CVPR2020 | 3D目标检测点云检测新网络 PV-RCNN
点击上方“计算机视觉life”,选择“星标”
快速获得最新干货
简介
今天这一篇是19年12月30日放到arxiv上的,其实在CVPR2020截止后就一直在关注在关注的一篇文章,毕竟在KITTI的3D检测上高居榜首,并且远远的超过了第二名。如下:

是很有必要研读一下,这篇文章出自港中文和商汤的工作。
先看题目猜测一下,是结合了目前基于点和基于voxel的方法进行特征提取。5555,好像博主之前的一点工作也是朝着这个方向去做过,奈何太菜,没做出好的结果。
Abstract
-
本文的特征提取方式充分利用的3D voxel卷积和基于点的pointnet卷积方式。其中作者给出的解释是3D voxel卷积高效,而point-based的方法感受野可变,因此结合了这两种检测方法的优点。 -
该方法是一个两阶段的方法, 第一阶段提proposals,第二阶段为refine -
该方法远远好于KITTI其他的方法,在精度的表现上看。
一个简单的过程如下,盲猜为多尺度特征融合到key-point上的一个创新工作。
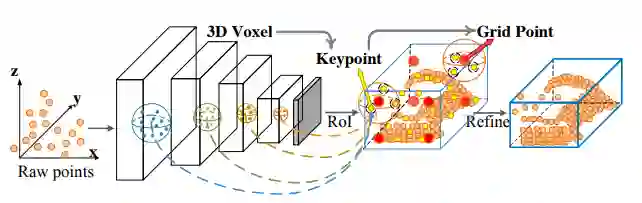
1. Introduction
-
3D检测应用 -
本文是一个将point_based的方法和voxel_based方法的结合的新型网络结构(在文章作者称voxel_based为grid_based的方法,实则同一种方法) -
一些point_based和grid_based方法的简单介绍。并且提取存在的问题。这也是作者的论文出发点,结合这两种方法的优点。(高效+可变感受野)
the grid-based methods are more computationally efficient but the inevitable information loss degrades the finegrained localization accuracy, while the point-based methods have higher computation cost but could easily achieve larger receptive field by the point set abstraction
-
PV-RCNN为结合这两种方法的算法,采用multi-scale的方法获得由voxel_based方法得到的高质量的proposals,然后再利用Point_based的方法获得精细的局部信息。
The principle of PV-RCNN lies in the fact that the voxel-based operation efficiently encodes multi-scale feature representations and can generate high-quality 3D proposals.
-
核心也就是如何将上述的两种方法有效的结合起来,这里作者的做法是:在每一个3D proposals内平均的采样一些Grid-point,然后再通过P2的FPS最远点采样的方法得到该Grid_point周围的点,再通过结合去进一步refine最后的proposals
-
因此,作者采用两阶段的方法去更好的结合上述的两种算法的优点。
(1) 第一阶段为:“voxel-to-keypoint scene encoding step ”,这一步是提出proposals,作者首先对整个场景采用voxel的方法进行特征提取,同时采取一支分支对场景采用point的FPS采样,然后检索得到多尺度的voxel的特征,如下的表示。这样实际上仅仅是采用了voxel的特征,但是表示在key-point身上。
(2)第二阶段为‘keypoint-to-grid RoI feature abstraction’:这一步骤,作者提出了一个新的RoI-grid pooling module,该模块将上一步骤的keypoints的特征和RoI-grid points特特征融合(keypoints和RoI-grid points是什么内容后续会讲到)
-
contributions
2. Related Work
这一部分不细讲,基本上的文章都大差不差。如下内容
-
3D Object Detection with Grid-based Methods. -
3D Object Detection with Point-based Methods. -
Representation Learning on Point Clouds.
3. PV-RCNN for Point Cloud Object Detection
3.1. 3D Voxel CNN for Efficient Feature Encoding and Proposal Generation
-
3D voxel CNN -
3D proposal generation
上面的两点内容大都和其他目前流行的基于voxel的方法一样,不多赘述。
-
Discussions
(1)目前大多精度高的工作都采用了refine优化的工作,这里作者提出两个问题,如果采用类似roi_pooling的方式去做,那么由于8倍的下采样会使得分辨率很低,此外如果采样得到的是较高的分辨率图片又会得到稀疏的表示(Fast-PointRCNN)。第二个问题是传统的ROI-POOLING和ROI-ALIGN实际上得到仅能在一个小的区域内进差值,因此如果在3D稀疏的表达上可能得到几乎都是0的特征表示。(2)进一步的,P2提出的set-abstruction的操作很好的编码“可变”领域的特征,后续考虑到去voxel上差值的内存占用,作者提出了先提出关键点,然后再利用关键点编码voxel卷积过程的多尺度特征。
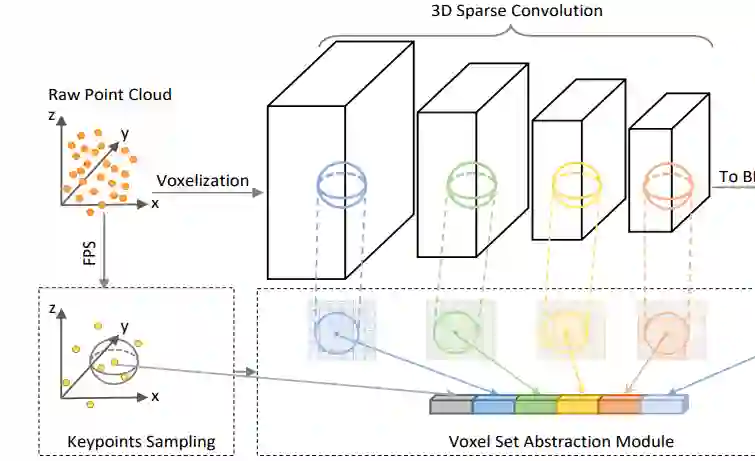
3.2. Voxel-to-keypoint Scene Encoding via Voxel Set Abstraction
-
Keypoints Sampling
采用FPS,对KITTI数据集的关键点个数为2048,对waymo数据集为4096个点。用于代表整个场景的特征信息。
-
Voxel Set Abstraction Module
作者自行设计了Voxel Set Abstraction (VSA) module这样的一个模块,这个模块的作用是将keypoint周围非空的voxel特征采集出来结合在一起,原文用了很多数学表达,含义大致如此。
-
Extended VSA Module
进一步的在二维上,采用的是双线性插值得到关键点投影到BEV上的特征。最终的特征将有三部分组成,分别是来自voxel语义信息 , 来自原始点云的特征信息 (作者说这一部分信息是为了弥补之前在voxel化时丢失的信息),来自BEV的高级信息 .
-
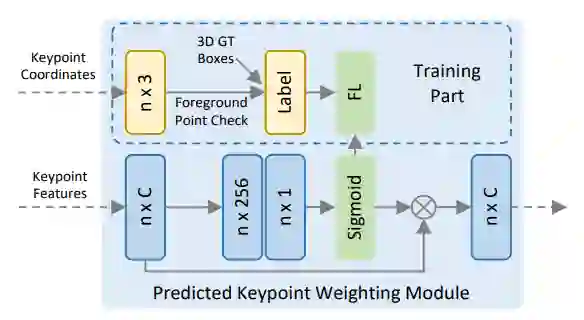
Predicted Keypoint Weighting.
(1)上述的特征融合实际上都是为了进一步的refine做准备,第一阶段的proposals实际上是由voxel-based的方法提出来的,这一步 Keypoint Weighting的工作是为了给来自背景和前景的关键点一个不一样的权重,使得前景对refine的贡献更大。(2)为了做这样的一个工作,作者设计了如下的额为的网络结构。这里面的Label对应的是是否在gt内,采用fcoal_loss。
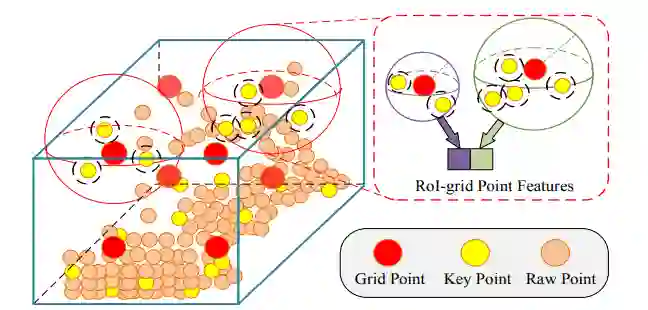
3.3 Keypoint-to-grid RoI Feature Abstraction for Proposal Refinement
这就是作者提出的第二阶段,refinement,前文提到通过3D稀疏卷积处理voxel已经得到了比较好的精度的proposals,但是多尺度的keypoint的特征是为了进一步refine结果。因此作者在这个阶段提出了keypoint-to-grid RoI feature abstraction模块。如下:
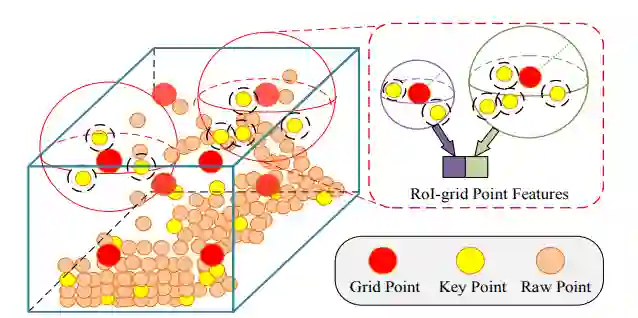
(1)从该模块名称和图就可以看得出来,作者是想通过将key-point的特征整合到grid-point中去,并且也采用了multi-scale的策略。作者在每个proposals中都采样 个grid points. (2)首先确定每一个grid-point的一个半径下的近邻,然后再用一个pointnet模块将特征整合为grid_point的特征,这里会采用多个scale的特征融合手段。(3)得到了所有的grid-point的点特征后,作者采用两层的MLP得到256维度的proposals的特征。
-
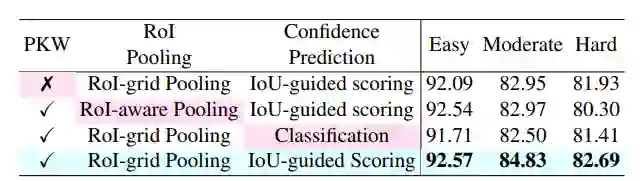
3D Proposal Refinement and Confidence Prediction 作者在confidence prediction branche 这一分支上采用了前人提出的 3D Intersection-over-Union (IoU),对于第k个ROI的置信度的目标是如下公式:
该公式中 表示第k个ROI对应的GT,因此confidence prediction branche的LOSS函数采用的是交叉熵loss:
是预测的置信度的分数,如下的实验表明采用这种置信度是能提高算法的精度的。
3.4. Training losses
-
RPN loss
-
keypoint seg loss也就是前背景关键点的权重loss。 -
refinement loss 定义如下:
这里的两部分loss第一个置信度LOSS也就是前文提出的LOSS,后面的SmoothL1 LOSS和以前的一样。
4. Experiments
有一些参数设置和实验的实现细节,博主就不写下来了。原文很详尽。列出实验效果吧。在test的数据集上:几乎都好比第二名好几个点,真的牛。
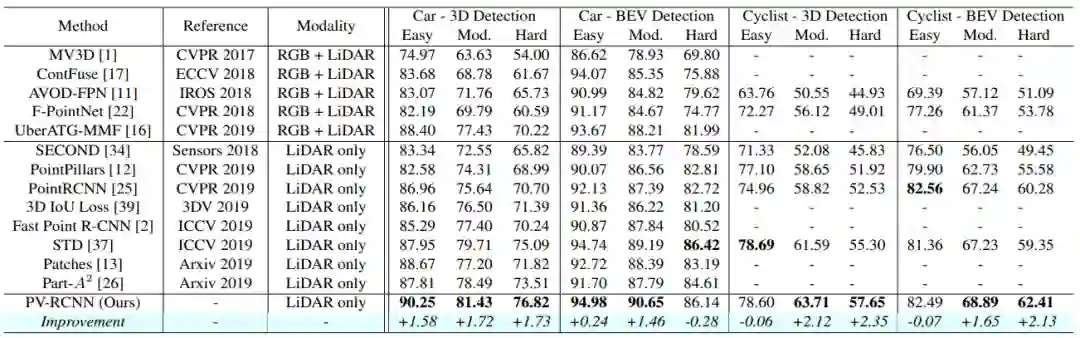
在watmo上如下:

从0到1学习SLAM,戳↓

交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~
投稿、合作也欢迎联系:simiter@126.com

扫描关注视频号,看最新技术落地及开源方案视频秀 ↓



