OpenAI 发布完整版游戏强化学习研究平台 Gym Retro

本文发布于 OpenAI 官方博客,AI 研习社将原文编译如下:
我们发布了用于游戏研究的强化学习平台完整版 Gym Retro,支持的游戏从大约 70 多个雅达利和 30 多个世嘉游戏扩展到各种仿真器支持的 1000 多个游戏。同时我们还发布了用于增加新游戏的工具。
我们使用 Gym Retro 来研究增强学习算法和泛化。RL 之前的研究主要集中在优化 Agent 解决单个任务上。通过 Gym Retro,我们可以研究内部概念相似但外观表现不同的游戏之间泛化的能力。

此版本包括世嘉创世纪和世嘉 Master System 的游戏,以及任天堂的 NES,SNES 和 Game Boy 的游戏。Gym Retro 还包括对世嘉 Game Gear,任天堂Game Boy Color,任天堂 Game Boy Advance 和 NEC TurboGrafx 的初步支持。一些已发布的游戏集成(包括 Gym Retro 的数据/实验文件夹中的那些游戏)处于测试状态 - 请您尝试一下并让我们知道是否遇到任何 bug。由于涉及到大规模的变更,所以代码暂时只能在部分 branch 上可用。为了避免破坏参赛者的代码,在比赛结束之前,我们不会合并 branch(https://github.com/openai/retro/tree/develop)。
正在进行的 Retro 比赛和我们近期的技术报告(https://arxiv.org/abs/1804.03720)专注于在同一游戏不同级别之间进行泛化的比较简单的问题。完整的 Gym Retro 数据集推进了这一想法,并使研究不同游戏之间的泛化难题成为可能。不过,数据集的规模和个人游戏的难度使其成为一项艰巨的挑战,我们期待着分享明年的研究进展。我们也希望由 Retro 竞赛参与者开发的一些解决方案可以扩展并应用于完整的 Gym Retro 数据集上。
集成工具
我们发布了用于整合新游戏的工具,如果您拥有游戏的 ROM,此工具可让您轻松保存状态、查找内存位置以及设计强化学习 Agent 能够解决的场景问题。我们为想要添加新游戏的开发者写了份使用指南。
新工具还支持录制和播放视频文件功能,用来记录游戏中所有的按键输入。这些文件很小,因为它们只需记录按键的初始状态和按键的顺序,而不用逐帧记录。这些文件可以让强化学习 Agent 的行为可视,并且可以将玩家的操作记录下来作为训练数据。
Farming 奖励
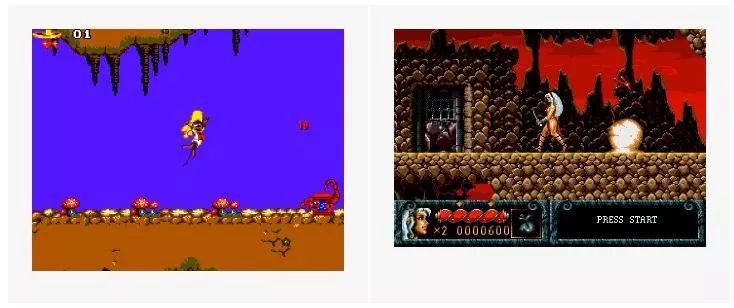
在开发 Gym Retro 时,我们发现很多游戏 Agent 学习 Farm 奖励(游戏分数的增加)而不是完成隐藏的任务。
在上面的图片(查看完整视频请访问原网站)中,Cheese Cat-Astrophe(左侧)和 Blades of Vengeance(右侧)中的角色陷入无限循环,因为它们能够通过这种方式快速获得奖励。这凸显了我们之前说的情况(https://blog.openai.com/faulty-reward-functions/),我们给强化学习算法的相对简单的奖励函数,例如通过最大化游戏中的分数,可能导致不良行为。
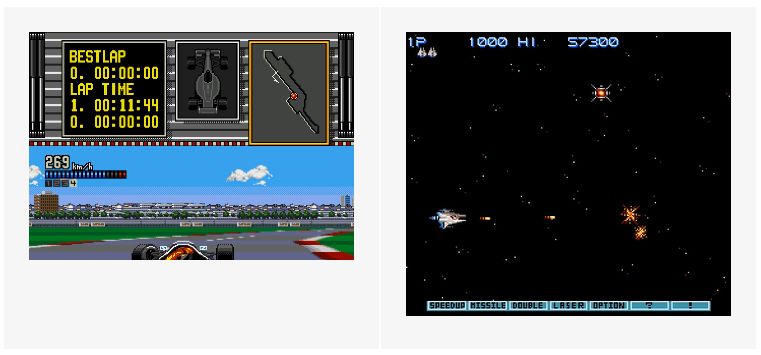
对于密集(频繁和增量)奖励的游戏来说,主要的困难来自需要快速反应时间的情况,这要求 PPO 等强化学习算法表现得非常好。
在像沙罗曼蛇这样的游戏中(右图),角色可以通过射杀敌人得分,所以获得奖励和开始学习很容易。在这样的游戏中生存是基于你躲避敌人的能力,这对强化学习算法来说没有问题,因为强化学习算法可以逐帧地分析游戏。
对于有稀疏奖励或节奏比较慢的游戏,现有的算法很难分析。Gym Retro 数据集中的许多游戏都有稀疏的奖励或需要规划策略,因此处理完整数据集可能需要尚未开发的新技术。
Gym Retro Github:
https://github.com/openai/retro
原文链接:
https://blog.openai.com/gym-retro/

从Python入门-如何成为AI工程师
BAT资深算法工程师独家研发课程
最贴近生活与工作的好玩实操项目
班级管理助学搭配专业的助教答疑
学以致用拿offer,学完即推荐就业

新人福利
关注 AI 研习社(okweiwu),回复 1 领取
【超过 1000G 神经网络 / AI / 大数据资料】
OpenAI 启动迁移学习比赛,一起来玩刺猬索尼克游戏吧
▼▼▼


