为什么Batch Normalization那么有用?
点击上方“CVer”,选择加"星标"或“置顶”
重磅干货,第一时间送达

作者:autocyz
https://zhuanlan.zhihu.com/p/52749286
本文已由原作者授权,未经允许,不得二次转载
本文是《How Does Batch Normalization Help Optimization?》的一篇阅读笔记。文章很好,通过对比实验帮助我们理解why BN work!

arXiv:https://arxiv.org/abs/1805.11604
先上结论,再做分析:
1. 没有证据表明BN的work,是因为减少了ICS(Interval Covariate Shift)。
2. BN work的根本原因,是因为在网络的训练阶段,其能够让优化空间(optimization landscape)变的平滑。
3. 其他的normalization技术也能够像BN那样对于网络的训练起到作用。
一、BN和ICS的关系
在文章Batch Normalization:Accelerating Deep Network Training by Reducing Internal Covariate Shift中,其对与ICS是这样解释的:由于前一层的参数更新,所以这一层的输入(前一层的输出)的分布会发生变化,这种现象被称之为ICS。同样,这篇文章的观点认为BN work的真正原因,在与其将数据的分布都归一化到均值为0,方差为1的分布上去。因此,每一层的输入(上一层输出经过BN后)分布的稳定性都提高了,故而整体减小了网络的ICS。
但是,本文作者就提出了两个疑问:
1、BN work的原因是否真的与ICS有关?
2、BN层是否真的能够稳定输入分布?
1.1、BN是否真的与ICS有关?
对比实验:
在训练阶段,使用一下三种训练方法进行训练
No BN
标准的BN
noisy BN (在标准的BN层后,加上均值不为0,方差不为1的noisy,并且在每个训练step都改变noisy的分布,降低了输入分布的稳定性,使得网络的ICS变大)
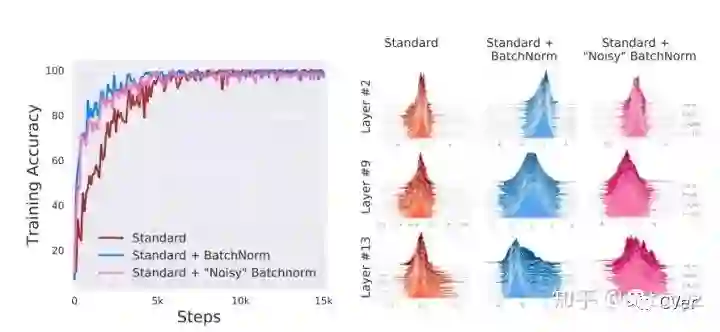
观察上图左,可以发现加了noisy BN和标准的BN在training accuracy和收敛速度上几乎没有差异,并且都优于不加BN的方法。
结论:
没有证据表明BN的性能是因为提高了输入分布的稳定性。即BN与ICS无关。
1.2、BN是否能够减少ICS
对比实验:(具体参看文章section 2.2)
训练一个(25-layer deep linear network, DLN),即去除网络中的所有非线性激活层,只保留线性层,这么做的目的是为了在统计ICS时,减少非线性激活层对数据分布的影响。
最后发现,带BN层的DLN不像预想的那样减少了ICS,反而增大了ICS。
结论:
从优化的角度来看,通过使用BN来控制layer的输入分布并不能减少ICS
二、Why does BN work?
Ioffe and Szegedy在文章中说,BN可以防止梯度爆炸或弥散、可以提高训练时模型对于不同超参(学习率、初始化)的鲁棒性、可以让大部分的激活函数能够远离其饱和区域。所有这些BN的性质,都可以帮助我们快速鲁棒的训练网络。但是该怎么解释呢?
2.1 BN的平滑影响
作者认为,BN能够work的真正原因在于BN重新改变了优化问题,使得优化空间变得非常平滑。
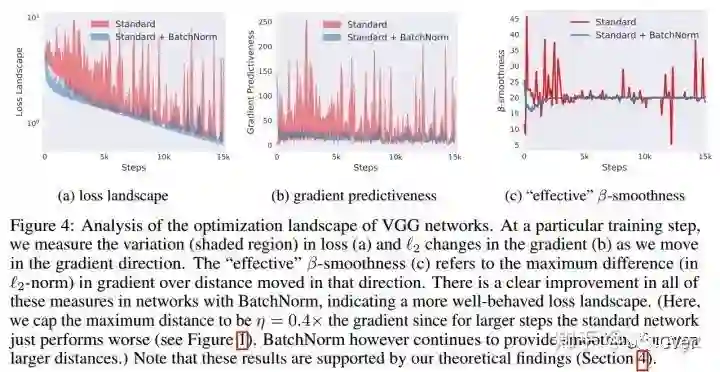
对于没有BN的神经网络,其loss函数是不仅非凸,并且还有很多flat regions、sharp minimal。这就使得那些基于梯度的优化方法变得不稳定,因为很容易出现过大或者过小的梯度值。
观察上图,可以发现,在使用了BN后,loss的变化变得更加稳定,不会出现过大的跳动;同样,梯度也变得更加平滑。
2.2 是否BN是最好或者唯一的方法来对优化空间进行平滑
对比实验:
不使用BN
使用标准BN
使用L1 归一化方法
使用L2 归一化方法
使用L ∞ 归一化方法
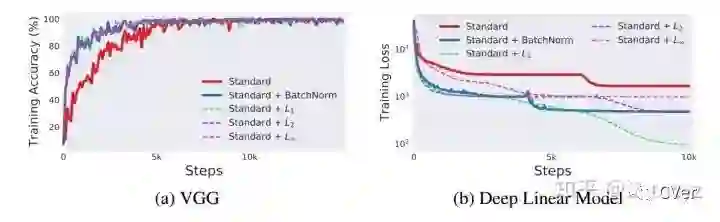
结论:
很多normalization的方法都可以达到BN的效果,甚至更好。
2.3 理论分析
文章理论分析部分做了很多定理和推论,这里就不做具体分析啦。
---End---
想要了解最新最快最好的论文速递、开源项目和干货资料,欢迎加入CVer学术交流群。涉及图像分类、目标检测、图像分割、人脸检测&识别、目标跟踪、GANs、学术竞赛交流、Re-ID、风格迁移、医学影像分析、姿态估计、OCR、SLAM、场景文字检测&识别和超分辨率等方向。

扫码进群
这么硬的论文速递,麻烦给我一个好看
麻烦给我一个好看!


