太惊艳!用GAN生成新海诚、宫崎骏动漫风格图像
点击上方“CVer”,选择加"星标"置顶
重磅干货,第一时间送达

鱼羊 发自 凹非寺
本文转载自:量子位(QbitAI)

这样的东京街景,是不是有点日系纪实动漫那种feel了?
现在,不需要人类画师一帧帧描画,把你拍下的视频喂给AI,就能让现实世界分分钟掉进二次元世界。
布景:

美食:

甚至复仇者联盟,也能瞬间打破电影宇宙和漫画宇宙的界限。

这项研究名为White-box-Cartoonization,来自字节跳动、东京大学和Style2Paints研究所。
论文已收录于CVPR 2020。
白盒卡通表示
如此AI「魔法」的关键,还是生成对抗网络(GAN)。
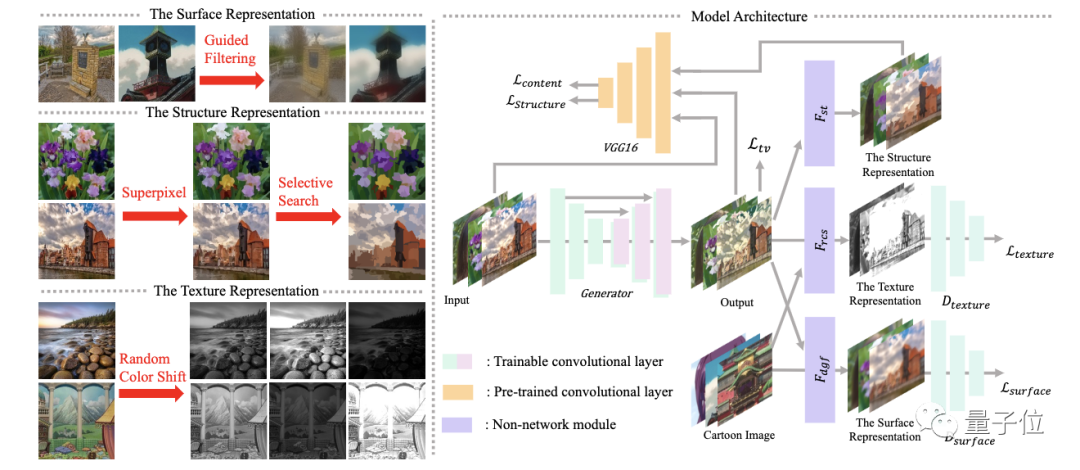
并且,研究人员提出了三个白盒表示方法,分别用来表示平滑表面、结构和纹理。
表面表示:表示动漫图像的光滑表面。
使用导向滤波器对图像进行处理,在保持图像边缘的同时平滑图像,去除图像的纹理和细节信息。
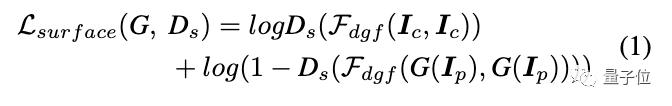
结构表示:获取全局结构信息和稀疏色块。
首先使用felzenszwalb算法将图像分割成不同的区域。
由于超像素算法只考虑像素的相似性而忽略语义信息,研究人员进一步引入选择性搜索来合并分割区域,提取稀疏分割图。

另外,标准的超像素算法会使全局对比度降低,导致图像变暗。
为此,研究人员提出了一种自适应着色算法,以增强图像对比度,减少朦胧效果。
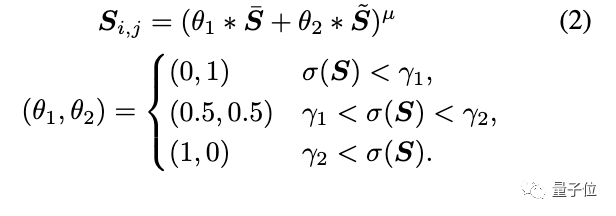
然后,用预训练的VGG16网络提取生成器生成的图像和抽取的结构表示的高级特征,限制空间结构。
纹理表示:反映卡通图像中的高频纹理、轮廓和细节。
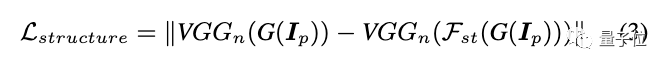
研究人员提出了一种从色彩图像中提取单通道纹理表示的随机颜色偏移算法,以保留高频纹理,减少色彩和亮度的影响。
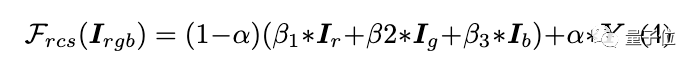
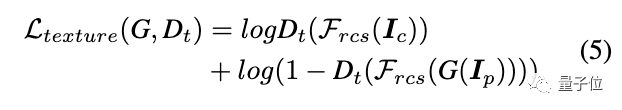
整个GAN框架带有一个生成器G,以及两个判别器Ds和Dt。其中Ds旨在区分模型输出的表面表示和真正的动漫图像。Dt用于区分模型输出的纹理表示和真正的动漫图像。
具体而言,生成器网络是一个类似U-Net的全卷积网络。
研究人员使用 stride=2 的卷积层进行下采样,以双线性插值层作为上采样,以避免棋盘式伪影。
该网络只由3种层组成:卷积层、Leaky ReLU(LReLU)和双线性调整层。这使得该网络能轻松嵌入到手机等边缘设备中。
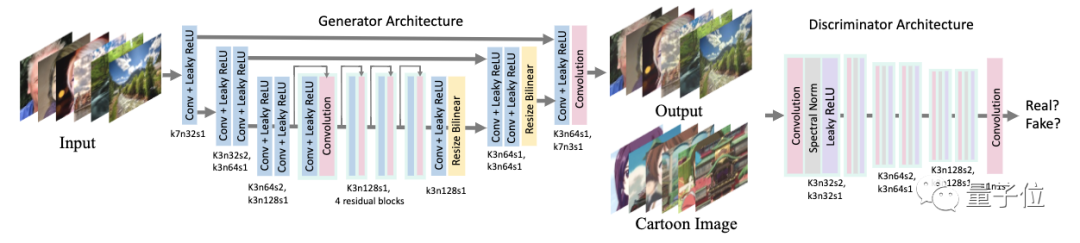
判别器网络则基于PatchGAN进行了调整,其最后一层为卷积层。
输出特征图中的每个像素对应输入图像中的一个图像块(patch),用于判断图像块属于真正的动漫图像还是生成图像。
训练数据集方面,风景图像采集自新海诚、宫崎骏和细田守的动漫作品,人像图像则来自京都动画和PA Works。影片都被剪辑成帧并随机剪裁,大小为256×256。
实验结果
所以,这种图像卡通化方法的效果究竟如何。
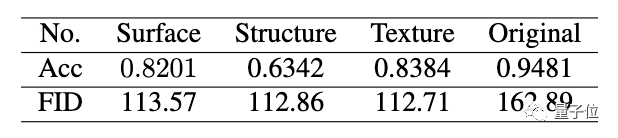
在定量实验中,研究人员发现,AI提取的表示成功愚弄了训练好的分类器。
与原始图像相比,分类器在三个提取的卡通表示中准确率都比较低。
另外,计算出的FID指标也显示,卡通表征有助于缩小真实世界照片和卡通图像之间的差距。
再来看一组直观的对比。

△(f)-(g)为CartoonGAN
与之前的方法相比,白盒框架能生成更为清晰的边界轮廓,并有助于保持色彩的和谐。
比如,图中(f)-(g)所展示的CartoonGAN的某些风格就存在色彩失真的问题,而白盒框架色彩更为自然。
另外,白盒框架也有效地减少了伪影,效果超越CartoonGAN。
网友:惊艳
如此效果,让不少网友大呼「惊艳」,在reddit上达到了500+的热度。
有网友表示,有了这样的黑科技,未来,或许只需要一个创意,就能打造一部好作品。市场的准入门槛将因此而降低。

也有网友认为,颜艺、卖萌这类现实中不存在的画面,还是要靠动漫制作人员的创作。不过,这样的AI将来无疑能减轻动漫制作人员的工作量。
现在,研究人员还放出了在线Demo,如果你感兴趣,可以亲自上手试试~

最后,左边出自人类的画笔,右边是AI的大作,你pick哪一个?



传送门
GitHub地址:
https://github.com/SystemErrorWang/White-box-Cartoonization
在线Demo:
https://cartoonize-lkqov62dia-de.a.run.app/cartoonize
推荐阅读
下载1
在CVer公众号后台回复:PRML,即可下载758页《模式识别和机器学习》PRML电子书和源码。该书是机器学习领域中的第一本教科书,全面涵盖了该领域重要的知识点。本书适用于机器学习、计算机视觉、自然语言处理、统计学、计算机科学、信号处理等方向。

PRML
下载2
在CVer公众号后台回复:CVPR2020,即可下载CVPR2020 2020代码开源的论文合集
在CVer公众号后台回复:ECCV2020,即可下载ECCV 2020代码开源的论文合集
重磅!CVer-GAN交流群成立
扫码添加CVer助手,可申请加入CVer-GAN 微信交流群,目前已满900人,欢迎交流学习。
同时也可申请加入CVer大群和细分方向技术群,细分方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch和TensorFlow等群。
一定要备注:研究方向+地点+学校/公司+昵称(如GAN+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群

▲长按加微信群

▲长按关注CVer公众号
整理不易,请给CVer点赞和在看!




