2021 , NLP大事记
在过去的一年里,自然语言处理(NLP)领域发生了很多事情,本文将从作者的视角出发盘点一下一年来的行业亮点。
读者很忙的话可以先看下面这一段:
如果你只打算阅读一篇今年发表的关于 NLP 的文章,那就读这一篇:The Chatbot Problem (https://www.newyorker.com/culture/cultural-comment/the-chatbot-problem),纽约客发文。
如果你只打算读一篇今年发表的论文,我强烈推荐《论随机鹦鹉的危险:语言模型会大过头吗?》:https://dl.acm.org/doi/pdf/10.1145/3442188.3445922
如果你只想花时间学习一门课程来了解最前沿的 NLP 技术,请学习 Hugging Face 的 课程(免费!):https://huggingface.co/course/chapter1/1
如果你只想看一个关于 NLP 的视频,谷歌的这个 LaMDA 演示 (https://www.youtube.com/watch?v=aUSSfo5nCdM&ab_channel=CNETHighlights)是非常令人印象深刻的。
一 月
我们先来看个有趣的东西:《果蝇可以学习词嵌入吗?》(https://arxiv.org/abs/2101.06887)本文研究了生物学和神经网络之间的关系。虽然当下的这一代深度学习方法会从生物学中汲取高层灵感,但前者不一定符合生物学的理论。这就提出了一个问题,即生物系统是否可以进一步为新生网络架构和学习算法的开发提供灵感,从而显著提升机器学习任务的性能表现,或提供对智能行为的更多见解。
为此,研究人员使用了一个模拟的果蝇大脑,这是神经科学中研究最深入的网络之一。而且令人惊讶的是,事实上他们能够证明这个网络确实可以学习单词与其上下文之间的相关性,并生成高质量的词嵌入。
要跟踪自然语言生成(NLG)的进展状况不是一件容易的事情,因为就其本质而言,NLG 任务没有正确与否的固定定义。为了克服这一挑战并跟踪 NLG 模型的进展,一个由来自 44 家机构的 55 名研究人员组成的全球项目 提出了 GEM(生成、评估和度量),这是一个以评估为重点的 NLG 动态基准环境。
GEM 项目的最终目标是实现对数据和模型的深入分析,而不是只靠单一的排行榜分数定高下。该项目通过跨越许多 NLG 任务和语言的 13 个数据集来度量 NLG 进展状况,希望它也可以为未来分别使用自动化和人工指标生成的文本提供评估标准。
研究人员已经向 NLG 研究社区开放了该项目,高级成员可以帮助新人做出贡献。GEM 基准测试放在 gem-benchmark.com 上,更多信息也可以在 Hugging Face 上的 Dataset Hub :https://huggingface.co/datasets/gem#dataset-description 找到。
免责声明:我为 AWS 工作,所以接下来这个主题我 100% 会有偏见,但老实说我认为它非常酷:)
Hugging Face 和 AWS 之间的 合作关系 (https://huggingface.co/blog/the-partnership-amazon-sagemaker-and-hugging-face)从根本上改变了我的工作。我敢肯定,本文的读者肯定都很熟悉 Hugging Face。今年 3 月宣布的这一合作伙伴关系引入了新的 Hugging Face 深度学习容器(DLC),让人们可以更轻松地在 Amazon SageMaker 中训练和部署 Hugging Face Transformer 模型。
Philipp Schmid 提供的这个令人惊叹的 Github存储库(https://github.com/huggingface/notebooks/tree/master/sagemaker/) 可让你试用所有新功能,从分布式训练到模型部署和自动缩放等等。
剑桥大学化学系和物理系于 4 月发表了一篇非凡的 论文( https://www.pnas.org/content/118/15/e2019053118#abstract-2),其中描述了他们如何训练不同类型的语言模型。
研究人员使用序列嵌入(一种著名的 NLP 技术)将蛋白质序列转换为 200 维嵌入向量。可能你会有点疑惑,但 200 维确实被认为是这种复杂信息的低维表示!这项技术使团队能够训练一种新的语言模型,其性能优于使用公开可用数据集预测蛋白质液液相分离(LLPS)的几种现有机器学习方法。
我不会假装我很了解什么是 LLPS,但根据我的理解,它们是理解蛋白质分子语法和发现潜在错误的基础。这可能是癌症和神经退行性疾病(如阿尔茨海默病、帕金森病和亨廷顿病)研究取得突破的第一步。
我很确定你曾在某个时候尝试过与你的某位智能家居助理做某种程度的对话。反正我是试过,而且对话从来没能持续多久。交谈一两次后,助理一般就没法把对话再延伸下去了,而且这种尝试通常会以令人沮丧的“我不确定我是否理解你刚才说的话”而告终。
在今年 5 月的谷歌 I/O 大会上,该公司宣布了其在对话式 AI 领域的最新进展,LaMDA(https://blog.google/technology/ai/lamda/)(对话应用语言模型)。它是一种会话语言模型,似乎能够进行更长时间的对话。他们在演示里与冥王星和纸飞机交谈,当然令人印象深刻。我们还要感谢他们告诉大家该模型仍处于早期阶段,并指出了它的一些局限性。我非常希望谷歌在某个时候发布一个可以试玩的版本。
如果你喜欢弱小的新手对抗强大权威的故事,那么这个可能很适合你:
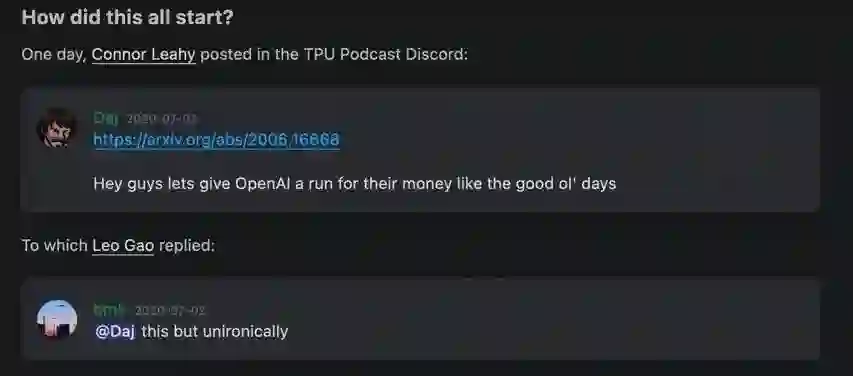
这是 Connor Leahy 和 Leo Gao 之间的交流,后者创立了 EleutherAI,一个由志愿者研究人员、工程师和开发人员组成的去中心化草根集体,专注于 AI 对齐、扩展和开源 AI 研究。他们成立于 2020 年 7 月,其旗舰项目是 GPT-Neo 系列模型,旨在复制 OpenAI 开发的 GPT-3 模型。他们的 Discord服务器(https://discord.gg/zBGx3azzUn)是开放的,欢迎贡献者。
6 月,他们发布了最新模型 GPT-J,有 60 亿个参数,而 GPT-3 有 1750 亿个。尽管体积小得多,但 GPT-J 在诸如编写代码之类的专业任务中表现优于它的庞大表亲。
我发现这种趋势非常令人鼓舞,并且很期待看到 EleutherAI 的下一步发展。
7 月,纽约客发表了一篇关于语言模型偏见的 文章(https://www.newyorker.com/culture/cultural-comment/the-chatbot-problem)。这在 NLP 社区中并不是一个新话题。然而,像纽约客这样的杂志会讨论这样的话题,凸显了现代 NLP 模型的重要性和它们引发的社会担忧。这让我想起了 2020 年卫报关于 GPT-3 的 文章(https://www.theguardian.com/commentisfree/2020/sep/08/robot-wrote-this-article-gpt-3)——这是小众话题被主流媒体注意到的经典时刻。
纽约客的文章侧重于语言模型如何反映我们的语言并最终反映我们自己的喜好。尤其是这句话让我印象深刻:“我们被迫以技术问题的形式来面对人类的终极隐秘:我们对内心的黑暗知之甚少,我们对黑暗的控制力又是如此微弱。”
下一个故事与纽约客的文章引起了类似的共鸣,因为 Margaret Mitchell 在八月加入了 Hugging Face。在 2021 年 2 月被解雇之前,Mitchell 是谷歌伦理 AI 研究员。她与他人合著了(以她的笔名 Shmargaret Shmitchel)一篇关于大型 NLP 模型相关成本和风险的 论文(https://dl.acm.org/doi/pdf/10.1145/3442188.3445922):
我们已经意识到了与追求更大的 LM 相关的各种成本和风险,包括:环境成本(主要来自那些无法从技术成果中受益的各方);财务成本,这反过来又设置了进入壁垒,限制了可以为该研究领域做出贡献的人群数量,以及可以从最先进的技术中受益的语言种类;机会成本,因为研究人员会将精力从需要较少资源的方向上抽走;如果人类将看似连贯的 LM 输出视为可以对所说内容负责的某个人或组织发表的言论,那么还会存在重大伤害的风险,包括成见、诋毁、助长极端主义意识形态和错误逮捕等。我很高兴看到 Mitchell 加入 Hugging Face,这是一家推动开源机器学习和繁荣社区的公司。如果你想更多地了解她在 Hugging Face 的工作,请查看她的 视频(https://www.youtube.com/watch?v=8j9HRMjh_s8&ab_channel=HuggingFace),了解在开发机器学习项目时要牢记的价值观。
说到开源 NLP,Explosion (https://explosion.ai/)也度过了美好的一年。这是 spaCy(https://spacy.io/)背后的公司,它是最受欢迎的 NLP 库之一。9 月,他们通过 1.2 亿美元的估值在 A 轮融资中筹集了 600 万美元。
我不得不承认,我在 2021 年没有跟上 spaCy 的最新动态,因为我主要专注于在 Transformers 库中提升自己的技能。所以,我很惊讶地看到 spaCy 今年早些时候发布的 spaCy 3.0 包含了那么多新特性。我肯定会在 2022 年再次将注意力转向 spaCy。
Explosion 不仅提供了最流行的 NLP 库之一,还创建了 Prodigy (https://explosion.ai/software#prodigy),一种现代注释工具。这很重要,因为创建更好模型的一种潜在方法是首先创建更好的训练数据——这就是数据注释工具派上用场的地方。
看到一位女性(Ines Montani)成为一家人工智能公司的 CEO 也是很不错的趋势信号:)
10 月举行了 2021 年 NLP 峰会(https://www.nlpsummit.org/nlp-2021/)。本次会议展示了众多 NLP 最佳实践、真实案例研究、在实践中应用深度学习和迁移学习的挑战——以及你今天可以使用的最新开源库、模型和转换器。
许多 NLP 圈内知名的演讲者在本次会议中上台发言,其中一些亮点有:
我们为什么以及应该如何关心 NLP 伦理?
科学文献的极致总结
利用人工智能进行招聘以实现经济复苏你可以在他们的 网站https://www.nlpsummit.org/nlp-2021-on-demand/ 上按需访问所有演讲。
Hugging Face 度过了相当不错的一年,我不得不再提一次。11 月,该公司发布了他们课程 (https://huggingface.co/course/chapter1/1) 的第二部分,帮助你快速开始使用最先进的 NLP 模型。本课程将带你踏上一段学习旅程,首先从高级 Pipeline API 开始,该 API 可让你通过两行代码利用 NLP 技术。然后它逐渐深入到 Transformers 堆栈中——在你意识到之前,你已经从头开始创建出自己的语言模型了。
第二部分于 11 月推出,一同发布的还有一系列讲座和讨论,你可以在此处找到 它们 (https://www.youtube.com/playlist?list=PLo2EIpI_JMQvcXKx5RFReyg6Qd2UICAif)。
本文的最后一部分自然也提供了对 NLP 领域未来发展的展望。12 月,Louisa Xu 在福布斯发表了她关于自然语言黄金时代的 文章(https://www.forbes.com/sites/louisaxu/2021/12/01/a-golden-age-for-natural-language/)。
这是一篇很棒的文章,介绍了目前最有影响力的三家 NLP 公司。她的总结和观点写得很好,我这里就摘录一段她的原文:
每家能从语言中获得价值的公司都将从 NLP 中受益,NLP 是机器学习中最具变革潜力的分支。语言是我们几乎所有互动活动中的最小公约数,在过去三年中,我们从语言中获取价值的方式发生了巨大变化。NLP 的最新进展成果在提升业务绩效方面具有巨大潜力。它甚至有望为我们的在线互动带来信任和诚信。很多大型企业已率先加入,但真正的前景将体现在下一波 NLP 应用程序和工具中,这些应用程序和工具会将围绕人工智能的那些宣传从意识形态转变为现实成果。
以上就是我个人对 2021 年 NLP 领域的亮点总结。我希望大家喜欢这篇总结文章,我也很期待能听到你对过去 12 个月 NLP 领域的个人亮点总结。请在评论中写下自己的想法吧~
原文链接:
https://towardsdatascience.com/a-2021-nlp-retrospective-b6f51e60026a

你也「在看」吗?👇


