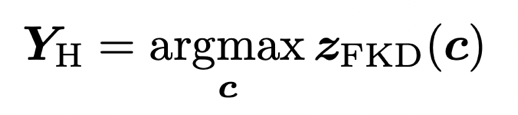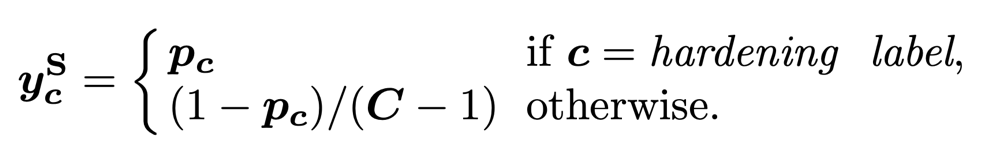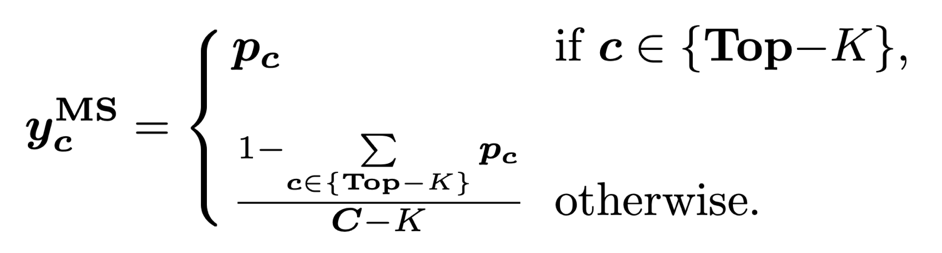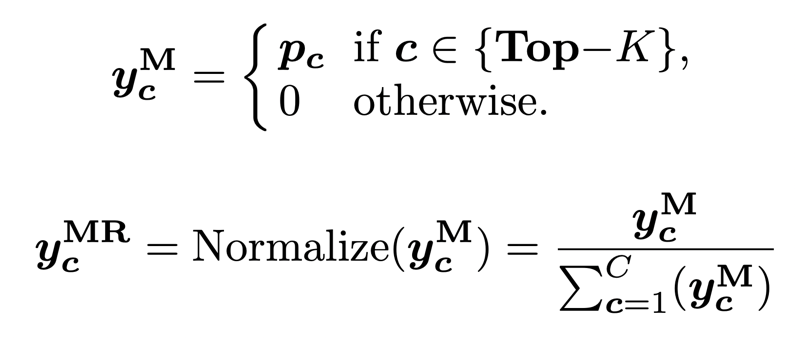![]()
©作者 | 机器之心编辑部
来源 | 机器之心
今天介绍一篇来自卡耐基梅隆大学等单位 ECCV 2022 的一篇关于快速知识蒸馏的文章,用基本的训练参数配置就可以把 ResNet-50 在 ImageNet-1K 从头开始 (from scratch) 训练到 80.1% (不使用 mixup,cutmix 等数据增强),训练速度(尤其是数据读取开销)相比传统分类框架节省 16% 以上,比之前 SOTA 算法快 30% 以上,是目前精度和速度双双最优的知识蒸馏策略之一,代码和模型已全部开源。
![]()
论文标题:
A Fast Knowledge Distillation Framework for Visual Recognition
http://zhiqiangshen.com/projects/FKD/index.html
https://github.com/szq0214/FKD
知识蒸馏(KD)自从 2015 年由 Geoffrey Hinton 等人提出之后,在模型压缩,视觉分类检测等领域产生了巨大影响,后续产生了无数相关变种和扩展版本,但是大体上可以分为以下几类:vanilla KD,online KD,teacher-free KD 等。
最近不少研究表明,一个最简单、朴素的知识蒸馏策略就可以获得巨大的性能提升,精度甚至高于很多复杂的 KD 算法。但是 vanilla KD 有一个不可避免的缺点:每次 iteration 都需要把训练样本输入 teacher 前向传播产生软标签 (soft label),这样就导致很大一部分计算开销花费在了遍历 teacher 模型上面,然而 teacher 的规模通常会比 student 大很多,同时 teacher 的权重在训练过程中都是固定的,这样就导致整个知识蒸馏框架学习效率很低。
针对这个问题,本文首先分析了为何没法直接为每张输入图片产生单个软标签向量然后在不同 iterations 训练过程中复用这个标签,其根本原因在于视觉领域模型训练过程数据增强的使用,尤其是 random-resize-cropping 这个图像增强策略,导致不同 iteration 产生的输入样本即使来源于同一张图片也可能来自不同区域的采样,导致该样本跟单个软标签向量在不同 iterations 没法很好的匹配。
本文基于此,提出了一个快速知识蒸馏的设计,通过特定的编码方式来处理需要的参数,继而进一步存储复用软标签(soft label),与此同时,使用分配区域坐标的策略来训练目标网络。通过这种策略,整个训练过程可以做到显式的 teacher-free,该方法的特点是既快(16%/30% 以上训练加速,对于集群上数据读取缓慢的缺点尤其友好),又好(使用 ResNet-50 在 ImageNet-1K 上不使用额外数据增强可以达到 80.1% 的精度)。
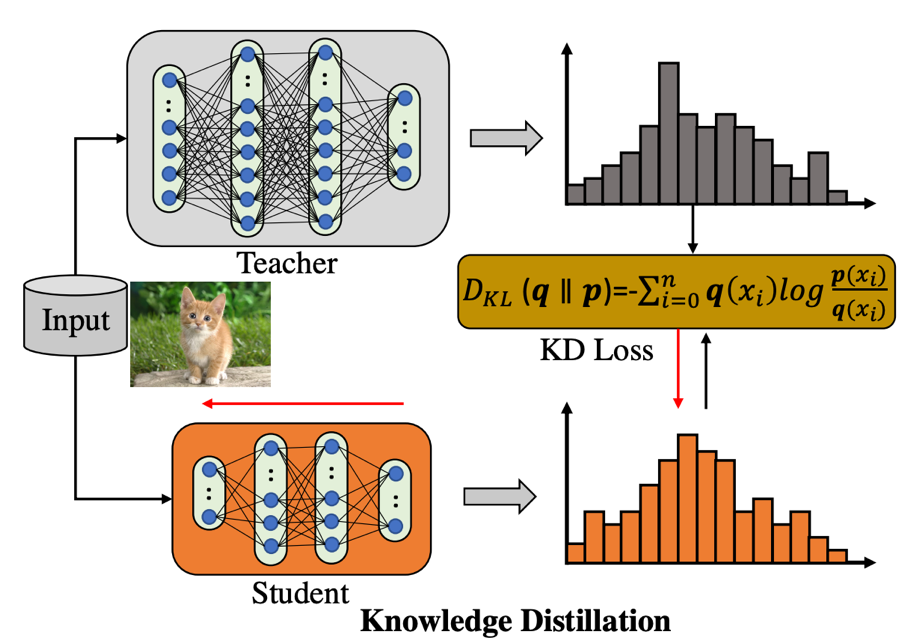
首先我们来回顾一下普通的知识蒸馏结构是如何工作的,如下图所示:
![]()
知识蒸馏框架包含了一个预训练好的 teacher 模型(蒸馏过程权重固定),和一个待学习的 student 模型, teacher 用来产生 soft 的 label 用于监督 student 的学习。可以看到,这个框架存在一个比较明显的缺点:当 teacher 结构大于 student 的时候,训练图像前馈产生的计算开销已经超过 student,然而 teacher 权重并不是我们学习的目标,导致这种计算开销本质上是 “无用的”。
本文的动机正是在研究如何在知识蒸馏训练过程中避免或者说重复利用这种额外的计算结果,该文章的解决策略是提前保存每张图片不同区域的软监督信号(regional soft label)在硬盘上,训练 student 过程同时读取训练图片和标签文件,从而达到复用标签的效果。所以问题就变成了:soft label 怎么来组织和存储最为有效?下面具体来看该文章提出的策略。
![]()
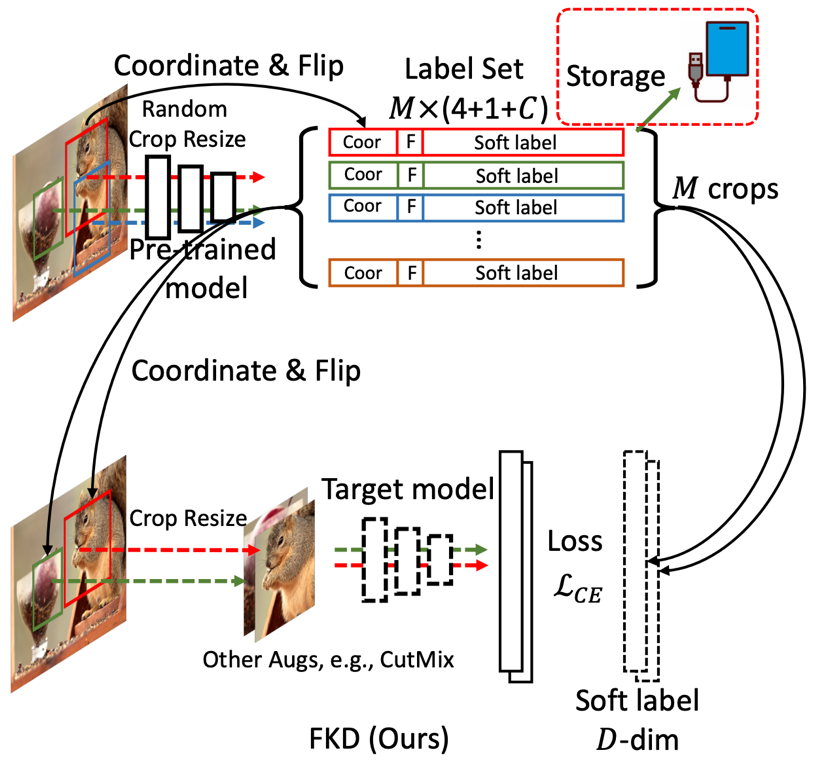
FKD 框架的核心部分包含了两个阶段,如下图:(1)软标签(soft label)的生成和存储;(2)使用软标签(soft label)进行模型训练。
![]()
如图所示,上半部分展示了软标签的生成过程,作者通过输入多个 crops 进入预训练好的 teacher 来产生需要的软标签向量,同时作者还保存了:(1)每个 crop 对应的坐标和(2)是否翻转的 Boolean 值。下半部分展示了 student 训练过程,作者在随机采样图片的时候同时也会读取它们对应的软标签文件,从中选取 N 个 crops 用于训练,额外数据增强比如 mixup,cutmix 会放在这个阶段,从而节省了由于引入更多数据增强参数带来的额外存储开销。
![]()
本文还提出了一个 multi-crop sampling 的策略,即在一个 mini-batch 里面每张图片采样多个样本 crops。当总的训练 epochs 不变的前提下,该采样方式可以大大减少数据读取的次数,对于一些数据读取不是非常高效或者产生严重瓶颈的集群设备,这种策略的加速效果非常明显(如下表格所示)。
同时在一张图片采样多个 crops 可以减少训练样本间的方差,帮助稳定训练,作者发现如果 crops 的数目不是太大的情况下可以明显提升模型精度,但是一张图片里面采样太多 crops 数目会造成每个 mini-batch 里面训练样本的信息差异不足(过于相似),因此过度采样会影响性能,所以需要设置一个合理的数值。
![]()
加速比
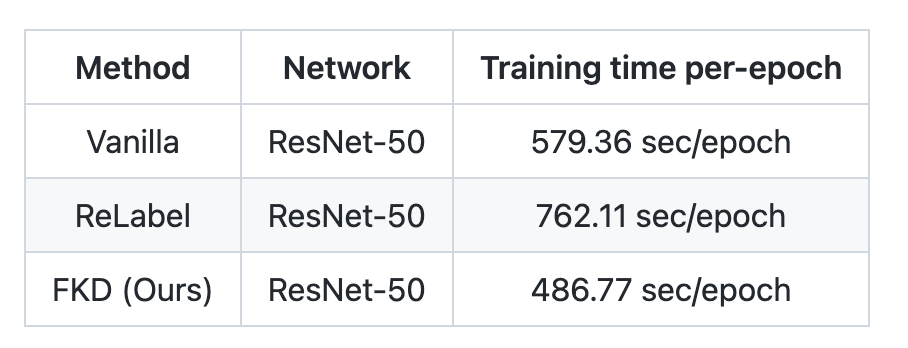
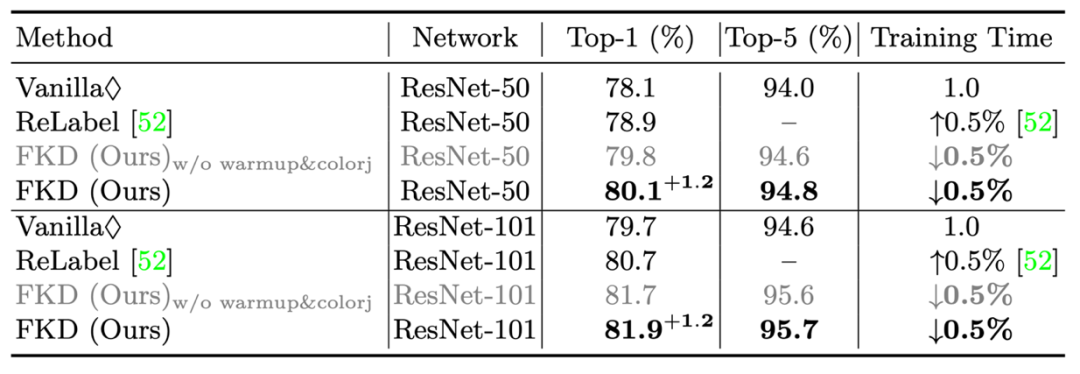
作者在实验部分跟标准的训练方式以及 ReLabel 训练进行了速度的比较,结果如下表格所示:可以看到,相比正常的分类框架,FKD 会快 16% 左右,而相比 ReLabel 则快了 30%,因为 ReLabel 相比正常训练需要读取双倍的文件数目。需要注意的是这个速度对比实验中,FKD crop 数目为 4,如果选取更大的 crop 数目可以得到更高的加速比。
![]()
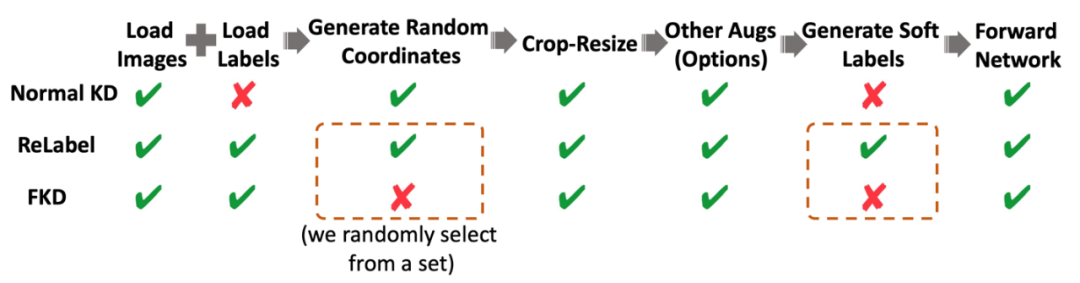
除了上述介绍的采用多个 crops 来进行加速外,作者还分析了其他一些加速的因素,如下图所示,ReLabel 在训练模型阶段需要生成采样数据的坐标,同时需要使用 RoI-Align 和 Softmax 来生成所需的软标签,相比而言,FKD 直接保存了坐标信息和最终软标签格式,因此读取标签文件之后不需要做任何额外的后处理就可以直接训练,速度相比 ReLabel 也会更快。
![]()
![]()
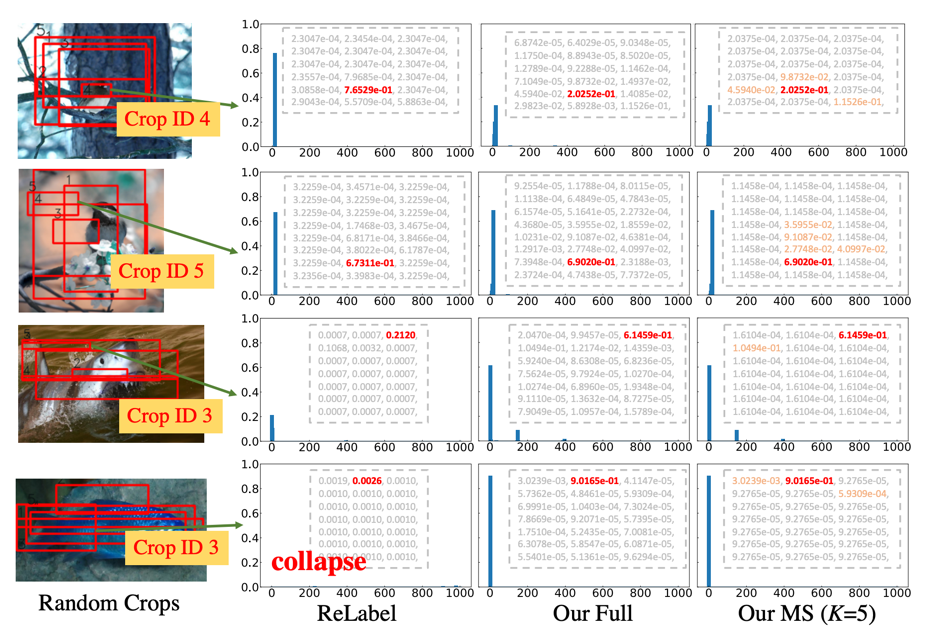
软标签质量是保证模型训练精度的一项最重要的指标,作者通过可视化标签分布以及计算不同模型预测之间的交叉熵(cross-entropy)来证明了所提出的方式拥有更好的软标签质量。
![]()
上图展示了 FKD 和 ReLabel 软标签分布的情况对比,得到如下结论:
1. (第一行)FKD 相比 ReLabel 置信度更加平均也与输入样本内容更加一致,作者分析原因是 ReLabel 将全局图像输入到模型中,而不是局部区域,这使得生成的全局标签映射编码了更多全局类别信息同时忽略了背景信息,使得生成的软标签过于接近单个语义标签。
2. (第二行)虽然存在一些样本 ReLabel 和 FKD 之间的最大预测概率相似,但 FKD 包含更多标签分布中的从属类别概率,而 ReLabel 的分布中并没有捕获这些从属类别的信息。
3. (第三行)对于某些异常情况,FKD 比 ReLabel 更加健壮,例如目标框含有松散边界,或者只定位部分目标等。
4. (第四行)在有些情况下,ReLabel 的标签分布意外的崩溃了(均匀分布),没有产生一个主要的预测,而 FKD 仍然可以预测得很好。
![]()
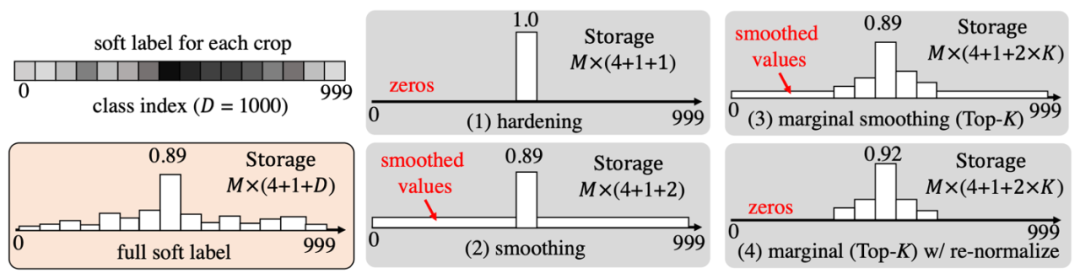
标签压缩、量化策略
1)硬化 (Hardening)。在该策略中,样本标签 Y_H 使用 teacher 预测的最大 logits 的索引。标签硬化策略产生的依然是 one-hot 的标签,如下公式所示:
![]()
2)平滑 (Smoothing)。平滑量化策略是将上述硬化后的标签 Y_H 替换为软标签和均匀分布的分段函数组合,如下所示:
![]()
3)边际平滑 (Marginal Smoothing with Top-K)。边际平滑量化策略相比单一预测值保留了更多的边际信息(Top-K)来平滑标签 Y_S:
![]()
4)边际平滑归一化 (Marginal Re-Norm with Top-K)。边际平滑归一化策略会将 Top-K 预测值重新归一化到和为 1,并保持其他元素值为零(FKD 使用归一化来校准 Top-K 预测值的和为 1,因为 FKD 存储的软标签是 softmax 处理之后的值):
![]()
![]()
![]()
不同标签压缩方法需要的存储空间如下表格所示,所使用的数据集为 ImageNet-1K,其中 M 是软标签生成阶段每张图像被采样的数目,这里作者选取了 200 作为示例。Nim 是图像数量, ImageNet-1K 数据集为 1.2M,SLM 是 ReLabel 标签矩阵的大小,Cclass 是类的数量,DDA 是需要存储的数据增强的参数维度。
![]()
从表格中可以看到,在不做任何压缩的情况下 FKD 软标签需要的存储空间为 0.9T,这在实际使用中显然是不现实的,标签数据的大小已经远远超过训练数据本身了。通过标签压缩可以极大减少存储大小,同时后面实验也证明了合适的压缩方式并不会损害模型精度。
FKD 的训练方式也可以应用于自监督学习任务。作者使用自监督算法比如 MoCo,SwAV 等来预训练 teacher 模型,然后按照上述方式生成用于自监督的软标签(unsupervised soft label),这个步骤跟监督学习得到的 teacher 很相似。生成标签过程会保留原始自监督模型中 projection head 并使用之后的最终输出向量,然后将这个向量作为软标签保存下来。得到该软标签后,可以使用同样的监督式的训练方式来学习对应的 student 模型。
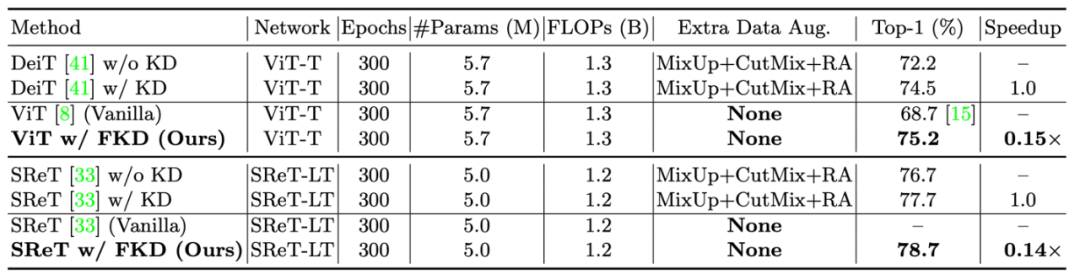
1)首先是在 ResNet-50 和 ResNet-101 上的结果,如下表所示,FKD 取得了 80.1%/ResNet-50 和 81.9%/ResNet-101 的精度。同时训练时间相比普通训练和 ReLabel 都快了很多。
![]()
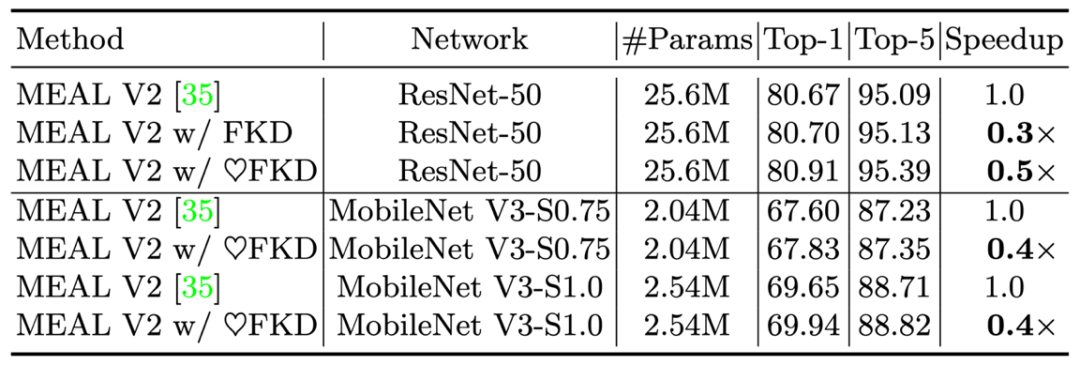
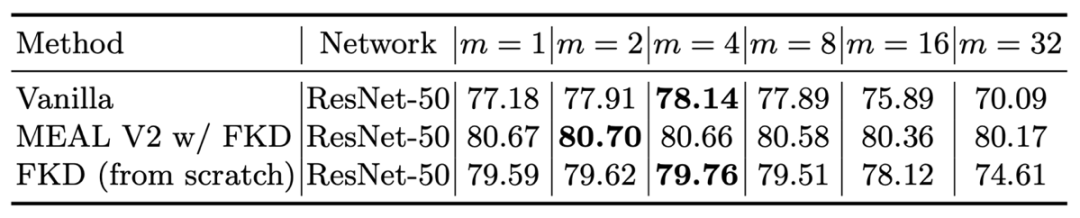
2)作者还测试了 FKD 在 MEAL V2 上的结果,同样得到了 80.91% 的结果。
![]()
3)Vision Transformer 上的结果:
接下来作者展示了在 vision transformer 上的结果,在不使用额外数据增强的情况下,FKD 就可以比之前知识蒸馏方法得到将近一个点的提升,同时训练速度快了 5 倍以上。
![]()
![]()
首先是不同压缩策略,综合考虑存储需求和训练精度,边际平滑策略是最佳的。
接下来是训练阶段不同 crop 数目的对比,MEAL V2 由于使用了 pre-trained 的参数作为初始化权重,因此不同 crop 数目下性能都比较稳定和接近。而 vanilla 和 FKD 在 crop=4 的时候表现得最好。尤其 vanilla,相比 crop=1 精度提升了一个点,crop 大于 8 之后精度下降明显。
![]()
如下表所示,在自监督学习任务上 FKD 方式还是可以很好的学习目标模型,同时相比双子结构自监督网络训练和蒸馏训练,可以加速三到四倍。
![]()
![]()
下表给出了 FKD 模型在 ImageNet ReaL 和 ImageNetV2 两个数据集上的结果,可以看到,FKD 在这些数据集上取得了稳定的提升。
![]()
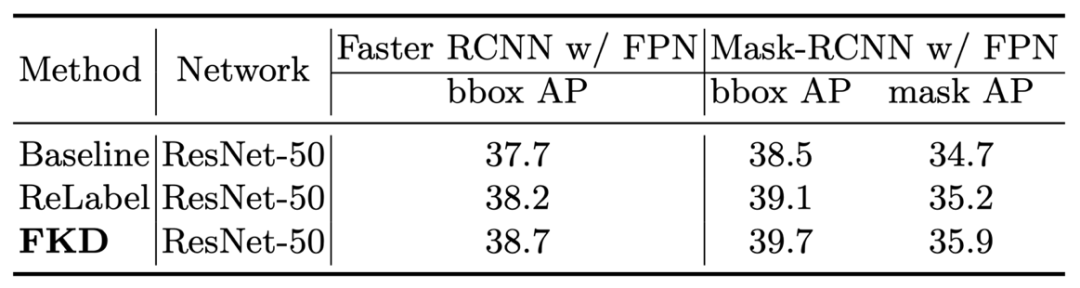
下表是 FKD 预训练模型在 COCO 目标检测任务上的结果,提升同样明显。
![]()
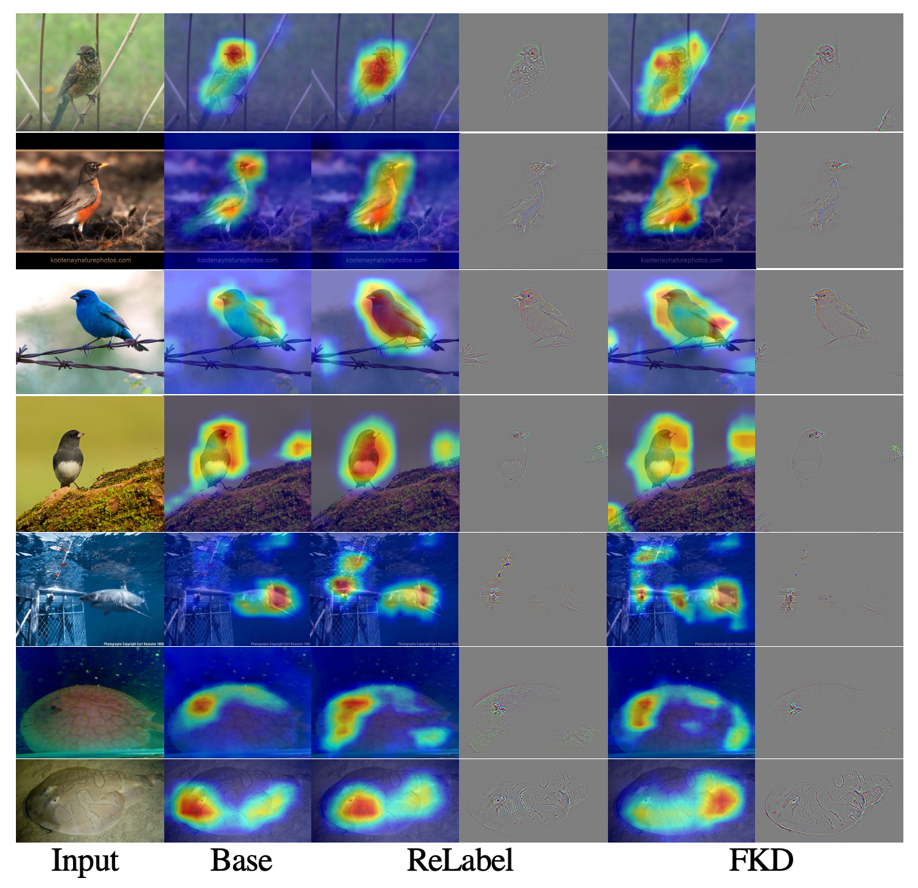
如下两张可视化图所示,作者通过可视化中间特征层(attention map)的方式探索 FKD 这种 region-based 训练方式对模型产生的影响,作者对比了三种不同训练方式得到的模型:正常 one-hot label,ReLabel 和本文提出的 FKD。
(i) FKD 的预测的概率值相比 ReLabel 更加小(soft),因为 FKD 训练过程引入的上下文以及背景信息更多。在 FKD 随机 crop 的训练策略中,许多样本采样于背景(上下文)区域,来自 teacher 模型的软预测标签更能真实的反映出实际输入内容,并且这些软标签可能与 one-hot 标签完全不同,FKD 的训练机制可以更好的利用上下文中的额外信息。
(ii) FKD 的特征可视化图在物体区域上具有更大的高响应值区域,这表明 FKD 训练的模型利用了更多区域的线索进行预测,进而捕获更多差异性和细粒度的信息。
(iii)ReLabel 的注意力可视化图与 PyTorch 预训练模型更加接近,而 FKD 的结果跟他们相比具有交大差异性。这说明 FKD 方式学习到的注意力机制跟之前模型有着显著的差别,从这点出发后续可以进一步研究其有效的原因和工作机理。
![]()
![]()
![]()
![]()
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
📝 稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
📬 投稿通道:
• 投稿邮箱:hr@paperweekly.site
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿
![]()
△长按添加PaperWeekly小编
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
![]()