【干货笔记】Generating Question-Answer Hierarchies阅读笔记
点击上方,选择星标或置顶,每天给你送干货
阅读大概需要5分钟
跟随小博主,每天进步一丢丢


来自 | 知乎
地址 | https://zhuanlan.zhihu.com/p/86593349
作者 | 大葱的kangzhan史
编辑 | 机器学习算法与自然语言处理公众号
本文仅作学术分享,若侵权,请联系后台删文处理
文章:Generating Question-Answer Hierarchies
来源:ACL2019
链接:
解决问题:本文介绍了SQUASH(专一性控制问题-答案层次结构)一种新颖且具有挑战性的文本生成任务,可将输入文档转换为有层次结构的问题-答案对。用户可以单击高级问题(例如“ Frodo为何离开研究金?”)来显示相关但更具体的问题(例如“ Frodo谁离开了?”)。
1.贡献:
· 一种根据问题的特殊性对问题进行分类的方法。
· 一种模型,用于控制所生成问题的特异性,这与之前进行QA的工作不同。
· 一种新颖的文本生成任务(SQUASH),它将文档转换为QA对基于特定性的层次结构。
· 用于解决SQUASH的流水线系统以及用于评估它的众包方法。
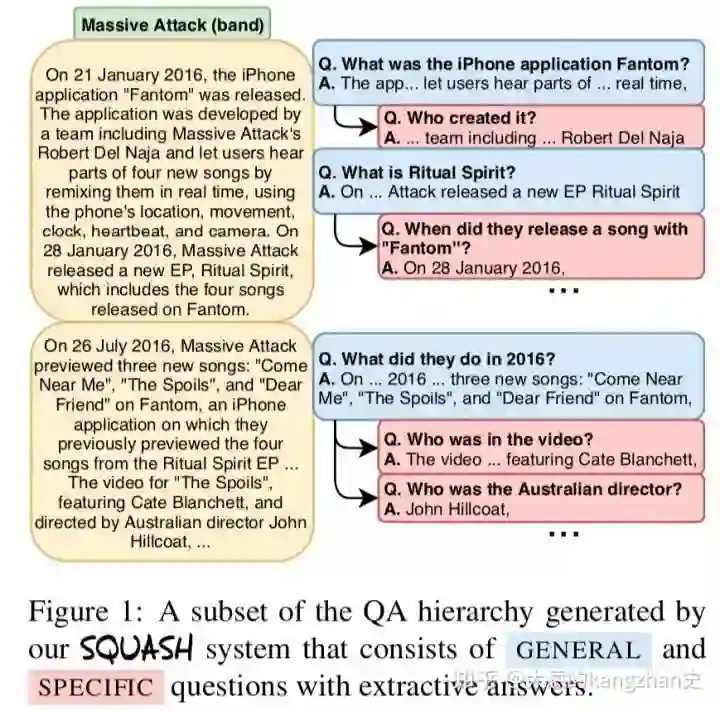
2.相关工作介绍:

3.模型:
3.1问题分类:
我们将问题分为三个粗糙的标签:GENERAL,SPECIFIC或YES-NO,根据问题的特殊性自动对SQuAD,QuAC和CoQA中的问题进行分类。具体问题通常要求低级别的信息(例如,实体或数字),而一般问题则要求更广泛的概述(例如,“ 1999年发生了什么?”)或因果信息(例如,“为什么……”)。使用简单的模板和规则可以可靠地识别许多问题类别。
对于不满足任何模板或规则的问题,手动标注了1000条数据用CNN分类器进行分类,最终将所有问题都运行了基于规则的方法,并将分类器应用于规则未涵盖的问题。
3.2生成QA对:
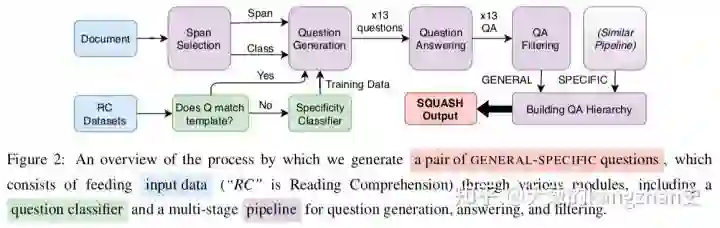
在训练时,我们使用这些数据集中的真实答案范围作为问题生成器的输入。将输入段落中的所有单个句子视为潜在的答案范围(以生成一般和具体问题),以及所有实体和数字(仅针对具体问题)。
为了提高从句子生成的特殊问题的质量,手动删除了一些非常笼统的问题(例如“本文中发生了什么?”)。其他一些问题(例如“他在哪里出生?”)在数据集中被重复多次;我们将此类问题下采样到最大限制为10。
我们使用两层的biL-STM编码器和单层的LSTM解码器来生成问题(1997),将解码器的特殊性级别设置为“一般”,“具体”和“是-否”。每个答案范围生成十三个候选问题。
3.3形成有层次的QA对:

首先,为每个特殊问题选择一个父项----使每个一般问题的预测答案与预测答案的重叠(词级精度)最大化。如果没有与特定问题的答案重叠的一般问题的答案,我们将其映射到最接近的一般问题----其答案在特定问题的答案之前。
4.实验与评估:
对于我们所有的实验,我们使用BiDAF ++问题回答模型的AllenNLP实现。(2018)在没有对话上下文的情况下对QuAC进行了训练。
4.1生成问题评估:
我们使用各种众包实验在QuAC开发集的文档上评估了SQUASH流程。
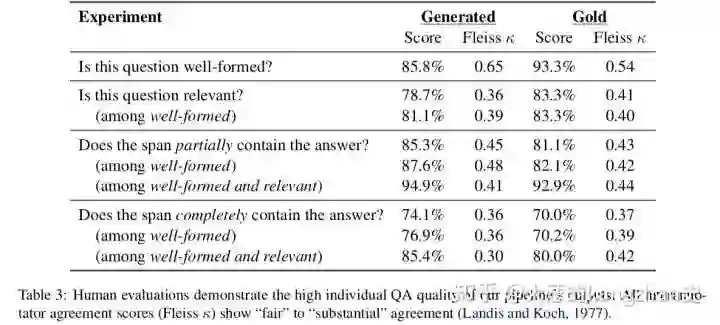
4.2结构正确性评估(抽样):
首先,我们调查我们的模型是否实际上在生成带有正确特异性标签的问题。我们对400个随机抽样的问题(一般50%,特殊50%)运行了特异性分类器(第2部分),并获得91%的高分类精度。这种自动评估表明该模型能够产生不同类型的问题。
为了查看一般问题是否确实提供了更多的高级信息,我们对200个一般-具体问题对进行了抽样。对于每对问题(不显示答案),我们请人群工作者选择问题,如果回答了问题,将为他们提供有关该段落的更多信息。在89.5%的情况下,一般问题优于特定问题,这证实了我们的特异性控制问题生成系统的优势。
5.待解决的问题:
有缺陷的数据集
信息冗余
缺乏世界知识
每个段落有多个一般QA对






