Yoshua Bengio 3篇强化学习论文学习disentangling 特征
Disentangling the independently controllable factors of variation by interacting with the world
https://arxiv.org/abs/1802.09484
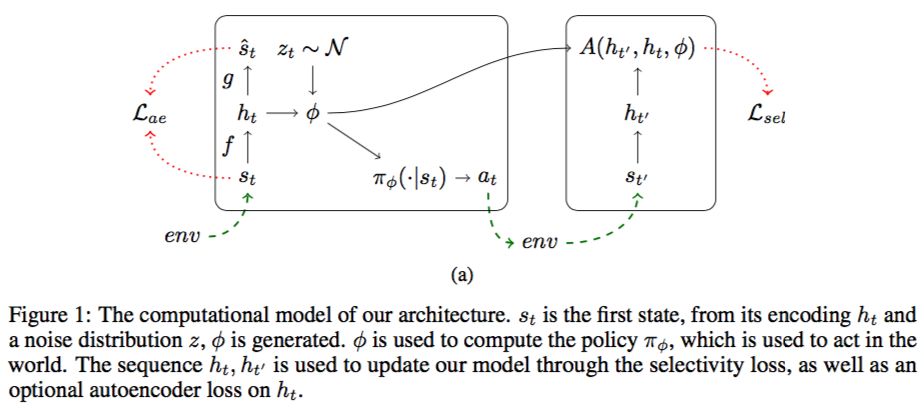
It has been postulated that a good representation is one that disentangles the under- lying explanatory factors of variation. However, it remains an open question what kind of training framework could potentially achieve that. Whereas most previous work focuses on the static setting (e.g., with images), we postulate that some of the causal factors could be discovered if the learner is allowed to interact with its environment. The agent can experiment with different actions and observe their effects. More specifically, we hypothesize that some of these factors correspond to aspects of the environment which are independently controllable, i.e., that there exists a policy and a learnable feature for each such aspect of the environment, such that this policy can yield changes in that feature with minimal changes to other features that explain the statistical variations in the observed data. We propose a specific objective function to find such factors, and verify experimentally that it can indeed disentangle independently controllable aspects of the environment without any extrinsic reward signal. 确实能够在没有任何外部奖励信号的情况下,解开环境中可独立控制的方面。
mechanism for representation learning that has close ties to intrinsic motivation mechanisms and causality.(内部驱动,类似好奇心?,因果关系) This mechanism explicitly links the agent’s control over its environment to the representation of the environment that is learned by the agent
can push a model to learn to disentangle its input in a meaningful way, and learn to represent factors which take multiple actions to change and show that these representations make it possible to perform model-based predictions in the learned latent space, rather than in a low-level input space (e.g. pixels).
We hypothesize that interactions can be the key to learning how to disentangle the various causal factors of the stream of observations that an agent is faced with, and that such learning can be done in an unsupervised way.
https://arxiv.org/abs/1708.01289
Independently Controllable Factors
Abstract
It has been postulated that a good representation is one that disentangles the underlying explanatory factors of variation. However, it remains an open question what kind of training framework could potentially achieve that. Whereas most previous work focuses on the static setting (e.g., with images), we postulate that some of the causal factors could be discovered if the learner is allowed to interact with its environment. The agent can experiment with different actions and observe their effects. More specifically, we hypothesize that some of these factors correspond to aspects of the environment which are independently controllable, i.e., that there exists a policy and a learnable feature for each such aspect of the environment, such that this policy can yield changes in that feature with minimal changes to other features that explain the statistical variations in the observed data. We propose a specific objective function to find such factors and verify experimentally that it can indeed disentangle independently controllable aspects of the environment without any extrinsic reward signal.
Specifically, we hypothesize that some of the factors explaining variations in the data correspond to aspects of the world that can be controlled by the agent. For example, an object that could be pushed around or picked up independently of others is an independently controllable aspect of the environment. Our approach therefore aims to jointly discover a set of features (functions of the environment state) and policies (which change the state) such that each policy controls the associated feature while leaving the other features unchanged as much as possible. In §2 and §3 we explain this mechanism and show experimental results for the simplest instantiation of this new principle. In §5 we discuss how this principle could be applied more generally, and what are the research challenges that emerge.
https://arxiv.org/abs/1804.06955
Disentangling Controllable and Uncontrollable Factors of Variation by Interacting with the World
Abstract
We introduce a method for disentangling independently controllable and uncon- trollable factors of variation by interacting with the world. Disentanglement leads to good representations and it is important when applying deep neural networks (DNNs) in fields where explanations are necessary. This article focuses on rein- forcement learning (RL) approach for disentangling factors of variation, however, previous methods lacks a mechanism for representing uncontrollable obstacles. To tackle this problem, we train two DNNs simultaneously: one that represents the controllable object and another that represents the uncontrollable obstacles. During training, we used the parameters from a previous RL-based model as our initial parameters to improve stability. We also conduct simple toy simulations to show that our model can indeed disentangle controllable and uncontrollable factors of variation and that it is effective for a task involving the acquisition of extrinsic rewards.
ref : 智能的几点随想 观点和 Yoshua Bengio 的观点基本一致。