ECCV 2022 | CMU提出首个快速知识蒸馏的视觉框架:ResNet50 80.1%精度,训练加速30%
机器之心专栏

-
论文和项目网址:http://zhiqiangshen.com/projects/FKD/index.html -
代码:https://github.com/szq0214/FKD
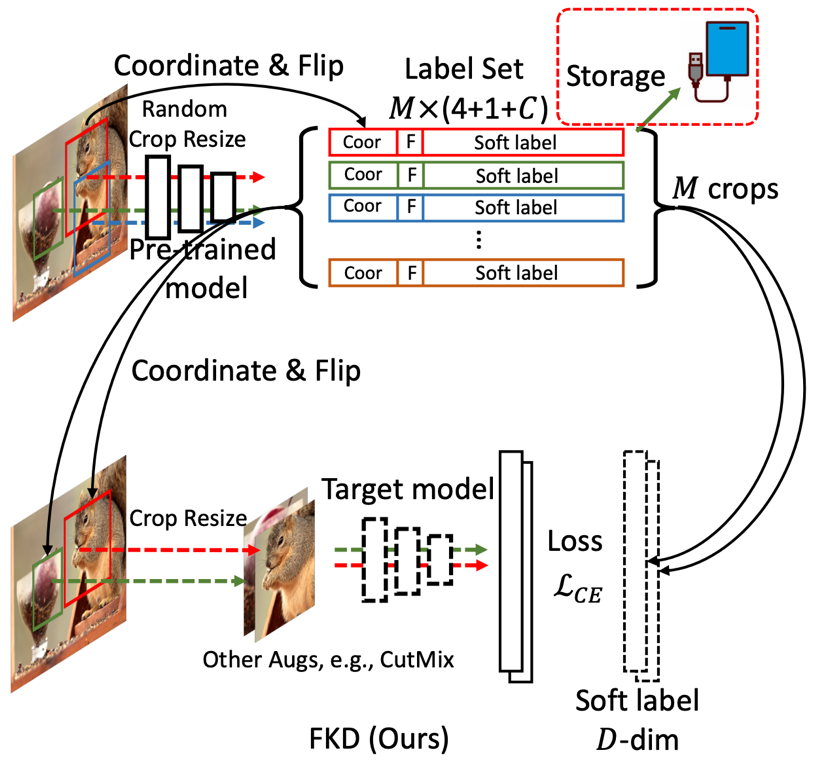
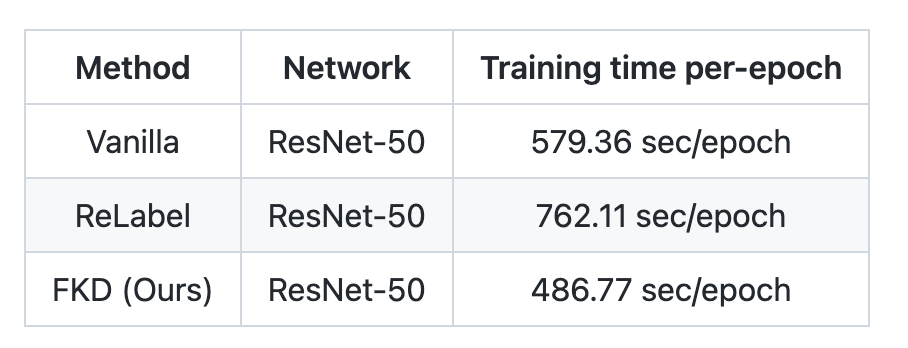
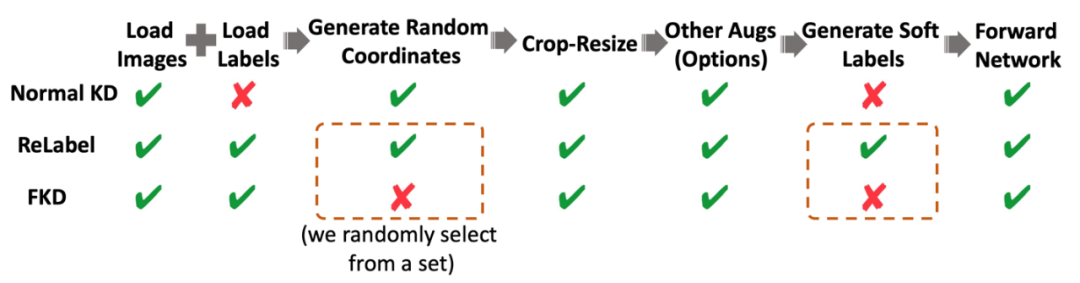
-
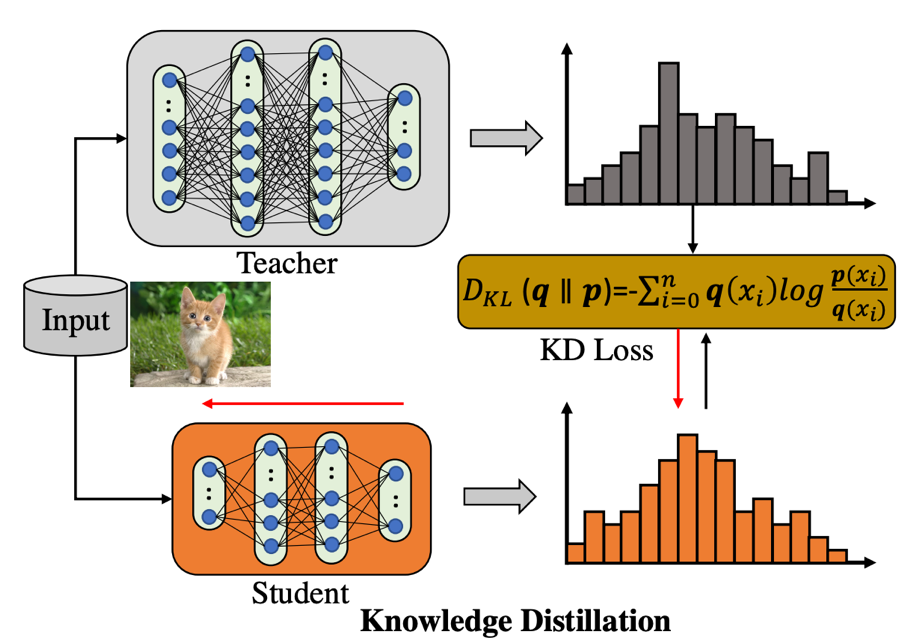
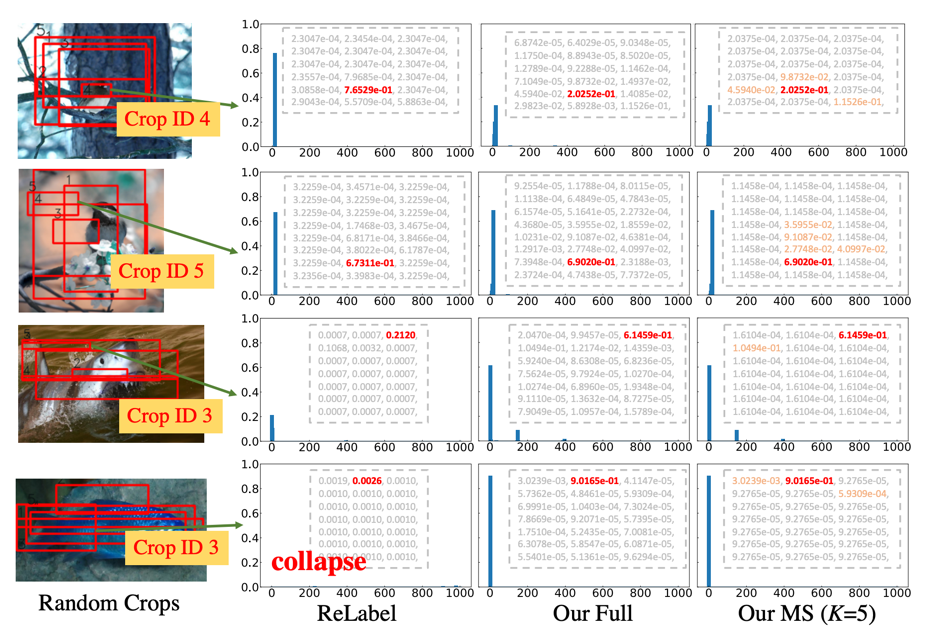
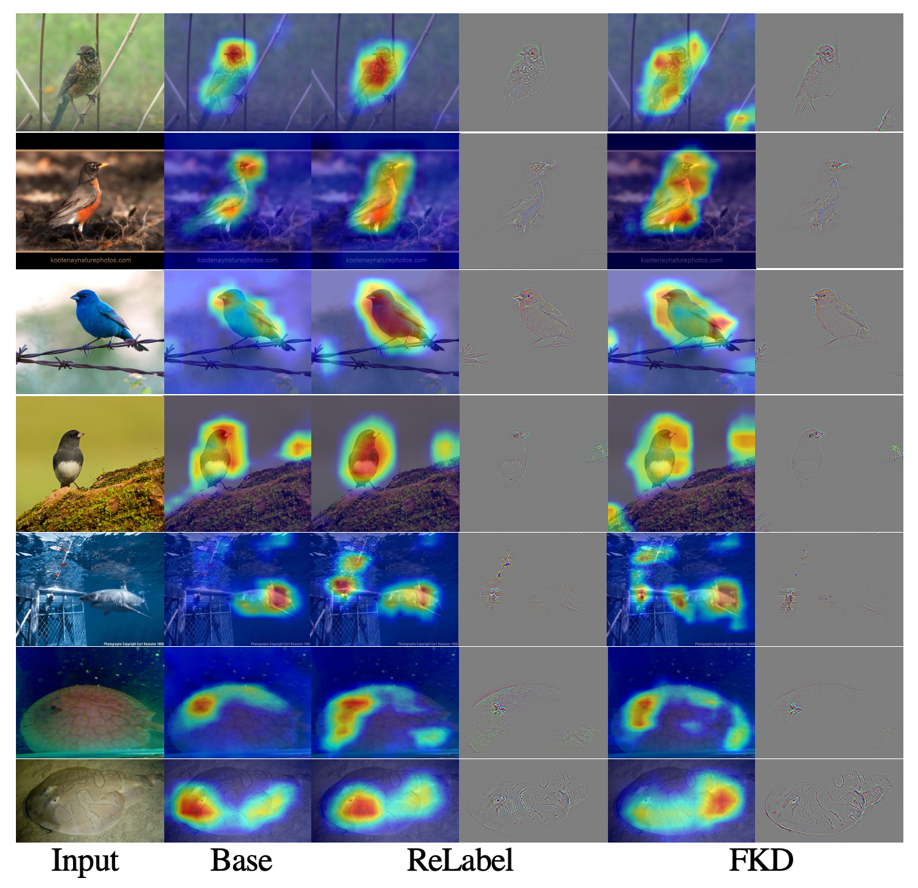
(第一行)FKD 相比 ReLabel 置信度更加平均也与输入样本内容更加一致,作者分析原因是 ReLabel 将全局图像输入到模型中,而不是局部区域,这使得生成的全局标签映射编码了更多全局类别信息同时忽略了背景信息,使得生成的软标签过于接近单个语义标签。 -
(第二行)虽然存在一些样本 ReLabel 和 FKD 之间的最大预测概率相似,但 FKD 包含更多标签分布中的从属类别概率,而 ReLabel 的分布中并没有捕获这些从属类别的信息。 -
(第三行)对于某些异常情况,FKD 比 ReLabel 更加健壮,例如目标框含有松散边界,或者只定位部分目标等。 -
(第四行)在有些情况下,ReLabel 的标签分布意外的崩溃了(均匀分布),没有产生一个主要的预测,而 FKD 仍然可以预测得很好。
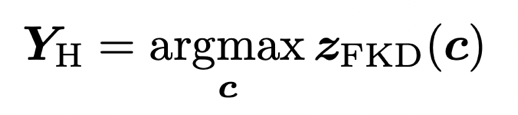
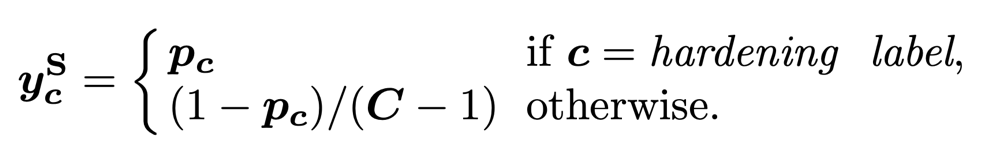
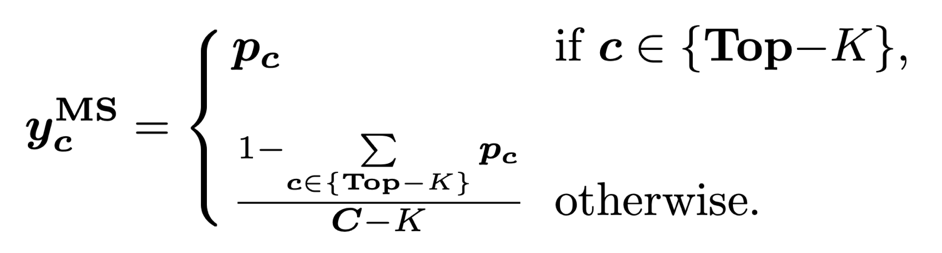
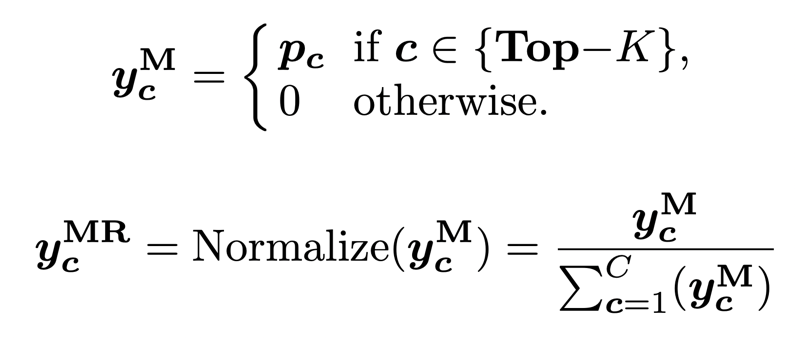






登录查看更多
相关内容

Arxiv
0+阅读 · 2022年11月25日
Arxiv
0+阅读 · 2022年11月23日
Arxiv
13+阅读 · 2018年1月6日

相关VIP内容
相关资讯
相关论文
Arxiv
0+阅读 · 2022年11月25日
Arxiv
0+阅读 · 2022年11月23日
Arxiv
13+阅读 · 2018年1月6日