State Abstraction as 压缩 in Apprenticeship Learning
code:
State Abstraction as Compression in Apprenticeship Learning https://github.com/david-abel/rl_info_theory ref infobot;
State Abstractions for Lifelong Reinforcement Learnin https://david-abel.github.io/papers/lifelong_sa_icml_18.pdf
State Abstraction as Compression in Apprenticeship Learning
David Abel1 and Dilip Arumugam2 and Kavosh Asadi1 andYuu Jinnai1 and Michael L. Littman1 and Lawson L.S. Wong3
1: Department of Computer Science, Brown University
2: Department of Computer Science, Stanford University
3: College of Computer and Information Science, Northeastern University
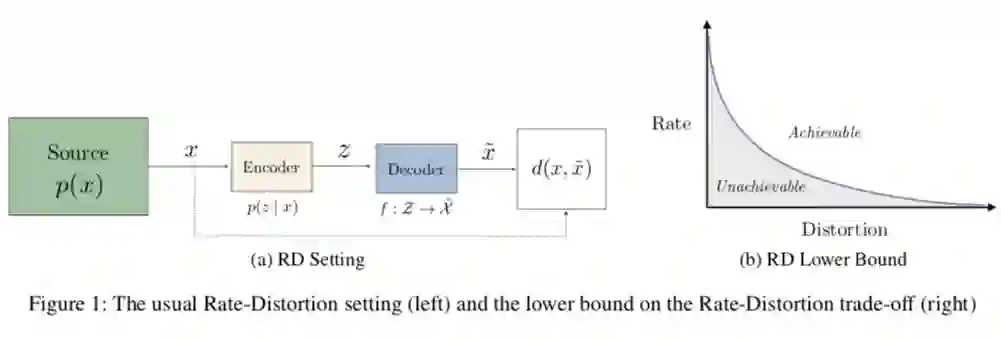
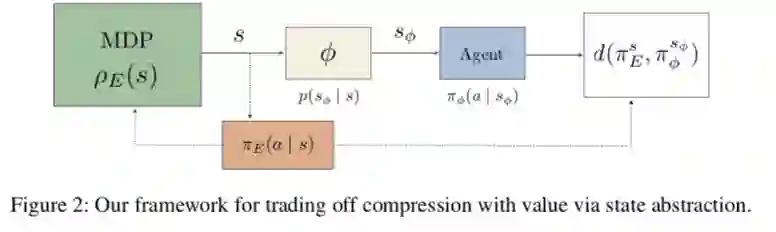
Abstract
State abstraction can give rise to models of environments that are both compressed and useful, thereby enabling efficient sequential decision making. In this work, we offer the first formalism and analysis of the trade-off between compression and performance made in the context of state abstraction for Apprenticeship Learning. We build on Rate-Distortion the- ory, the classic Blahut-Arimoto algorithm, and the Informa- tion Bottleneck method to develop an algorithm for com- puting state abstractions that approximate the optimal trade- off between compression and performance. We illustrate the power of this algorithmic structure to offer insights into ef- fective abstraction, compression, and reinforcement learning through a mixture of analysis, visuals, and experimentation.
1 Introduction
Reinforcement Learning (RL) poses a challenging problem. Agents must learn about their environment through high- dimensional and often noisy observations while receiving sparse and delayed evaluative feedback. The ability to un- derstand one’s surroundings well enough to support effec- tive decision making under these conditions is a remarkable feat, and arguably a hallmark of intelligent behavior. To this end, a long-standing goal of RL is to endow decision-making agents with the ability to acquire and exploit abstract models for use in decision making, drawing inspiration from human cognition (Tenenbaum et al. 2011).
One path toward realizing this goal is to make use of state abstraction, which describes methods for compressing the environment’s state space to distill complex problems into simpler forms (Dietterich 2000b; Andre and Russell 2002; Li, Walsh, and Littman 2006). Critically, the degree of com- pression induced by an abstraction trades off directly with its capacity to represent good behavior. If the abstraction throws away too much information, the resulting abstract model will fail to preserve essential characteristics of the original task (Abel, Hershkowitz, and Littman 2016). Thus, care must be taken to identify state abstractions that balance between an appropriate degree of compression and adequate representational power.
Information Theory offers foundational results about the limits of compression (Shannon 1948). The core of the theory clarifies how to communicate in the presence of noise, culminating in seminal results about the nature of commu- nication and compression that helped establish the science and engineering practices of computation. Of particular rel- evance to our agenda is Rate-Distortion theory, which stud- ies the trade-off between a code’s ability to compress (rate) and represent the original signal (distortion) (Shannon 1948; Berger 1971). Cognitive neuroscience has suggested that perception and generalization are tied to efficient compres- sion (Attneave 1954; Sims 2016; 2018), termed the “efficient coding hypothesis” by Barlow (1961).
The goal of this work is to understand the role of information-theoretic compression in state abstraction for sequential decision making. We draw a parallel betweenstate abstraction as used in reinforcement learning and com- pression as understood in information theory. We build on the seminal work of Shannon (1948), Blahut (1972), Ari- moto (1972) and Tishby, Pereira, and Bialek (1999), and draw inspiration from related work on understanding the re- lationship between abstraction and compression (Botvinick et al. 2015; Solway et al. 2014). While the perspective we introduce is intended to be general, we focus our study in two ways. First, we investigate only state abstraction, de- ferring discussion of temporal (Sutton, Precup, and Singh 1999), action (Hauskrecht et al. 1998), and hierarchical ab- straction (Dayan and Hinton 1993; Dietterich 2000a) to fu- ture work. Second, we address the learning problem when a demonstrator is available, as in Apprenticeship Learn- ing (Atkeson and Schaal 1997; Abbeel and Ng 2004; Argall et al. 2009), which simplifies aspects of our model.
Concretely, we introduce a new objective function that explicitly balances state-compression and performance. Our main result proves this objective is upper bounded by a vari- ant of the Information Bottleneck objective adapted to se- quential decision making. We introduce Deterministic In- formation Bottleneck for State abstraction (DIBS), an algo- rithm that outputs a lossy state abstraction optimizing the trade-off between compressing the state space and preserv- ing the capacity for performance in that compressed state space. We conduct experiments to showcase the relationship between compression and performance captured by the al- gorithm in a traditional grid world and present an extension to high-dimensional observations via experiments with the Atari game Breakout.





