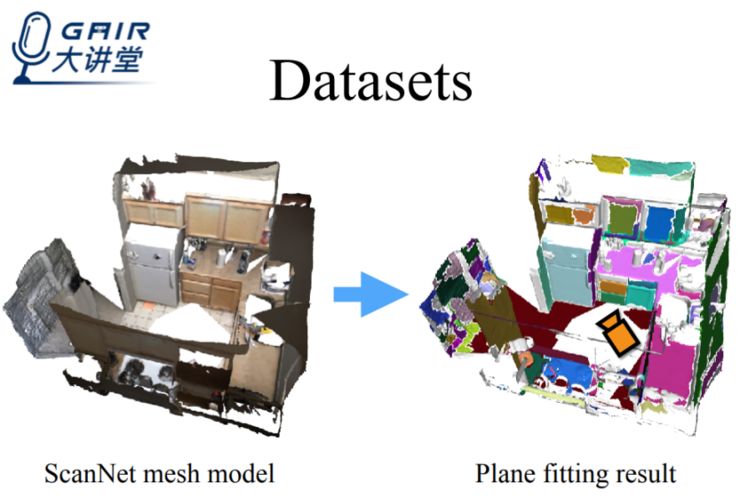
此外,我们使用了包含多种三维模型的 ScanNet 数据集作为训练网络,结合相机参数,将三维空间中的平面投映到二维上来,以获得最终需要的训练数据——plane parameters, segmentation masks 和非平面区域的 depth map。
这份工作的意义在于,我们可以在平面图上添加一些虚拟元素(电视、动态 logo、游戏),以增强虚拟现实的呈现效果。

从上图来看,我们的算法对于大平面的检测质量还是比较稳定的,只是在一些边缘部分或者小平面还存在一些问题。
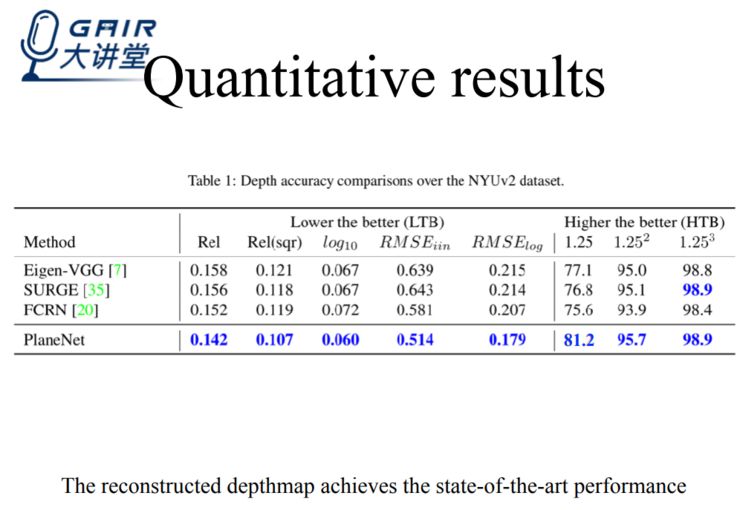
另外,我们最终获得的 depthmap,不单能够保证内部的绝对平滑,且在精度上也不比其他算法差。
关于这项工作,我们未来试图探索的方向有:
一、 如何将单幅图像结构重建拓展到多幅图像;
二、 考虑分析遮挡信息;
三、 用于室外场景;
四、 考虑更复杂的表面表示信息。
俯视图结构化重建
关于俯视图结构化重建,我将着重分享如何从 Jpeg 图像和点云中进行恢复重建。
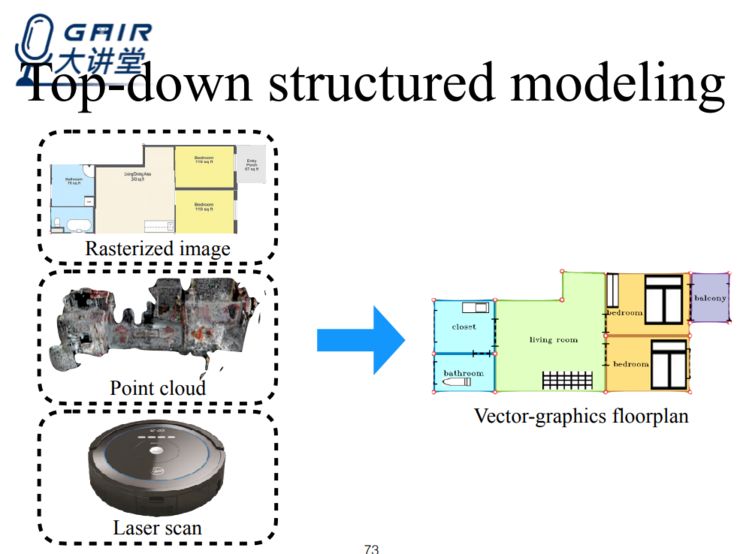
这种矢量图的价值在于:
可以帮助我们对建筑做出直观的分析理解;
在有需要时可以将结构图转成三维空间实现渲染效果;
如果你是一名建筑师,还可以随时修改自己的设计图。
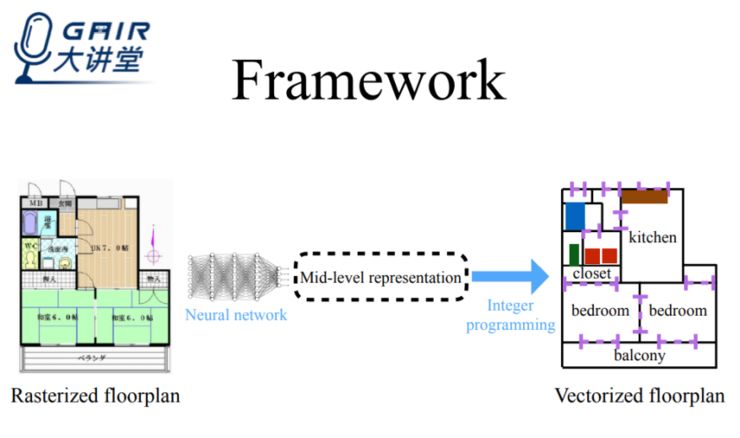
为了获取矢量图,我们借鉴了 Human pose estimation 方法,并解决了所面临的任意拓扑挑战。在我们的工作中,会先通过深度网络找到图中的关键元素(墙角、门、物体……),然后再利用 Integar Programming(IP)进行优化。总的来说,前者构成了我们的中间层表示,后者最终优化出最终的结构图。
【更多关于 Integar Programming 的优化细节,请回看视频 00:25:20 处,http://www.mooc.ai/open/course/538?=Leiphone】
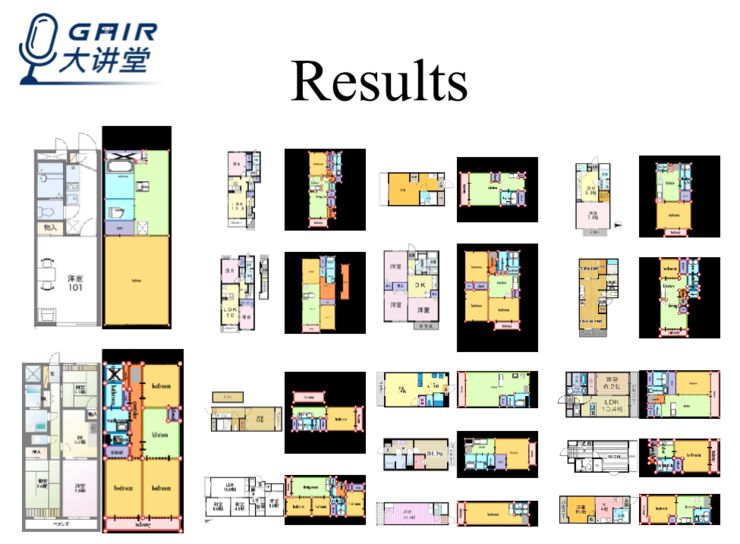
以下都是我们的工作成果。
我们和其他的算法进行了比较,结果显示,在不同结构化信息的 accuracy 和 recall 上,我们的算法基本上达到了 90 分,效果甚至比一些传统的算法要好。
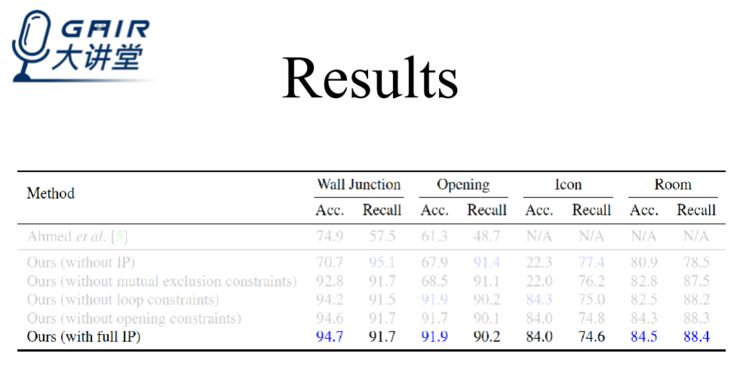
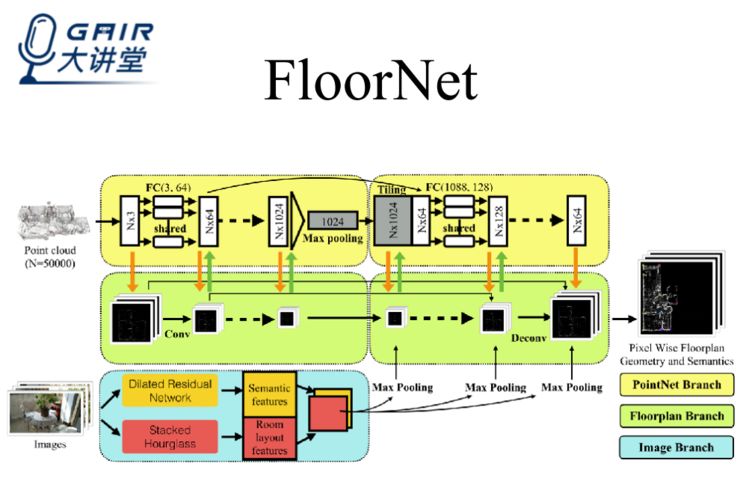
此外,为了达到简化生成俯视结构图流程的目的,我们后续做了通过点云生成矢量图的工作,也就是说,只要一部可以拍出包含深度信息照片的手机,我们就可以轻易获得空间的点云,进而生成俯视结构图。
生成流程方面,我们只是将之前的输入从 Jpeg 图像换成了点云。
这项工作的挑战在于如何从点云中提取出中间层表示,原因有三:
一、 现有的三维学习方法不擅长处理大规模的点云;
二、 全局的分析理解需要基于整体点云的理解;
三、 如何将 3D 信息与图像信息结合到一起。
【更多关于点云中间层提取的细节,请回看视频 00:36:44 处,http://www.mooc.ai/open/course/538?=Leiphone】
以下是我们最终的工作成果,结果显示我们的 Prediction 和 Ground Truth 很接近:

在下一步的工作中,我们会着重在以下三个方面进行拓展:
一、 摆脱 primitive detection 的框架
二、 用深度网络取代 Integer Programming(IP)
三、 直接使用 rgb 图像进行重建
多目结构化重建
多目结构化重建希望可以实现用户拍摄一组 rgb 照片,结合照片和机位信息,就可以完美重建结构化模型。
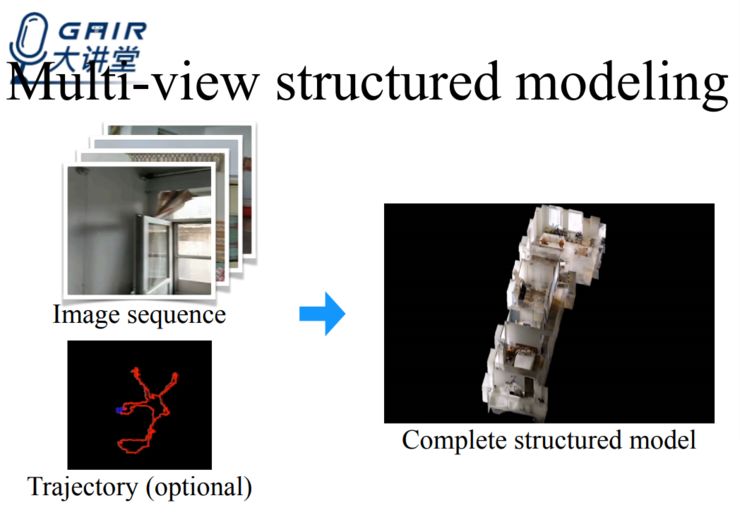
这项工作的难点在于:
一、 缺少三维信息的数据;
二、 难以找到两幅图像之间的对应关系;
三、 当前的分析可能会基于早先的发现。
作为进行中的工作,我们先提出了一些 baselines 模型:
一项是基于 Wireframe3D 的表示,可以检测出二维空间里的角点和连线信息,进而获得三维空间中的 Wireframe 表示。

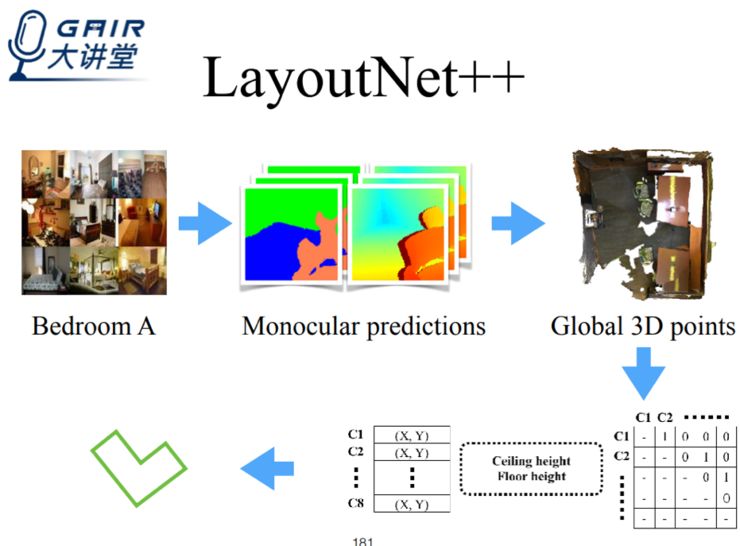
另外一项则是增强了鲁棒性的 LayoutNet++,网络先对两幅图像的共同之处做聚类,再根据聚类对信息进行单独处理,最后将所有输出拼到一起。
【更多关于 LayoutNet++的操作原理,请回看视频 00:44:50 处,http://www.mooc.ai/open/course/538?=Leiphone】
我今天的分享就这么多,谢谢大家。
以上就是本期嘉宾的全部分享内容。更多公开课视频请到雷锋网(公众号:雷锋网)AI研习社社区(http://www.gair.link)观看。关注微信公众号:AI 研习社(okweiwu),可获取最新公开课直播时间预告。




