2019 AAAI GHM(解决one-stage样本不平衡问题)目标检测算法论文阅读笔记
加入极市专业CV交流群,与6000+来自腾讯,华为,百度,北大,清华,中科院等名企名校视觉开发者互动交流!更有机会与李开复老师等大牛群内互动!
同时提供每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流。点击文末“阅读原文”立刻申请入群~
本文转载自知乎专栏:目标检测
来源:https://zhuanlan.zhihu.com/p/54182158
已获作者授权,请勿二次转载
背景
《Gradient Harmonized Single-stage Detector》是2019 AAAI的Oral paper,出自港中文。这篇论文半年前就出来了,原理也比较简单,但当时认为相比于RetinaNet,GHM只有0.8个点的提升,所以感觉没有尝试的价值。但是最近结合Libra RCNN那篇关于balanced loss的讨论,以及目前在工程上的实现结果来看,性能提升还是非常明显的(特别是很多数据集标注存在误标的情况),值得分享下。
论文链接:
https://arxiv.org/pdf/1811.05181.pdf
代码地址:
https://github.com/libuyu/GHM_Detection
另外该代码基于港中文发布的mmdetection开发,目前港中文很多代码都是基于mmdetection实现,资源也较多,感兴趣的可以安装下。
一、研究动机:
该论文主要聚焦于one-stage方法中样本不平衡问题,包括正样本和负样本、难易样本的不平衡问题。对比RetinaNet(focal loss)通过alpha参数控制正负样本比例、gamma参数控制难易样本比例,但是RetinaNet存在两个主要的问题,1)两个超参需要调整,在COCO上虽然影响不大,但是在产品中的训练样本来看,影响很大;2)没有考虑难例中outliers的影响,使得模型较难收敛,或者导致性能下降。
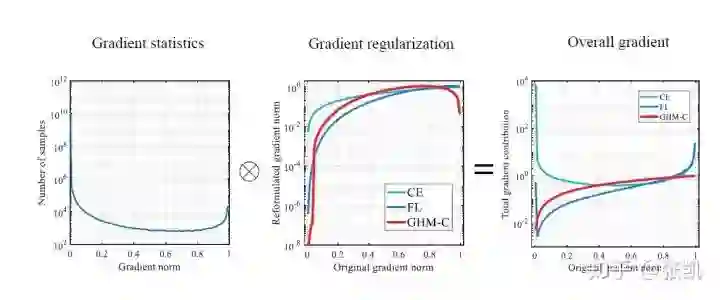
可以看到上图最右边Focal loss代表的蓝色的线在梯度为1的时候(outliers)比重是很大的。
二、具体方法
1 问题定义
首先是对之前问题的定义,即之前的交叉熵损失函数:
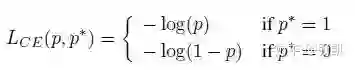
梯度求导非常简单:
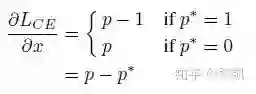
进一步简写为:
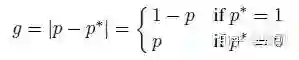
2 梯度密度
引入梯度密度的概念:
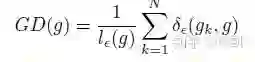
并且,
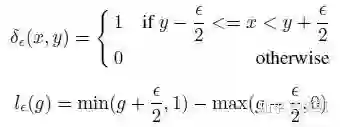
物理意义非常简单,就是在一个区间内梯度的数目。从而引入梯度密度均衡参数:
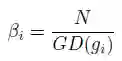
物理意义就是,密度越大,该部分的权重会被降低。
3 GHM-C函数
主要是对分类一支的改进,将梯度密度均衡参数引入:
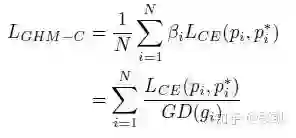
4 GHM-R函数
首先是对smooth L1的改进(主要是d可以无限大),所以引入了提出了ASL1:
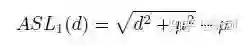
其梯度为:
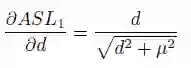
然后在此基础上加入梯度密度均衡参数:
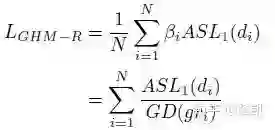
三、实验结果
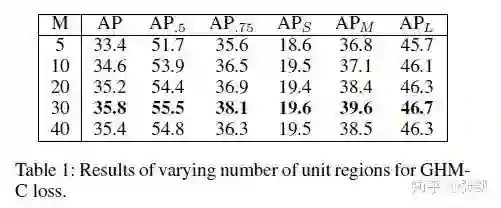
首先是超参的影响,M代表了划分区间,越大的话,越接近密度,但是由于每次迭代样本的随机性,也就越不稳定。在COCO上,M=30最好。
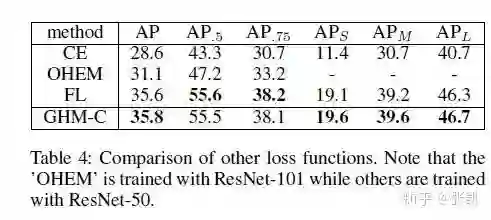
GHMC和FL在COCO上表现差不多。
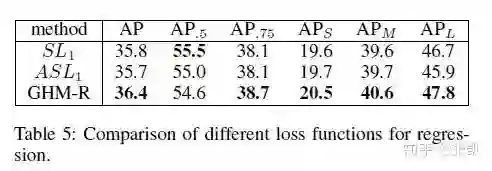
GHMR比SL提升了0.6个百分点。
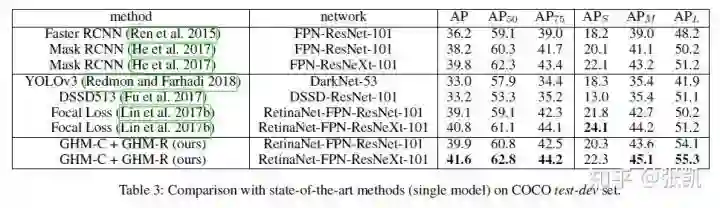
最好的结果,在不同的backbone上,均有0.8个点的提升。
四、总结分析
GHM的思想比FL更进一步地解决了样本不平衡的问题,虽然在COCO上提升不大,但是在某些比较脏的数据集上,表现非常好,值得尝试。
*延伸阅读
点击左下角“阅读原文”,即可申请加入极市目标跟踪、目标检测、工业检测、人脸方向、视觉竞赛等技术交流群,更有每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流,一起来让思想之光照的更远吧~

△长按关注极市平台
觉得有用麻烦给个在看啦~