堪比Focal Loss!解决目标检测中样本不平衡的无采样方法
加入极市专业CV交流群,与6000+来自腾讯,华为,百度,北大,清华,中科院等名企名校视觉开发者互动交流!更有机会与 李开复老师等大牛群内互动! 同时提供每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流。关注 极市平台 公众号 ,回复 加群,立刻申请入群~
1 概述

2 从RetinaNet和Focal loss说起

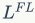 表示focal loss,而
表示focal loss,而
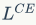 表示普通交叉熵。
表示普通交叉熵。
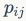 表示的是对第
表示的是对第
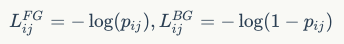

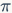 ,具体实施是改变分类分支的bias初始化值,对bias设置如下:
,具体实施是改变分类分支的bias初始化值,对bias设置如下:
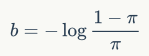 为0.01,那么初始化后的分类分支sigmod处理后的预测概率倾向于0.01,而不是0.5,这会大大减少负样本的初始loss。如图2b所示,但是依然还是出现了梯度爆炸,将分类loss除以500后可以避免,最终的AP值为17.9,从曲线上loss还是有一个突变,说明模型还是陷入负样本中。进一步地调整,当设置为1e-5时,并且分类loss除以10,发现模型可以较好地收敛,最终的AP为35.6,基本达到RetinaNet-FL的效果(AP为36.4)。再进一步地降低为1e-10,发现模型效果反而有稍微下降,AP值为33.8。另外,作者发现RetinaNet-None预测的概率平均值是远远低于RetinaNet-FL,为了提升召回,可以设置较低的阈值,若将阈值从0.05降低至0.005,AP值从35.6提升到36.2,而这对RetinaNet-FL无影响。
为0.01,那么初始化后的分类分支sigmod处理后的预测概率倾向于0.01,而不是0.5,这会大大减少负样本的初始loss。如图2b所示,但是依然还是出现了梯度爆炸,将分类loss除以500后可以避免,最终的AP值为17.9,从曲线上loss还是有一个突变,说明模型还是陷入负样本中。进一步地调整,当设置为1e-5时,并且分类loss除以10,发现模型可以较好地收敛,最终的AP为35.6,基本达到RetinaNet-FL的效果(AP为36.4)。再进一步地降低为1e-10,发现模型效果反而有稍微下降,AP值为33.8。另外,作者发现RetinaNet-None预测的概率平均值是远远低于RetinaNet-FL,为了提升召回,可以设置较低的阈值,若将阈值从0.05降低至0.005,AP值从35.6提升到36.2,而这对RetinaNet-FL无影响。
3 最优bias初始化
如何确定。假定数据集中共有
C个类别,样本量为N,其中正例为
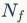 。模型刚开始对所有样本的预测概率值
是接近的,那么分类loss就可以大致估算出来:
。模型刚开始对所有样本的预测概率值
是接近的,那么分类loss就可以大致估算出来:
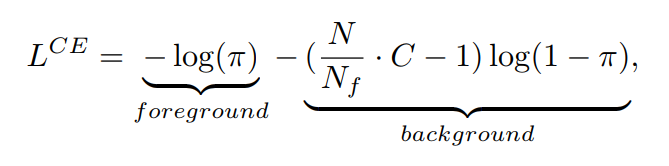
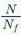 大约为1000。给定一系列值
,我们可以计算出正负例的分类loss,如下表所示:
大约为1000。给定一系列值
,我们可以计算出正负例的分类loss,如下表所示:
 取1e-5时,模型效果最好。从表中我们可以看到,此时的整体loss是最小,这大大降低了训练初期的梯度爆炸的风险,而且负样本的loss也较小,模型训练过程中更容易学习到正样本。而当为0.5或者0.01时,负样本的loss很大,模型很容易陷入负样本的陷阱中。若
取1e-10,虽然负样本loss更低,但是正样本loss增加了,这反而不利于模型的稳定训练。
:
取1e-5时,模型效果最好。从表中我们可以看到,此时的整体loss是最小,这大大降低了训练初期的梯度爆炸的风险,而且负样本的loss也较小,模型训练过程中更容易学习到正样本。而当为0.5或者0.01时,负样本的loss很大,模型很容易陷入负样本的陷阱中。若
取1e-10,虽然负样本loss更低,但是正样本loss增加了,这反而不利于模型的稳定训练。
:
 为
为
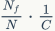 ,此时
,此时
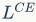 最低。这里我们认为模型训练之初,
最低。这里我们认为模型训练之初,
 。那么可以计算出bias的最优初始化值为:
。那么可以计算出bias的最优初始化值为:
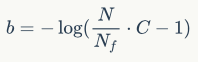 为1.113e-5,和我们的实验值是吻合的。
为1.113e-5,和我们的实验值是吻合的。
4 Guided Loss
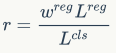
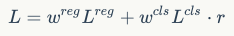
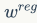 和
和
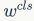 是回归和分类loss的权重系数,是检测模型所固有的参数。简单来说,我们用
是回归和分类loss的权重系数,是检测模型所固有的参数。简单来说,我们用
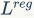 来引导
来引导
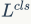 ,以希望分类loss可以和回归loss维持相同的水平,这在论文中称为guided loss。值得注意的是,我们虽然在训练过程中实时确定r,但是这一过程是不经过BP的,所以这一机制没有带来任何负担,也不引入新的超参数。
,以希望分类loss可以和回归loss维持相同的水平,这在论文中称为guided loss。值得注意的是,我们虽然在训练过程中实时确定r,但是这一过程是不经过BP的,所以这一机制没有带来任何负担,也不引入新的超参数。
5 类别自适应阈值
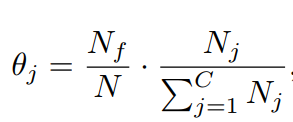
6 实验效果



7 小结
CV细分方向交流群
添加极市小助手微信(ID : cv-mart),备注:研究方向-姓名-学校/公司-城市(如:目标检测-小极-北大-深圳),即可申请加入目标检测、目标跟踪、人脸、工业检测、医学影像、三维&SLAM、图像分割、姿态估计、超分辨率、嵌入式视觉、OCR 等极市技术交流群(已经添加小助手的好友直接私信),更有每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流,一起来让思想之光照的更远吧~

△长按添加极市小助手

△长按关注极市平台
觉得有用麻烦给个在看啦~

登录查看更多
相关内容

RetinaNet是2018年Facebook AI团队在目标检测领域新的贡献。它的重要作者名单中Ross Girshick与Kaiming He赫然在列。来自Microsoft的Sun Jian团队与现在Facebook的Ross/Kaiming团队在当前视觉目标分类、检测领域有着北乔峰、南慕容一般的独特地位。这两个实验室的文章多是行业里前进方向的提示牌。
RetinaNet只是原来FPN网络与FCN网络的组合应用,因此在目标网络检测框架上它并无特别亮眼创新。文章中最大的创新来自于Focal loss的提出及在单阶段目标检测网络RetinaNet(实质为Resnet + FPN + FCN)的成功应用。Focal loss是一种改进了的交叉熵(cross-entropy, CE)loss,它通过在原有的CE loss上乘了个使易检测目标对模型训练贡献削弱的指数式,从而使得Focal loss成功地解决了在目标检测时,正负样本区域极不平衡而目标检测loss易被大批量负样本所左右的问题。此问题是单阶段目标检测框架(如SSD/Yolo系列)与双阶段目标检测框架(如Faster-RCNN/R-FCN等)accuracy gap的最大原因。在Focal loss提出之前,已有的目标检测网络都是通过像Boot strapping/Hard example mining等方法来解决此问题的。作者通过后续实验成功表明Focal loss可在单阶段目标检测网络中成功使用,并最终能以更快的速率实现与双阶段目标检测网络近似或更优的效果。
专知会员服务
33+阅读 · 2020年4月26日
专知会员服务
38+阅读 · 2020年3月23日
专知会员服务
46+阅读 · 2019年11月15日
Arxiv
4+阅读 · 2019年4月15日
Arxiv
4+阅读 · 2018年7月4日

相关VIP内容
专知会员服务
33+阅读 · 2020年4月26日
专知会员服务
38+阅读 · 2020年3月23日
专知会员服务
46+阅读 · 2019年11月15日
相关资讯
相关论文
Arxiv
4+阅读 · 2019年4月15日
Arxiv
4+阅读 · 2018年7月4日