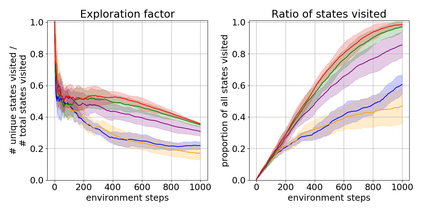
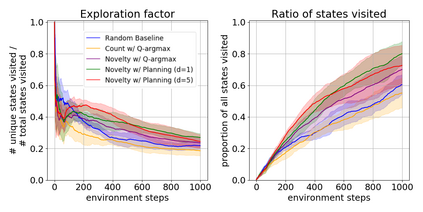
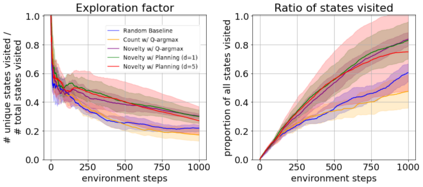
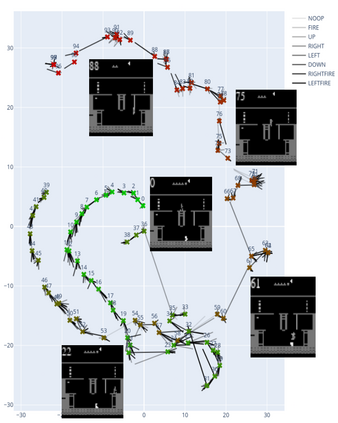
We present a new approach for efficient exploration which leverages a low-dimensional encoding of the environment learned with a combination of model-based and model-free objectives. Our approach uses intrinsic rewards that are based on the distance of nearest neighbors in the low dimensional representational space to gauge novelty. We then leverage these intrinsic rewards for sample-efficient exploration with planning routines in representational space for hard exploration tasks with sparse rewards. One key element of our approach is the use of information theoretic principles to shape our representations in a way so that our novelty reward goes beyond pixel similarity. We test our approach on a number of maze tasks, as well as a control problem and show that our exploration approach is more sample-efficient compared to strong baselines.
翻译:我们提出了一个高效探索的新办法,该办法利用一个低维的环境编码,结合基于模型和无模型的目标。我们的办法利用基于低维代表空间近邻距离的内在奖励来测量新事物。然后我们利用这些抽样有效探索的内在奖励,规划代表空间的例行工作,以获得微薄的奖励。我们办法的一个关键要素是利用信息理论原则来塑造我们的形象,使我们的新颖的奖励超越像素相似性。我们测试了我们在若干迷宫任务上的做法,以及控制问题,并表明我们的勘探方法比强的基线更具有样本效率。