FlowNet 论文笔记
FlowNet: Learning Optical Flow withConvolutional Networks
文章下载地址:
http://lmb.informatik.uni-freiburg.de/Publications/2015/DFIB15/
实现代码地址:
http://lmb.informatik.uni-freiburg.de/resources/binaries/
这篇文章已经发布在IEEE International Conference on Computer Vision (ICCV), 2015
1.光流介绍:
百度解析:光流(opticalflow)法是目前运动图像分析的重要方法,它的概念是由Gibso。于1950年首先提出的,是指时变图像中模式运动速度。因为当物体在运动时,它在图像上对应点的亮度模式也在运动。
这种图像亮度模式的表观运动(apparentmotion)就是光流。光流表达了图像的变化,由于它包含了目标运动的信息,因此可被观察者用来确定目标的运动情况。 由光流的定义可以引申出光流场,它是指图像中所有像素点构成的一种二维(2D)瞬时速度场,其中的二维速度矢量是景物中可见点的三维速度矢量在成像表面的投影。所以光流不仅包含了被观察物体的运动信息,而且还包含有关景物三维结构的丰富信息。对光流的研究成为计算机视觉及有关研究领域中的一个重要部分。因为在计算机视觉中,光流扮演着重要角色,在目标对象分割、识别、跟踪、机器人导航以及形状信息恢复等都有着非常重要的应用。从光流中恢复物体三维结构和运动则是计算机视觉研究所面临的最富有意义和挑战性的任务之一。正是由于光流的这种重要地位和作用,使得众多的心理物理学家、生理学家和工程研究人员都加入了它的研究行列。十多年来,他们提出了许多种计算光流的方法,而且新的方法还在不断涌现。
维基百科:光流(Opticalflow or optic flow)是关于视域中的物体运动检测中的概念。用来描述相对于观察者的运动所造成的观测目标、表面或边缘的运动。光流法在样型识别、计算机视觉以及其他影像处理领域中非常有用,可用于运动检测、物件切割、碰撞时间与物体膨胀的计算、运动补偿编码,或者通过物体表面与边缘进行立体的测量等等。
2.光流可视化1:
光流场是图片中每个像素都有一个x方向和y方向的位移,所以在上面那些光流计算结束后得到的光流flow是个和原来图像大小相等的双通道图像。 不同颜色表示不同的运动方向,深浅表示运动的速度。


讲x和y转为极坐标,夹角(actan2(y,x))代表方向,极径(x和y的平方和开根号)代表位移大小,刚好用一下hsv的图像表示。上图的光流可以看到,红色的人在往右边动,那个蓝色的东西在往左上动。
3.摘要:
卷积神经网络(CNN)最近在各种计算机视觉任务中取得了非常大的成功,尤其是那些与识别相关的任务。光流估计也已经不算CNN成功的任务了。在本文中,我们构造了能够解决光流估计问题的CNN作为监督学习任务。我们提出并比较了两种结构:一种是普通的全是卷积层的神经网络,另一个除了卷积层之外还包括一个关联层。由于现有的真实数据集不足以训练CNN,我们生成一个大型综合性的飞行椅数据集。我们表明,对这种不真实的数据进行训练的网络仍然可以很好地适用于现有的数据集,如Sintel和KITTI,以5至10 fps的速率仍然可以实现精度。
4.介绍:
卷积神经网络已成为许多计算机视觉领域的首选方法。 它们成功地应用于分类任务,但最近提出的架构还能够达到像素预测,如单个图像的语义分割或深度估计。在本文中,我们提出端到端训练CNN来学习从一对图像中预测光流场。
虽然光流估计需要精确的每个像素定位,但它也需要获得两个输入图像之间的对应关系。这不仅涉及学习图像特征表示,而且涉及在两个图像中的不同位置处的匹配。在这方面,光流估计与以前CNN的应用有着根本的不同。
由于不清楚这个任务是否可以用标准的CNN架构来解决,我们另外开发了一个能够准确提供匹配能力的相关层的架构。这个架构是端对端训练。我们的想法是利用卷积神经网络在不同的规模和抽象层次上学习强大的特性,并帮助它根据这些特性找到实际的对应关系。关联层顶部的图层学习如何预测这些匹配的流程。令人惊讶的是,这种方式对于网络来说是不必要的,甚至普通的网络也可以学习有竞争力的准确度预测光流。
训练网络来预测光流需要足够大的训练集。虽然数据是在不断地增加,但现有的光流数据集仍然很小,无法达到训练网络的目的。对于真实的视频材料来说,获得光流场的基本信息是非常困难的。以现实的交易数量上,我们生成了一张合成的飞行椅数据集,它由来自Flickr的随机背景图像组成,我们将椅子的分段图像叠加在一起。这些数据与真实数据没什么共同之处,但我们可以用自定义属性生成任意数量的样本。在这些数据上进行训练的CNNs,即使没有进行微调,也能很好地推广到现实的数据集。
利用CNNs高效的GPU实现,我们的方法比大多数竞争对手都要快。网络预测在Sintel数据集的完整分辨率下,每秒可以有10个图像对,在实时方法中达到最高的精确度。
5.本文贡献
1. 提出构建CNNs,以有监督的学习方式解决光流估计任务。提出两种架构,并做了对比实验。
2. 已有光流数据集太小,很多没有标注真实值,本文创建了一个新的光流数据集FlyingChairs,用来充分训练CNN。
6. FlowNet网络结构
神经网络有一个是收缩部分,主要由卷积层组成,用于深度的提取两个图片的一些特征。
另一个是放大部分。pooling降低图片的分辨率,为了提供一个密集的光流预测,增加了一个扩大层,能智能的把光流恢复到高像素。
6.1网络收缩
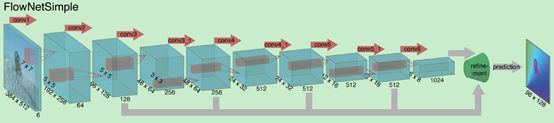
“FlowNetSimple”只有卷积组成的架构。其方法是把输入图像堆叠起来,让它们通过一个非常普通的网络,网络自己决定怎样处理图像对,从而提取光流信息。在这个卷积网络种有九个卷积层,其中的六个stride设置为2,每一层后面还有一个非线性的relu操作,这个网络并没有设置全连接层,所以其不能够把任意大小的图片作为输入,卷积filter随着卷积的深入不断减小,第一个7*7,接下来两个5*5,之后是3*3,featuremaps因为stride是2每层递增两倍。
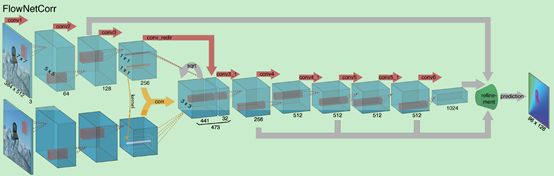
Figure2. The two network architectures: FlowNetSimple (top) and FlowNetCorr (bottom).The green funnel is a placeholder for the expanding refinement part shown inFig 3. The networks includingthe refinement part are trained end-to-end.
“FlowNetCorr”首先要先独立的提取俩图片的特征(使用相同的进程),然后再在高层次中把这两特征结合到一起。 这与正常的匹配的方法一致,先提取两个图片的特征,再对这些特征进行匹配。
在匹配过程中,网络设置了一个“correlation layer”(关联层),在两个特征图中做乘法patch比较。f1、f2分别为两个多通道的特征图,w、h和c是他们的宽度、高度和通道数,这里的关联层作用是利用网络对f1中的每个patch和f2中的每个patch进行比较。
比如:只考虑f1、f2两特征图中的单独patch的比较。f1中以x1为中心的patch和f2中以x2位中心的patch之间的关联就定义为:
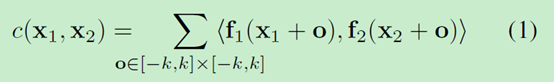
公式(1)如同神经网络的一个卷积层,普通的卷积是与filter进行卷积,这个是两个数据进行卷积,所以它没有可以训练的权重。
方形patch的尺寸为K=2k+1 (k=0)。计算c(x1,x2)涉及到c*K*K次乘积,比较所有的patch组合涉及到w*w*h*h次计算,计算量很大。为了方便计算,限制最大位移d,两个特征图中设置了stride。这样x2的范围为D=2d+1 (d=20)的邻域中计算关联c(x1,x2)。我们用步长s1(1)和s2(2),来全局量化x1,再以x1为中心的邻域内量化 x2。
理论上,关联的结果是4D的:对两个2D位置的每个组合,我们得到一个关联值,即两个分别包含截取patches值的向量的内积。实际上,我们把相对位置用通道表示,这就意味着我们得到了w*h*D*D大小的输出。
6.2网络扩大
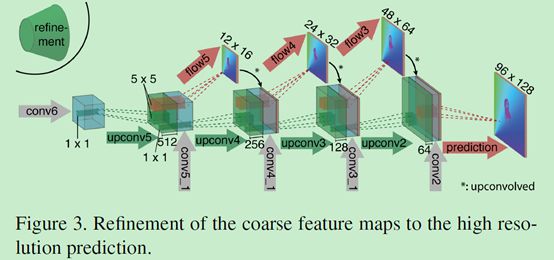
扩大部分主要是由上卷基层组成,上卷基层由unpooling(扩大featuremap,与pooling的步骤相反)和一个卷积组成,我们对featuremaps使用upconvolution,并且把它和收缩部分对应的feature map(灰色箭头)以及一个上采样的的光流预测(红色)联系起来。每一步提升两倍的分辨率,重复四次,预测出来的光流的分辨率依然比输入图片的分辨率要小四倍。这样就能既保留coarser特征图的高层信息,又能保留低层特征图的好的局部信息。
6.3变分优化

我们发现这个分辨率的在采用双线性向上采样相比,并没有显著提升结果。我们替换双线性上采样,采用没有匹配项的变分方法。记为 +v,这种放大方法比简单的双线性上采样计算量大,但是增加了变分方法的优点,使得图像更为平滑,以及得到subpixel-accurate flow filed。
7训练数据集
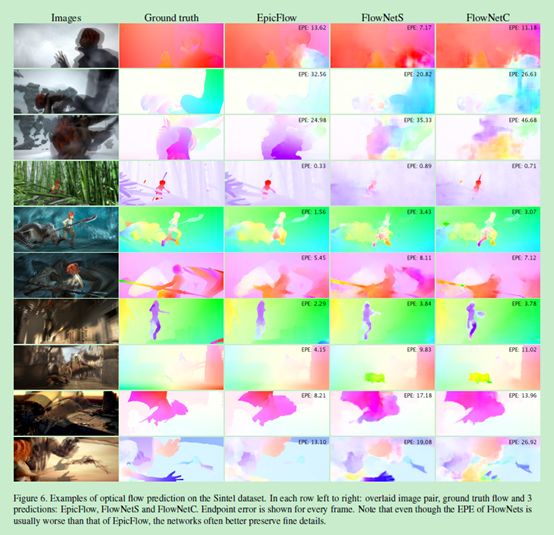
EPE是一种对光流预测错误率的一种评估方式。 指所有像素点的gound truth和预测出来的光流之间差别距离(欧氏距离)的平均值。 可以看见Epicflow 这个很好的预测方法,但在一些大位移的情况下会找不到光流,而两种flownet好于它。
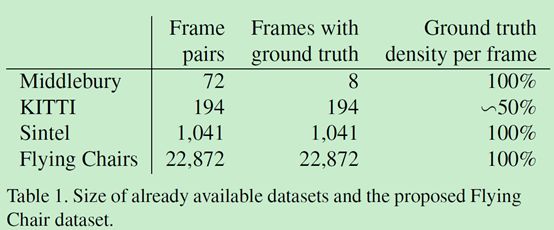
使用了四种数据集,前三种是目前比较常见的训练光流所用的数据集,flying chairs是文章自己创建的数据集。
Middlebury数据集:用于训练的图片对只有8对,从图片对中提取出的,用于训练光流的ground truth用四种不同的技术生成,位移很小,通常小于10个像素。
Kitti数据集:有194个用于训练的图片对,但只有一种特殊的动作类型(类似行车记录仪?),并且位移很大,视频使用一个摄像头和ground truth由3D激光扫描器得出,远距离的物体,如天空没法被捕捉,导致他的光溜ground truth比较稀疏。
Mpi sintel数据集:是从人工生成的动画sintel中提取训练需要的光流groundtruth,是目前最大的数据集,每一个版本都包含1041个可一用来训练的图片对,提供的gt十分密集,大幅度,小幅度的运动都包含。
l sintel数据集包括两种版本:
l sintel final:包括运动模糊和一些环境氛围特效,如雾等。
l sintel clean:没有上述final的特效。
现在的这些数据集在物体和运动特征上都不相同,为了增加正确率,我们针对不同的数据集对网络进行优化,相关的优化方法就是fine-tunning,记为+ft。用于训练大规模的cnns,sintel的dataset依然不够大,所以创建了flying chairs数据集。
7.1 flying chairs数据集

这一数据集背景是来自flickr的标签为‘city’,‘landscape’,‘mountain’的1024*768像素的图片,剪切成四分之一,用512*384作为背景。前景是可以得到的可以生成的3d椅子模型,从这些模型中去掉一些相似的椅子模型,留下809种椅子,每一种有62个视角。为了产生运动信息,产生第一张图片的时候会随机产生一个位移变量,与背景图片与椅子位移相关,再通过这种位移变量产生第二个图片和光流。每一个图像对的这些变量,包括,椅子的类型,数量,大小,和产生的位置都是随机的,位移向量也是随机的产生的。数据增多的方法包括给原图像位移,反转,方法,加高斯噪音,改变亮度,对比对,gamma值和,颜色,这一操作都用GPU生成。
训练cnn使用是修改版的caffe 框架,用adam作为优化方式,每一个像素都是训练样本。
8实验结果

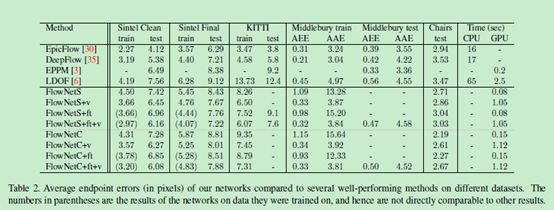
该作者的其他文章:
http://lmb.informatik.uni-freiburg.de/research/convnets/
相关视频资料(需要跳墙):
https://www.youtube.com/channel/UC351jap1wiOJvKXr3mhODlg
注释:1 光流可视化图文引用
https://blog.csdn.net/u013010889/article/details/71189271



