赛尔原创 | COLING 2018 面向任务型对话中基于对话状态表示的序列到序列学习
本文介绍哈尔滨工业大学社会计算与信息检索研究中心(SCIR)录用于COLING 2018的论文《Sequence-to-Sequence Learning for Task-oriented Dialogue System with Dialogue State Representation》中的工作。在面向任务型对话中,传统流水线模型要求对对话状态进行显式建模。这需要人工定义对领域相关的知识库进行检索的动作空间。相反地,序列到序列模型可以直接学习从对话历史到当前轮回复的一个映射,但其没有显式地进行知识库的检索。在本文中,我们提出了一个结合传统流水线与序列到序列二者优点的模型。我们的模型将对话历史建模为一组固定大小的分布式表示。基于这组表示,我们利用注意力机制对知识库进行检索。 在斯坦福多轮多领域对话数据集上的实验证明,我们的模型在自动评价与人工评价上优于其他基于序列到序列的模型。
论文作者:文灏洋,刘一佳,车万翔,覃立波,刘挺
面向任务型对话主要是通过用户与机器之间的交互来完成用户指定的某项任务,比如预定机票、查询天气等。在试图解决任务型对话问题的过程中,出现过两大类方法。第一大类方法将问题建模为POMDP问题[Young et al., 2013],利用由语言理解、对话状态跟踪、策略学习和语言生成的流水线来完成对话。这类方法显式地建模了对话状态和策略,意味着其需要不同的领域相关的标注数据来完成对某个特定域的面向任务型对话的学习。第二大类方法利用Seq2Seq模型[Eric and Manning, 2017; Eric et al., 2017],序列到序列地完成学习。这类方式改变了流水线模型需要对不同组成部分进行训练的过程,只需对话历史就可以完成训练。然而由于其缺乏对对话状态的表示,同时难以完成对外部数据的检索,其难以生成信息精准的回复。
本文着眼于Seq2Seq模型,通过尝试解决上述提出的对话状态表示和对外部数据检索的问题来提升对话模型的性能。我们将对话历史表示为一组分布式表示[Britz et al, 2017]来对对话状态进行表示,然后通过计算这组表示与外部知识库(Knowledge Base, KB)中每一个条目的相似度完成对条目的检索,解码时通过生成属性标签来完成对需要生成的属性进行检索。
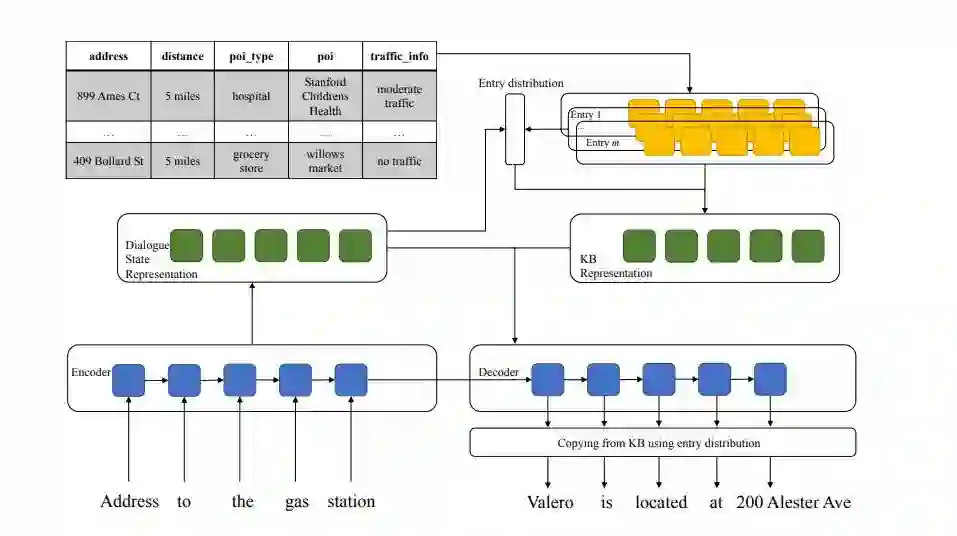
图1 方法的总体流程
首先我们利用LSTM来编码整体的对话历史信息,然后利用对话状态表示来获取一组分布式表示。同时,我们完成了对知识库中每一个单元的表示。我们将这两部分信息进行整合,即利用历史得到的一组表示来检索知识库中的条目。输出时我们通过输出属性标签来完成列的检索,最后将条目和属性的信息进行整合,完成对KB的拷贝。下面我们来介绍模型的一些关键模块:
不同于流水线模型中的对话状态跟踪,将对话状态表示为每一个槽(slot)中所有可能的值(value)的概率分布,我们将对话状态表示为对每一个槽的分布式表示。假设有不同的槽,对于编码器的所有隐层 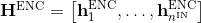
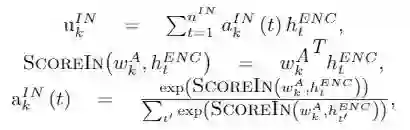
我们可以将知识库每个单元的词向量与其属性标签词向量相拼接,通过线性层来完成对每个单元的表示。可以看到,这样一来,每一个条目的向量个数与对话状态表示中的向量个数是一一对应的。我们将对话状态与一个条目的相似度定义为对应向量的点积之和,即:
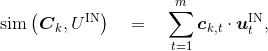
将其归一化,即可得到下文生成中需要使用某个条目的概率:

进而,我们可以利用概率得到在给定对话历史下的KB的表示:
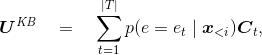
将该表示与对话状态表示相拼接可以得到最后的综合表示。
解码时,除了传统对输入的注意力机制,我们还可以在综合表示上做额外的注意力机制。此外,还引入了拷贝机制。我们通过在词表中加入属性标签,利用生成属性标签的概率和之前得到的使用某个条目的概率综合起来,完成对KB中每个单元的拷贝:
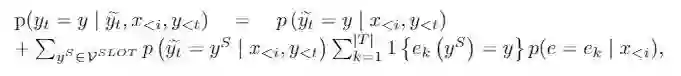
除了传统的负对数似然外,我们还引入了强化学习用来加强对条目检索的训练。强化学习的动作为选择某一个条目,而奖励被定义为该条目中实体出现在对话历史与当前标准回复中的个数。
我们选取了斯坦福多领域多轮面向任务型对话中KB比较完整的两个领域。我们选取了Seq2Seq、CopyNet、KVnet三个典型的模型进行比较,由于实验设置的不同,我们对上述模型都进行了调整,以便进行一致的比较。模型在两个领域上分别进行了训练,其结果如下所示:表1 模型对比结果

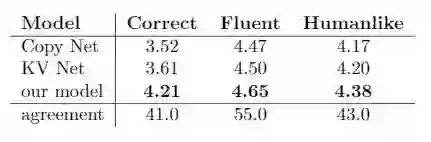
我们还进行了人工评价,主要用于衡量生成回复的自然程度、准确程度、和与人类回复的相似程度:表2 模型的人工评价结果
我们对生成对话状态表示的注意力机制做了可视化,如下图所示。可以看出,历史中相关实体较为成功地匹配到了相关的属性的表示上:
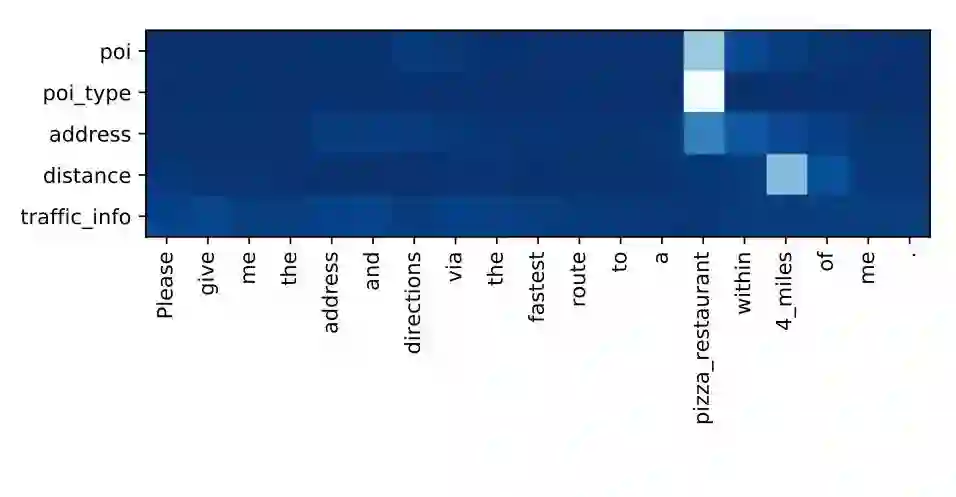
图2 对话状态表示的可视化
最后我们给出了模型与Seq2Seq在一个案例下的对比:
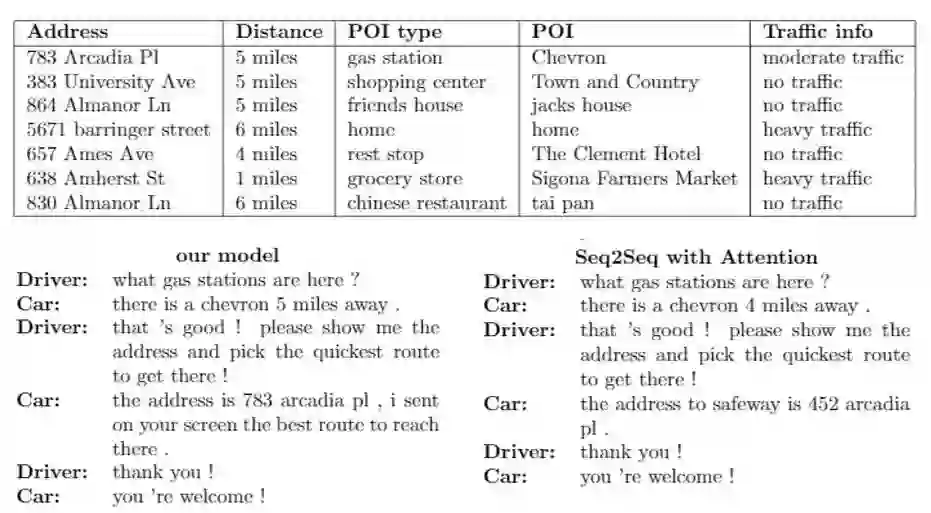
图3 案例分析。 左边的对话是从我们的框架生成的,而右边的对话是从带有注意基线的Seq2Seq生成的
通过上述模型与实验,我们探索了如何在Seq2Seq模型中引入对话状态与外部知识库检索。我们利用了基于注意力机制的方式来完成上述需求。通过在斯坦福多任务多轮面向任务型对话数据集上的实验,我们发现我们的模型较之基线模型相比带来了明显的提升。
Steve Young, Milica Gasic, Blaise Thomson, and Jason D Williams. 2013. Pomdp-based statistical spoken dialog systems: A review. Proceedings of the IEEE, 101(5):1160–1179.
Mihail Eric, Lakshmi Krishnan, Francois Charette, and Christopher D Manning. 2017. Key-value retrieval networks for task-oriented dialogue. In Proceedings of the 18th Annual SIGDial Meeting on Discourse and Dialogue, pages 37–49.
Mihail Eric and Christopher Manning. 2017. A copy-augmented sequence-to-sequence architecture gives good performance on task-oriented dialogue. In Proceedings of the 15th Conference of the European Chapter of the Association for Computational Linguistics: (Volume 2, Short Papers), volume 2, pages 468–473.
Denny Britz, Melody Guan, and Minh-Thang Luong. 2017. Efficient attention using a fixed-size memory representation. In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pages 392–400.
往期COLING推送:
赛尔原创 | COLING 2018 对话语义理解的序列到序列数据增强
赛尔原创 | COLING 2018 基于目标依赖财经文档表示学习的累积超额收益预测
赛尔原创 | COLING 2018 中文零指代消解:基于注意力机制的模型
点击文末“阅读原文”查看往期精彩原创推送。
本期责任编辑:赵森栋
本期编辑: 赖勇魁
“哈工大SCIR”公众号
主编:车万翔
副主编: 张伟男,丁效
责任编辑: 张伟男,丁效,赵森栋,刘一佳
编辑: 李家琦,吴洋,刘元兴,蔡碧波,孙卓,赖勇魁
长按下图并点击 “识别图中二维码”,即可关注哈尔滨工业大学社会计算与信息检索研究中心微信公共号:”哈工大SCIR” 。





