我与NLP这七年

©作者 | 潘浩杰
单位 | 快手MMU
研究方向 | 自然语言处理

幻想萌芽


幻想冲击


模式识别
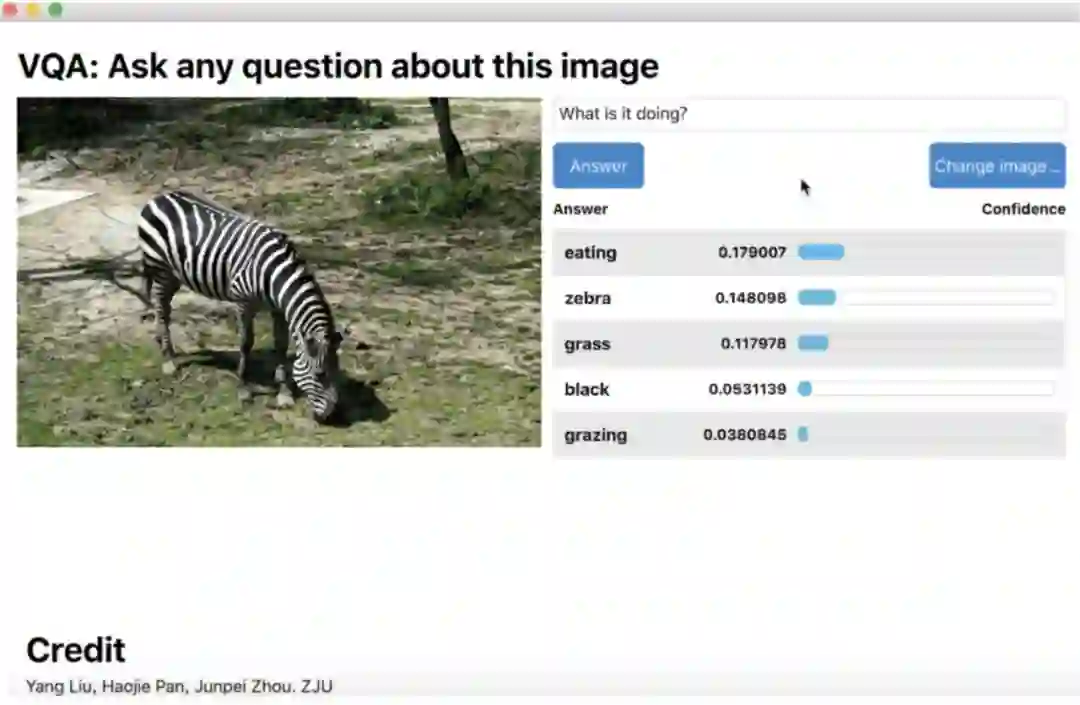

文本生成
当时的伏羲实验室还是非常小的团队,NLP 的成员只有三个人,当时我们探索过很多文本生成方向,包括简历筛选理由生成、智能台本生成、智能 NPC 等落地当时都无疾而终,在实习期间,也不止一次感到迷茫。
我还记得,当我实现第一个 Seq2seq 模型,第一次看 Memory Network 论文时的那种欣喜感,并认为在大量对话数据下,用 Memory 的手段解决对话的长期依赖问题,再基于对话生成功能,就真的能初步实现一定程度上的“智能体”,能够流畅地与人进行对话。

世界知识

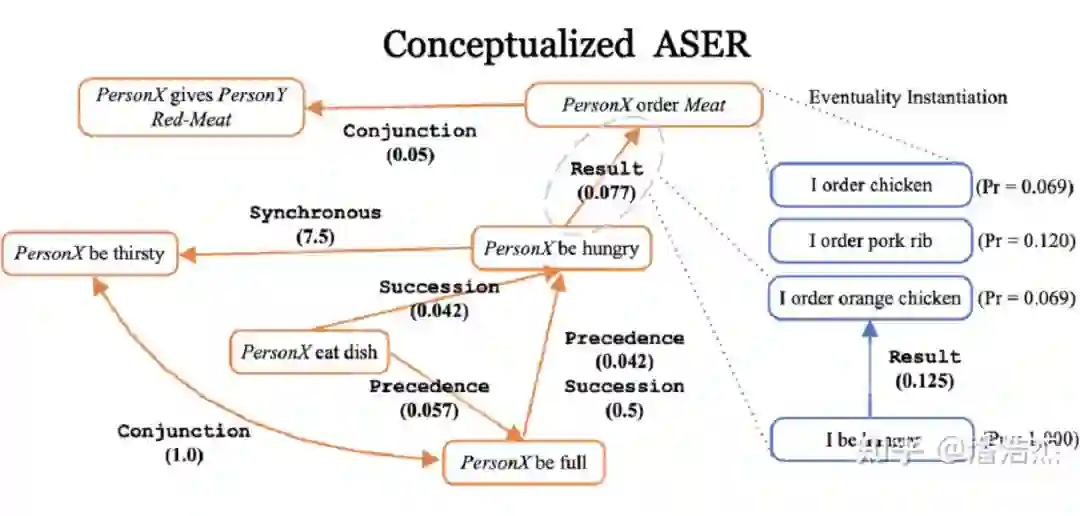
除却 ASER 这个令人回味无穷的项目以外,还有我的硕士毕业论文也是让我和 Yangqiu 非常激动和废寝忘食的一个 Topic,其源头是我 AAAI’19 被拒的一篇基于 Caption 和 VisualDialogue 的一篇 Dialogue Summarization 论文 [5] ,我们惊喜地发现,通过图片建立起对话和描述间的关系,竟然可以把一些人类语言学的更深层次知识给挖掘起来,因此我们花了很长的时间去研究语用学(Pragmatics),以及对应的两个子概念:
Implicature:“小 A 会参加这次聚会嘛”“她家里有事” → “小 A 不会参加这次聚会”
-
Presupposition: “我不想再去这家餐厅了” → “我曾经去过这家餐厅”
我研究生的这段经历,让我以非常舒畅的状态对世界知识、常识与语言学有了更深的了解,绝对是我拼图中非常浓墨重彩的一笔。当然,因为当时醉心于世界知识的构建,错过了 NLP 十年难遇的突破性工作——大规模预训练语言模型(PLM)。

业界落地

拼图重组

参考文献
更多阅读




#投 稿 通 道#
让你的文字被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
📝 稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
📬 投稿通道:
• 投稿邮箱:hr@paperweekly.site
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿

△长按添加PaperWeekly小编
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧

登录查看更多
相关内容

视觉问答(Visual Question Answering,VQA),是一种涉及计算机视觉和自然语言处理的学习任务。这一任务的定义如下: A VQA system takes as input an image and a free-form, open-ended, natural-language question about the image and produces a natural-language answer as the output[1]。 翻译为中文:一个VQA系统以一张图片和一个关于这张图片形式自由、开放式的自然语言问题作为输入,以生成一条自然语言答案作为输出。简单来说,VQA就是给定的图片进行问答。
Arxiv
0+阅读 · 2022年4月15日




相关VIP内容
相关资讯