BERTopic:NLP主题模型的未来!

文| ZenMoore
编| 小轶
以前我一直以为,主题建模(提取文档的主题词)这种机器学习时代就开始研究的基础工具,现在肯定已经到头了,虽然...有时效果可能不是那么让人满意。
但突然看到一则推文:“彻底疯了!不需要预先清洗数据,就能够快速拿到质量难以置信的主题!” “NLP 主题模型的未来!”


好家伙!让人又爱又恨又离不开的主题模型,终于要升华了吗?!!
看了论文之后,恍然大悟,完全没有想到现在主流主题模型的问题竟然出在这么细节的地方:基于密度聚类和基于中心采样(主题词)之间的 gap ! 而且这个问题也竟然可以通过非常简单的方式解决......
回顾一下之前的主题建模的方式,可以简单地分成两种:
-
基于词袋的模型:比如 LDA(潜在狄利克雷分配)、NMF(非负矩阵分解) 等。 -
基于预训练词嵌入的聚类方法:比如 Top2Vec[1], CTM[2], Sia et al., 2020[3]等。
基于词袋的方法主要是基于文档-单词的共现频率特征来抽取主题。其缺点在于:没有充分考虑每个单词的上下文语义 。例如 LDA 算法,假定主题的先验分布和单词的先验分布都服从狄利克雷分布,又假定每个主题的单词分布、每个文档的主题分布均服从多项分布,然后再在“文档-单词”共现数据上通过 EM 等算法去求解得到主题。
在深度学习时代,我们更偏好使用基于预训练词嵌入的方式。一般而言,这类方法首先通过一个预训练的模型(比如 Doc2Vec、Word2Vec、GloVe、BERT)计算出文档的向量表示以及单词的向量表示,然后把它们嵌入到同一个语义空间中。假定主题相似的文档在嵌入空间中的位置也是相近的(聚类),然后从这个嵌入空间的簇中去采样主题词。
通常这些簇以基于密度的方式聚类[5]形成。这样聚类后形成的簇不一定是“球状”的(sphere-like),每个簇的边界形状可以千奇百怪(如下图)。
基于质心的聚类:假定每个簇是一个球状结构(sphere-like) (其实是一个并不太合理的约束...) 基于层次的聚类:假定数据点存在层次关系,例如“国家”-“省份”-“城市”这种。 基于密度的聚类:挨在一起的就是一类的,不一定必须是 sphere-like 所以,基于层次和密度的聚类是最合理的方式。
然而,此前的方法是怎么做的呢?例如 Top2Vec[1],它会先将簇的质心(centroid) 作为主题向量, 然后认为:对于一个给定的词语,其词向量与主题向量距离越近,则它越能代表这一主题。
这就出现问题了朋友们:聚类时是基于密度的,采词却是基于与质心的距离!(盲生发现了华点!)
举个栗子。在下图中有一个长条状的簇,其质心用红色“X”标记。按照 Top2Vec 的做法,采词空间如红色圆周所示。可以看到,采词空间中有一部分并不在簇,就很容易误采到其他簇的单词。
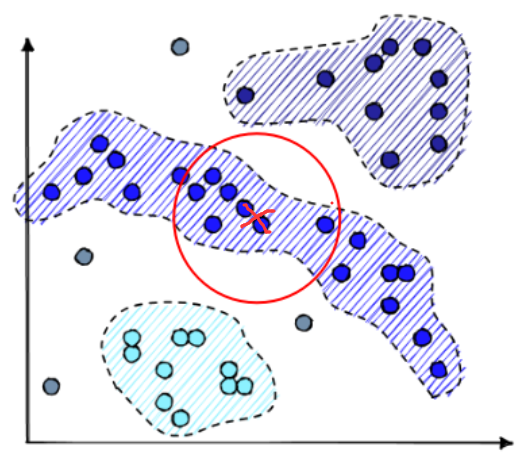
而今天要介绍的这篇 BERTopic, 使用一种基于类别的 TF-IDF 变体,解决了这个问题:聚类和采词之间的不一致不兼容问题(gap)。
论文标题:
BERTopic: Neural topic modeling with a class-based TF-IDF procedure
论文作者:
Maarten Grootendorst
论文链接:
https://arxiv.org/pdf/2203.05794.pdf
原理
BERTopic 方法的步骤如下:
-
首先使用预训练模型计算 document embeddings (比如常用的 Sentence-BERT 等) -
因为 document embeddings 维度很高,在嵌入空间中就非常稀疏,不容易进行聚类,所以需要先进行降维,比如 PCA 或者 t-SNE 等方法,这里用的是 UMAP[4] -
基于 层次和密度进行聚类,这里用的是典型的 HDBSCAN[5] 算法 -
⚡ 划重点:使用 class-based TF-IDF 变体提取每个簇的主题词
因为上文所说的这个 gap 产生的原因,本质上就是“采词空间”没有收束到对应的簇上。所以只要想办法把候选集合定在簇里面就好了!😋
当然可以通过缩小 sphere 来约束,但是这样肯定会漏掉不少候选词...
静态主题建模
静态主题建模假定时间是静止的当下,不考虑文档主题分布随着时间的变化。
回顾一下 TF-IDF 算法 :
式子中,t 代表单词(term), d 代表文档(document), 这个值的意思是 t 在 d 中的词频乘以 log(语料总文档数量 比 包含t的文档的数量)。
BERTopic 使用的是相同的策略,只不过文档 d 做了一些改变:将一个 cluster (也就是一个类 class) 中的所有文档拼接起来作为新的单个文档 d. 这样 TF-IDF 公式就变成了 c-TF-IDF:
其中,c 表示 class, A 表示每个 class 的平均单词数量, 表示 class c 中 t 的频率, 表示所有 class 中 t 的频率。
就这样,簇 c 里的每个单词 t 都有了一个分数,分数越高,越能代表这个簇的主题~ 显然这个候选集合是收束在簇 c 的范围里面的。
动态主题建模
和静态主题建模不同,动态主题建模考虑到了文档本身随时间的变化特征,即2022年的文档和2012年的文档主题分布是不一样的,2022年大家在讨论的主题是“三体”即将上映,而2012年大家讨论的主题是“2012世界末日”.
针对这种情况,本文引入了新的 TF-IDF 公式:
这里的 i 表示第 i 个 timestep.
平滑化
对于动态主题建模另外一个可能有用的假设是,不同 timestep 的 topic 可能是线性相关的,因此作者引入了平滑技巧(optional):
-
首先进行 L1-normalization (即除以 L1-norm), for each topic and timestep. -
然后对 normalized vector 进行 average 平滑操作:将第 i 时刻的值与第 i-1 时刻的值进行一个平均作为新的第 i 时刻的值。
效果
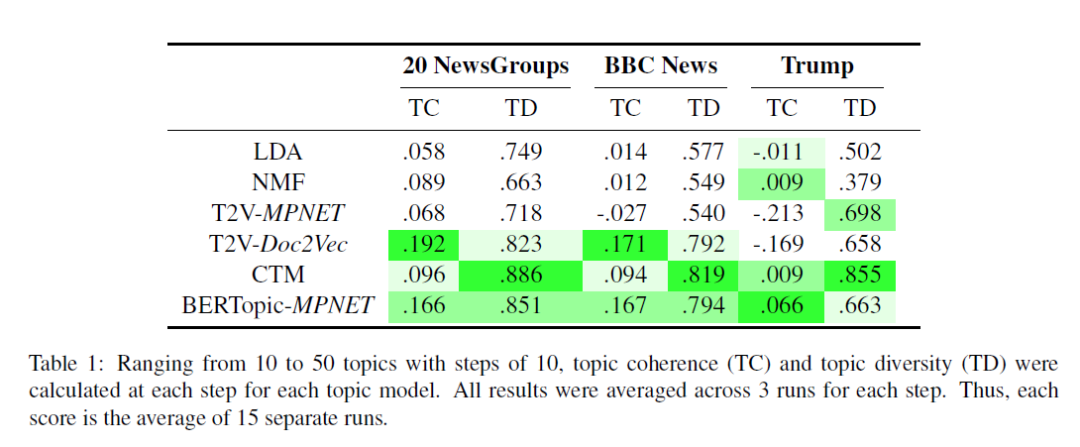
作者使用 "all-mpnetbase-v2" SBERT model 作为 embedding model, 在 20 NewsGroups、BBC News、Trump 等数据集上进行了实验,对比结果如下图:
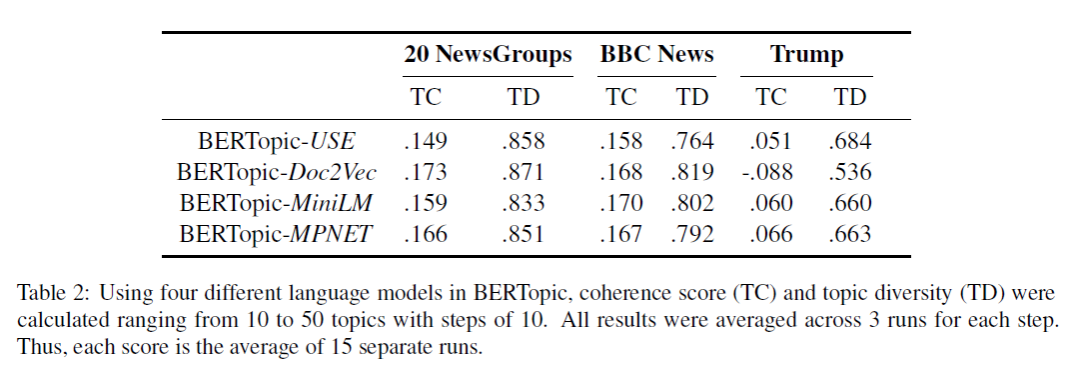
然后不同的 embedding model 对效果也会有影响:
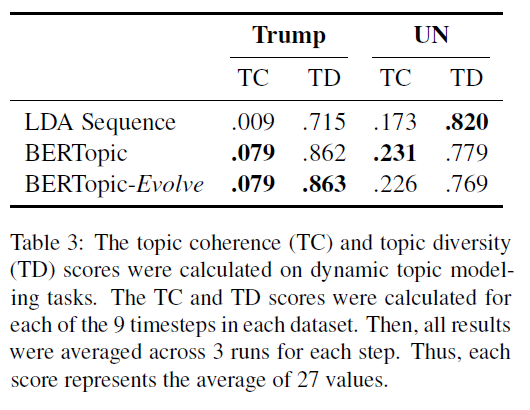
对于动态主题建模,BERTopic 也有很好的综合效果:
总结下来就是:
BERTopic 优点:弥合了基于密度聚类和基于中心采样之间的 gap;适用于各种语言模型,从而可以根据需要与实际资源量灵活选择可用模型;嵌入聚类和主题生成(采词)是解耦的两个阶段;静态、动态主题建模用的是同一套框架, minimal change.
缺点:没有考虑单文档多主题;因为仅仅考虑了文档的上下文表示而主题词仍然来源于词袋,所以主题当中的单词可能高度相似从而具有一定的冗余性。
写在最后
看完这篇文章之后,最大的感觉就是:细心!太细心了!
密度聚类和中心采样之间的 gap, 这个盲点,真的需要一番好眼力才能发现 😂!所以,做科研,不一定必须追快打新,把 picture 定得多么多么大,能敏锐地发现一些别人发现不了的“小”问题,也是不小的成果。
Finally, 贴一段 BERTopic 的使用示例代码:
from bertopic import BERTopic
from sklearn.feature_extraction.text import CountVectorizer
# we add this to remove stopwords
vectorizer_model = CountVectorizer(ngram_range=(1, 2), stop_words="english")
model = BERTopic(
vectorizer_model=vectorizer_model,
language='english', calculate_probabilities=True,
verbose=True
)
topics, probs = model.fit_transform(text)
代码来源于:https://www.pinecone.io/learn/bertopic/
然后去更新你的常备 toolkit 吧~ (😉)
萌屋作者:ZenMoore
智源实习生🧐,爱数学爱物理爱 AI🌸 想从 NLP 出发探索人工认知人工情感的奥秘🧠🤖!个人主页🌎 zenmoore.github.io 知乎🤔 ZenMoore, 微信📩 zen1057398161 嘤其鸣矣,求其友声✨!
作品推荐
 萌屋作者:ZenMoore
萌屋作者:ZenMoore
后台回复关键词【入群】
加入卖萌屋NLP、CV、搜推广与求职讨论群
[1] Dimo Angelov. 2020. Top2vec: Distributed representations of topics. arXiv preprint arXiv:2008.09470.
[2] Federico Bianchi, Silvia Terragni, and Dirk Hovy. 2020a. Pre-training is a hot topic: Contextualized document embeddings improve topic coherence. arXiv preprint arXiv:2004.03974.
[3] Suzanna Sia, Ayush Dalmia, and Sabrina J Mielke. 2020. Tired of topic models? clusters of pretrained word embeddings make for fast and good topics too! arXiv preprint arXiv:2004.14914.
[4] Leland McInnes, John Healy, Nathaniel Saul, and Lukas Grossberger. 2018. Umap: Uniform manifold approximation and projection. The Journal of Open Source Software, 3(29):861.
[5] Leland McInnes, John Healy, and Steve Astels. 2017. hdbscan: Hierarchical density based clustering. The Journal of Open Source Software, 2(11):205.
 后台回复关键词【入群】
后台回复关键词【入群】



