
选自Communications of the ACM
作者:李航
机器之心编译
本文描述了语言模型的发展历史,指出未来可能的发展方向。近年来,自然语言处理 (NLP) 领域发生了革命性的变化。由于预训练语言模型的开发和应用,NLP 在许多应用领域取得了显著的成就。预训练语言模型有两个主要优点。一、它们可以显著提高许多自然语言处理任务的准确性。例如,可以利用 BERT 模型来实现比人类更高的语言理解性能。我们还可以利用 GPT-3 模型生成类似人类写的文章。预训练语言模型的第二个优点是它们是通用的语言处理工具。在传统的自然语言处理中,为了执行机器学习任务,必须标记大量数据来训练模型。相比之下,目前只需要标记少量数据来微调预训练语言模型,因为它已经获得了语言处理所需的大量知识。
本文从计算机科学的发展历史和未来趋势的角度简要介绍语言建模,特别是预训练语言模型,对 NLP 领域的基本概念、直观解释、技术成就和面临的挑战展开了综述,为初学者提供了关于预训练语言模型的参考文献。
自然语言处理是计算机科学(CS)、人工智能(AI)和语言学的一个交叉领域,包括机器翻译、阅读理解、对话系统、文本摘要、文本生成等应用。近年来,深度学习已成为自然语言处理的基础技术。 借助数学知识对人类语言建模主要有两种方法:一种是基于概率,另一种是基于形式语言。这两种方法也可以结合使用。从基本框架的角度看,语言模型属于第一类。语言模型是定义在单词序列(句子或段落)上的概率分布。
本文首先介绍马尔可夫和香农的研究中关于语言建模的基本概念;然后讨论了诺姆 • 乔姆斯基提出的语言模型(基于形式语言理论),描述了神经语言模型的定义及其对传统语言模型的扩展;接下来解释了预训练语言模型的基本思想,讨论了神经语言建模方法的优势和局限性,并对 NLP 的未来进行了展望。
马尔可夫与语言模型
安德烈 · 马尔可夫可能是第一个研究语言模型的科学家。尽管当时还没有「语言模型」这个词。 假设w1, w2, ···, wN是一个单词序列。我们可以按如下公式计算单词序列的概率:
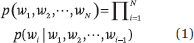
设 p(w1|w0) = p(w1)。 不同类型的语言模型使用不同的方法计算条件概率 p(wi|w1, w2, ···, wi-1)。学习和使用语言模型的过程称为语言建模。
n-gram 模型是一种基本模型,它假设每个位置的单词仅取决于前 n-1 个位置的单词。也就是说,该模型是一个 n–1 阶马尔可夫链。
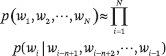
马尔可夫链模型非常简单,只涉及两个状态之间的转移概率。马尔可夫证明,如果根据转移概率在两个状态之间跳跃,则访问两个状态的频率将收敛到期望值,这是马尔可夫链的遍历定理。在接下来的几年里,他扩展了模型,并证明了上述结论在更一般的情况下仍然成立。
为了提供一个具体的例子,马尔可夫将他提出的模型应用于亚历山大 · 普希金 1913 年的诗体小说《尤金 · 奥涅金》。去掉空格和标点符号,将小说的前 20000 个俄语字母分为元音和辅音,他得到了小说中的元音和辅音序列。然后,马尔可夫使用纸和笔计算元音和辅音之间的转换概率。然后,使用数据验证最简单马尔可夫链的特征。非常有趣的是,马尔可夫链的初始应用领域是语言。马尔可夫模型是最简单的语言模型。
香农和语言模型
1948 年,克劳德 · 香农发表了开创性的论文《通信的数学理论》,开创了信息论领域。在该论文中,香农引入了熵和交叉熵的概念,并研究了 n-gram 模型的性质。 熵表示概率分布的不确定性,而交叉熵表示概率分布相对于另一概率分布的不确定性。熵是交叉熵的下限。 假设语言(单词序列)是由随机过程生成的数据。n-gram 的概率分布熵定义如下:
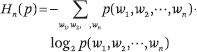
其中 p(w1, w2, ···, wn) 表示 n-gram 中 w1, w2, ···, wn 的概率。n-gram 概率分布相对于数据「真实」概率分布的交叉熵定义如下:
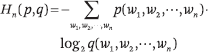
其中q(w1, w2, ···, wn) 表示 n-gram 中w1, w2, ···, wn 的概率,p(w1, w2, ···, wn) 表示 n-gram 中 w1, w2, ···, wn 的真实概率。那么,以下关系成立:
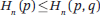
Shannon-McMillan-Breiman 定理指出,当语言的随机过程满足平稳性和遍历性条件时,以下关系成立:
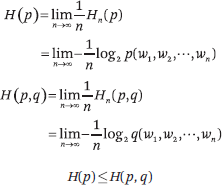
换句话说,当单词序列长度趋于无穷大时,可以定义语言的熵,从语言的数据中估计出熵的常数值。 如果一种语言模型能比另一种语言模型更准确地预测单词序列,那么它应该具有更低的交叉熵。因此,香农的工作为语言建模提供了一个评估工具。 注意,语言模型不仅可以建模自然语言,还可以建模形式和半形式语言,例如 Peng 和 Roth。
乔姆斯基和语言模型
与此同时,诺姆 · 乔姆斯基在 1956 年提出了乔姆斯基语法层次,用于表示语言的语法。他指出,有限状态语法(n-gram 模型)在描述自然语言方面具有局限性。
乔姆斯基的理论认为,一种语言由一组有限或无限的句子组成,每个句子是一系列长度有限的单词,单词来自有限的词汇,语法是一组生成规则,可以生成语言中的所有句子。不同的语法可以产生不同复杂性的语言,其中存在一些层次结构。
能够生成有限状态机可接受句子的语法是有限状态语法或正则语法,而能够生成非确定性下推自动机(PDA)可接受句子的语法是上下文无关语法(CFG),有限状态语法正确地包含在上下文无关语法中。有限马尔可夫链(或 n-gram 模型)背后的「语法」是有限状态语法。有限状态语法在生成英语句子方面确实有局限性。
然而,有限状态语法不能描述所有的语法关系组合,有些句子无法涵盖。因此,乔姆斯基认为,用有限状态语法(包括 n-gram 模型)描述语言有很大的局限性。相反,他指出上下文无关语法可以更有效地建模语言。受他的影响,在接下来的几十年里,上下文无关语法在自然语言处理中更为常用。乔姆斯基的理论目前对自然语言处理影响不大,但仍具有重要的科学价值。
神经语言模型
n-gram 模型的学习能力有限。传统的方法是使用平滑方法从语料库中估计模型中的条件概率 p(wi|wi-n+1, wi-n+2, ···, wi-1) 。然而,模型中的参数数量为指数级O(Vn),其中 V 表示词汇量。当 n 增加时,由于训练数据的稀疏性,无法准确地学习模型的参数。
2001 年,Yoshua Bengio 等人提出了第一个神经语言模型,开启了语言建模的新时代。 Bengio 等人提出的神经语言模型从两个方面改进了 n-gram 模型。首先,实值向量(称为单词嵌入)用于表征单词或单词的组合。
词嵌入作为一种「分布式表征」,可以比 one-hot 向量更有效地表征一个词,具有泛化能力、稳健性和可扩展性。并且,用神经网络表征语言模型,大大减少了模型中的参数数量。条件概率由神经网络确定:
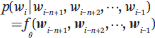
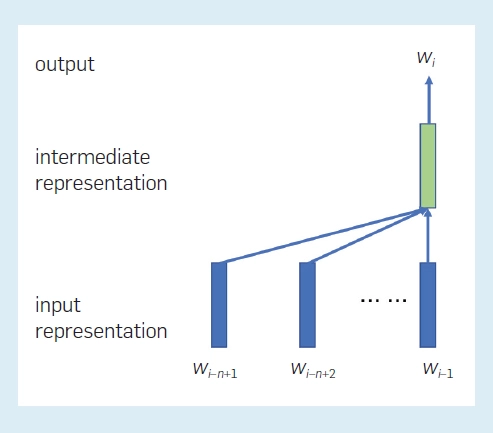
其中(wi-n+1, wi-n+2, ···, wi-1) 表示单词 wi-n+1, wi-n+2, ···, wi-1 的嵌入;f(·) 表示神经网络;ϑ 表示网络参数。模型中的参数数量仅为 O(V)。图 1 显示了模型中表征之间的关系。每个位置都有一个中间表征,它取决于前 n–1 个位置处的词嵌入(单词),这适用于所有位置。然后,使用当前位置的中间表征为该位置生成一个单词。
在 Bengio 等人的工作之后,研究人员开发了大量的词嵌入方法和神经语言建模方法,从不同角度进行了改进。几个有代表性的方法包括:文字嵌入方法 Word2Vec、递归神经网络(RNN)语言模型,包括长短期记忆(LSTM)网络。在 RNN 语言模型中,每个位置的条件概率由 RNN 确定:
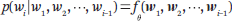
其中w1, w2, ···, wi-1 表示单词w1, w2, ···, wi-1的嵌入;f(·) 表示 RNN;ϑ 表示网络参数。RNN 语言模型不再使用马尔可夫假设,每个位置的词取决于之前所有位置的词。RNN 中的一个重要概念是其中间表征或状态。在 RNN 模型中,词之间的依赖关系以状态之间的依赖关系为特征。模型的参数被不同位置共享,但在不同位置获得的表征不同。
下图 2 显示了 RNN 语言模型中表征之间的关系。到目前为止,每个位置的每一层都有一个中间表征,表示单词序列的「状态」。当前层在当前位置的中间表征由同一层在前一位置的中间表征和下面层在当前位置的中间表征确定。当前位置的最终中间表征用于计算下一个单词的概率。
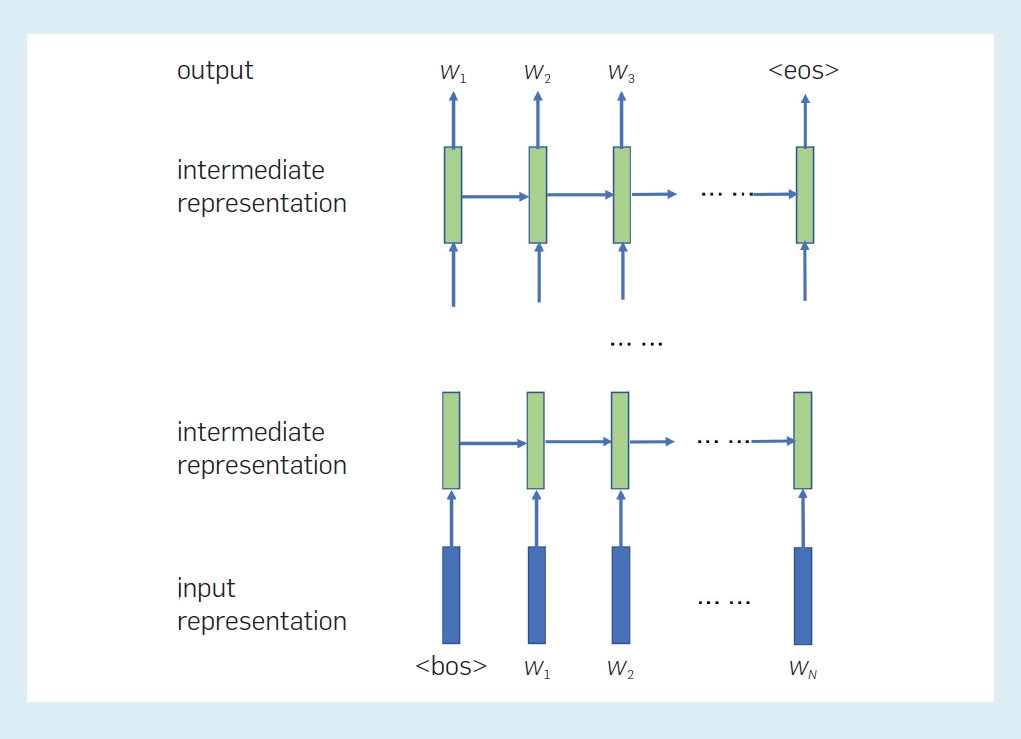
语言模型可用于计算语言(词序列)的概率或生成语言。后一种情况通过从语言模型中随机采样来生成自然语言句子或文章。众所周知,从大量数据中学习的 LSTM 语言模型可以生成非常自然的句子。 语言模型的扩展是条件语言模型,它计算给定条件下单词序列的条件概率。如果条件是另一个词序列,则问题变成从一个词序列到另一个词序列的转换,即所谓的序列到序列问题。机器翻译 、文本摘要和生成对话都是这样的任务。如果给定的条件是图片,那么问题就变成了从图片到文字序列的转换。图像字幕就是这样一项任务。
条件语言模型可用于多种应用。在机器翻译中,系统将一种语言的句子转换为另一种语言的句子,具有相同的语义。在对话生成中,系统生成对用户话语的响应,两条消息形成一轮对话。在文本摘要中,系统将长文本转换为短文本,使后者代表前者的要点。模型的条件概率分布表示的语义因应用程序而异,并从应用程序的数据中学习。
序列到序列模型的研究有助于新技术的发展。典型的序列到序列模型是 Vaswani 等人开发的 transformer。transformer 完全基于注意力机制。并利用注意力在编码器和解码器之间进行编码、解码和信息交换。目前,几乎所有的机器翻译系统都采用 transformer 模型,机器翻译已经达到了几乎可以满足实际需要的水平。由于 transformer 在语言表示方面的强大功能,它的体系结构现在几乎被所有预训练语言模型所采用。
预训练语言模型
基于 transformer 编码器或解码器的语言模型分两个阶段进行学习:预训练,通过无监督学习(也称为自监督学习)使用非常大的语料库训练模型参数;微调,将经过预训练的模型应用于特定任务,并通过监督学习使用少量标记数据进一步调整模型参数。下表 1 中的链接提供了学习和使用预训练语言模型的资源。

有三种类型的预训练语言模型:单向、双向和序列到序列。由于篇幅限制,本文仅涵盖前两种类型。所有主要的预训练语言模型都采用 transformer 的架构。表 2 提供了现有预训练语言模型的简介。

Transformer 具有很强的语言表征能力,大型语料库包含丰富的语言表达(这样的未标记数据很容易获得),使得训练大规模深度学习模型变得更加高效。因此,预训练语言模型可以有效地表示语言的词汇、句法和语义特征。预训练语言模型,如 BERT 和 GPT(GPT-1、GPT-2 和 GPT-3),已成为当前 NLP 的核心技术。
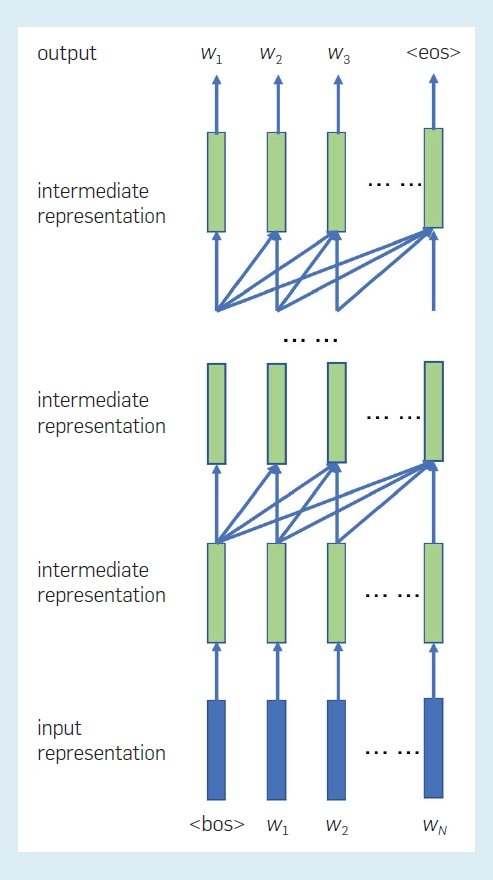
预训练语言模型的流行,为自然语言处理带来了巨大的成功。BERT 在语言理解任务(如阅读理解)的准确性方面优于人类。GPT-3 在文本生成任务中也达到了惊人的流利程度。请注意,这些结果仅表明机器在这些任务中具有非常高的性能,而不应简单地解释 BERT 和 GPT-3 能比人类更好地理解语言,因为这也取决于如何进行基准测试。正确理解和期望人工智能技术的能力对于该领域的发展至关重要。 Radford 和 Brown 等人开发的 GPT 具有以下架构。输入是一系列单词w1, w2, ···, wN。首先,通过输入层创建一系列输入表征,表示为矩阵H(0)。
再通过 L transformer 解码器层后创建一系列中间表征,表示为矩阵H(L)
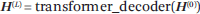
最后,根据每个位置的最终中间表征,计算每个位置的单词概率分布。GPT 的预训练与传统的语言建模相同,目的是预测单词序列的可能性。对于给定的词序列w = w1, w2, ···, wN,我们计算并最小化交叉熵或负对数似然来估计参数:
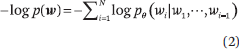
图 3 显示了 GPTs 模型中表征之间的关系。每个位置的输入表征由单词嵌入和「位置嵌入」组成每个位置处每个层的中间表征是根据之前位置处下方层的中间表征创建的。从左到右在每个位置重复执行单词的预测或生成。换句话说,GPT 是一种单向语言模型,其中单词序列从一个方向建模。(请注意,RNN 语言模型也是单向语言模型。)因此,GPTs 更适合解决自动生成句子的语言生成问题。
BERT,由 Devlin 等人开发。它的输入是一个单词序列,可以是单个文档中的连续句子,也可以是两个文档中连续句子的串联。这使得该模型适用于以一个文本作为输入的任务(如文本分类),以及以两个文本作为输入的任务(如回答问题)。该模型首先通过输入层创建一系列输入表征,表示为矩阵H(0)。通过L transformer编码器层创建一系列中间表征,表示为H(L)。

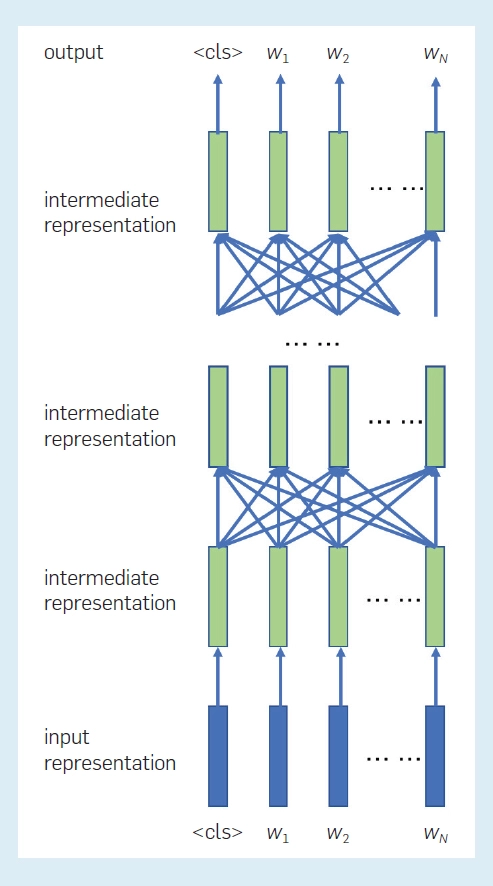
最后,可以根据每个位置的最终中间表征,计算每个位置的单词概率分布。BERT 的预训练作为所谓的 mask 语言建模进行。假设单词序列是 w = w_1, w_2, ···, w_N。序列中的几个词被随机 mask,即更改为特殊符号——产生新的词序列。学习的目标是通过计算并最小化以下负对数似然来估计参数,从而恢复「mask 词」:
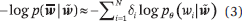
其中ϑ 表示BERT模型的参数,δi 取1或0,表示位置 i 处的单词是否被 mask。请注意,mask 语言建模已经是一种不同于传统语言建模的技术。
图 4 显示了 BERT 模型中表征之间的关系。每个位置的输入表征由单词嵌入、位置嵌入等组成。每个位置的每个层的中间表征是从下面所有位置的层的中间表征创建的。字的预测或生成在每个 mask 位置独立执行。也就是说,BERT 是一种双向语言模型,其中单词序列从两个方向建模。因此,BERT 可以自然地应用于语言理解问题,这些问题的输入是一个完整的单词序列,输出通常是一个标签或标签序列。
对预练语言模型的直观解释是,计算机在预训练中基于大型语料库进行了大量的单词接龙(GPT)或单词完形填空(BERT)练习,从单词中捕获各种构词模式,然后从句子中构词,并表达和记忆模型中的模式。文本不是由单词和句子随机创建的,而是基于词汇、句法和语义规则构建的。GPT 和 BERT 可以分别使用 transformer 的解码器和编码器来实现语言的组合性。(组合性是语言最基本的特征,也是由乔姆斯基层次结构中的语法建模的。)换句话说,GPT 和 BERT 在预训练中获得了大量的词汇、句法和语义知识。因此,当适应特定任务时,可以仅使用少量标记数据来微调模型,以实现高性能。例如,BERT 的不同层具有不同的特征。底层主要代表词汇知识,中间层主要代表句法知识,顶层主要代表语义知识。 预训练语言模型,如 BERT 和 GPT-3,包含大量事实知识。例如,它们可以用来回答诸如「但丁出生在哪里?」只要他们从训练数据中获得了知识,就可以进行简单的推理,例如「48 加 76 等于多少?」 然而,语言模型本身没有推理机制。他们的「推理」能力是基于联想而不是真正的逻辑推理。因此,他们在需要复杂推理的问题如论点推理、数值推理和话语推理等方面并没有很好的表现。将推理能力和语言能力集成到自然语言处理系统中将是未来的一个重要课题。
未来展望
当代科学(脑科学和认知科学)对人类语言处理机制(语言理解和语言生成)的理解有限。在可预见的未来,很难看到出现重大突破,永远不突破的可能性也存在。另一方面,我们希望不断推动人工智能技术的发展,开发对人类有用的语言处理机器。
神经语言建模似乎是迄今为止最成功的方法。语言建模的基本特征没有改变,即它依赖于在包含所有单词序列的离散空间中定义的概率分布。学习过程是找到最优模型,以便根据交叉熵预测语言数据的准确性最高(见图 5)。神经语言建模通过神经网络构建模型。其优点是,通过利用复杂的模型、大数据和强大的计算能力,它可以非常准确地模拟人类的语言行为。从 Bengio 等人提出的原始模型到 RNN 语言模型和预训练语言模型,如 GPT 和 BERT,神经网络的架构变得越来越复杂(参见图 1, 2 ,3 ,4 ),而预测语言的能力越来越高(交叉熵越来越小)。然而,这并不一定意味着这些模型具有与人类相同的语言能力,这种方法的局限性也是不言而喻的。
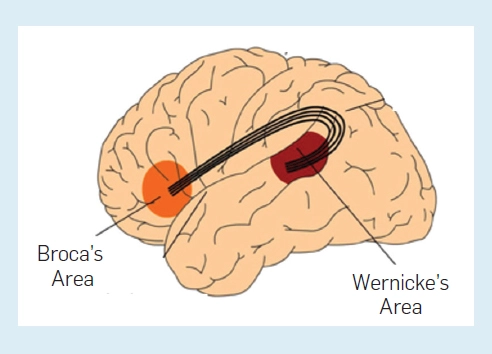
还有其他可能的发展途径吗?目前尚不清楚。可以预见,神经语言建模方法仍有许多可改进的方面。当前的神经语言模型与人脑在表示能力和计算效率(在功耗方面)方面仍有很大差距。成年人的大脑处理语言问题只需要 12 瓦功耗与之形成鲜明对比的是,根据作者的说法,训练 GPT-3 模型已经消耗了数千万亿次浮点计算。能否开发出更接近人类语言处理的更好的语言模型是未来研究的一个重要方向。技术改进仍有很多机会。我们仍然可以从脑科学的有限发现中继续探索。 人们认为,人类语言处理主要在大脑皮层的两个大脑区域进行:布罗卡区和韦尼克区(图 6)。前者负责语法,后者负责词汇。有两种典型的由脑损伤引起的失语症。布罗卡区受伤的患者只能用零星的单词而不是句子说话,而韦尼克区受伤的患者可以构造语法正确的句子,但单词往往缺乏意义。一个自然的假设是,人类的语言处理是在两个大脑区域并行进行的。是否有必要采用更人性化的处理机制是一个值得研究的课题。语言模型不明确使用语法,也不能无限组合语言,这是乔姆斯基指出的人类语言的一个重要属性。将语法更直接地纳入语言模型的能力将是一个需要研究的问题。
脑科学家认为,人类语言理解是一个在潜意识中激活相关概念表达并在意识中生成相关图像的过程。表征包括视觉、听觉、触觉、嗅觉和味觉表征。它们是视觉、听觉、触觉、嗅觉和味觉等概念的内容,这些概念通过一个人在成长和发展过程中的经历在大脑的各个部分被记住。因此,语言理解与人们的经验密切相关。生活中的基本概念,如猫和狗,是通过视觉、听觉、触觉等传感器的输入来学习的。听到或看到单词 “猫” 和“狗”也会激活人们大脑中相关的视觉、听觉和触觉表征。机器能否从大量多模式数据(语言、视觉、语音)中学习更好的模型,以便能够更智能地处理语言、视觉和语音?多模态语言模型将是未来探索的一个重要课题。 结论
语言模型的历史可以追溯到 100 多年前。马尔可夫、香农和其他人无法预见他们研究的模型和理论会在以后产生如此大的影响;这对 Bengio 来说甚至可能出乎意料。未来 100 年,语言模型将如何发展?它们仍然是人工智能技术的重要组成部分吗?这超出了我们的想象和预测。我们可以看到,语言建模技术在不断发展。在未来几年,很可能会有更强大的模型取代 BERT 和 GPT。对我们来说,我们有幸成为第一代看到技术巨大成就并参与研发的人。 原文链接:https://cacm.acm.org/magazines/2022/7/262080-language-models/fulltext
