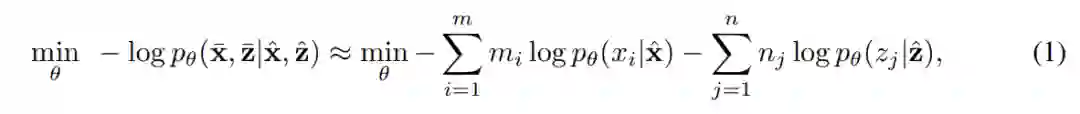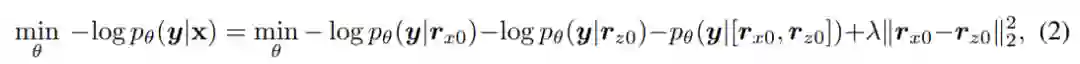自谷歌 BERT 模型问世以来,各式各样的 BERT 变体模型在自然语言理解任务上大显身手。近日,字节跳动 AI 实验室李航等研究者提出了一种新型多粒度 BERT 模型,该模型在 CLUE 和 GLUE 任务上的性能超过了谷歌 BERT、Albert、XLNet 等。
BERT 等预训练语言模型在自然语言理解(Natural Language Understanding, NLU)的许多任务中均表现出了卓越的性能。
可以看到,模型中的 token 通常是细粒度的,对于像英语这样的语言,token 是单词或子词;对于像中文这样的语言,则是单个汉字。例如在英语中有多个单词表达式构成的自然词汇单元,因此使用粗粒度标记化(tokenization)似乎也是合理的。实际上,细粒度和粗粒度标记化对于学习预训练语言模型都各有利弊。
近日,字节跳动 Xinsong Zhang、李航两位研究者在细粒度和粗粒度标记化的基础上,提出了一种新的预训练语言模型,他们称之为 AMBERT(一种多粒度 BERT)。在构成上,AMBERT 具有两个编码器。
对于英文,AMBERT 将单词序列(细粒度标记)和短语序列(粗粒度标记)作为标记化后的输入,其中使用一个编码器处理单词序列,另一个编码器处理短语序列,并利用两个编码器之间的共享参数,最终分别创建单词和短语的上下文表示序列。
![]()
论文链接:https://arxiv.org/pdf/2008.11869.pdf
研究团队已经在一些中文和英文的基准数据集(包括 CLUE、GLUE、SQuAD 和 RACE)上进行了实验。实验结果表明,AMBERT 的性能几乎在所有情况下都优于现有的最佳性能模型。尤其是对于中文而言,AMBERT 的提升效果显著。
![]()
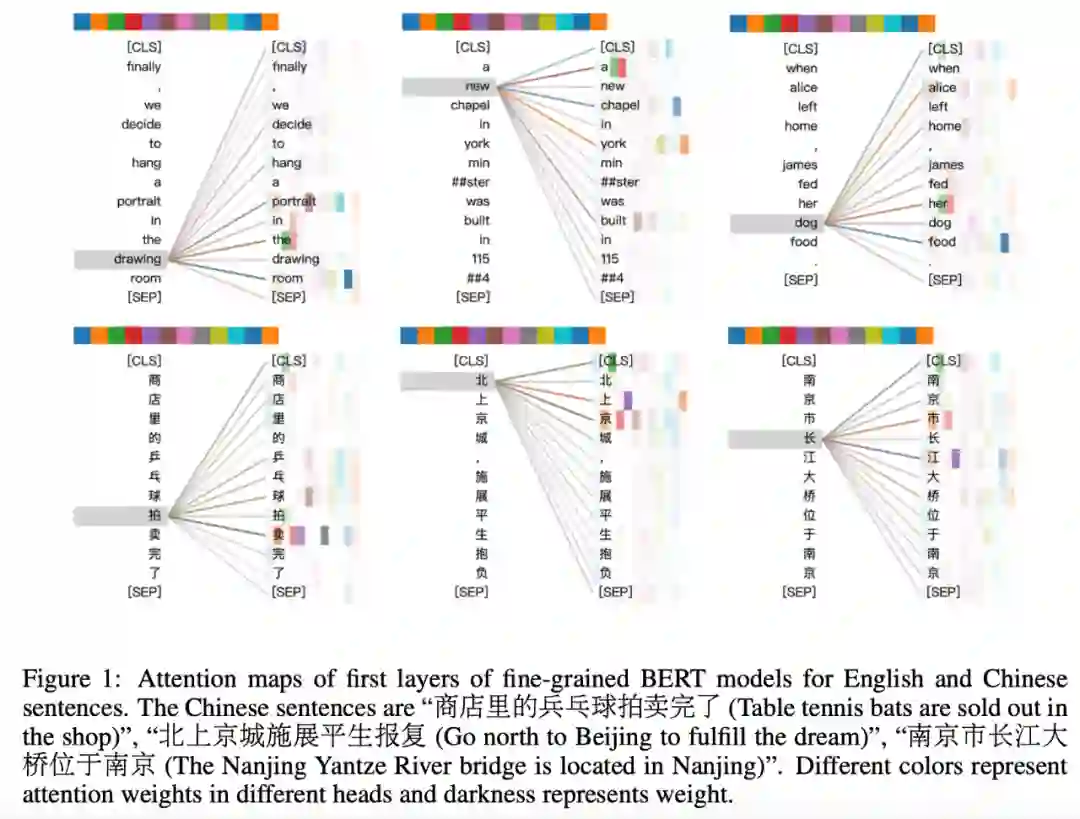
我们首先看一下中英文任务中细、粗粒度模型层的注意力图。
下图 1 显示了适用于中英文句子的细粒度模型的首层注意力图。可以看到,某些 token 不恰当地出现在句子的其他 token 上。
例如在英文句子中,「drawing」、「new」和「dog」分别对「portrait」、「york」和「food」这几个词有高注意力权重,但这是不合适的。而在中文句子中,汉字「拍」、「北」和「长」分别对「卖」「京」「市」有高注意力权重,这也是不合适的。
![]()
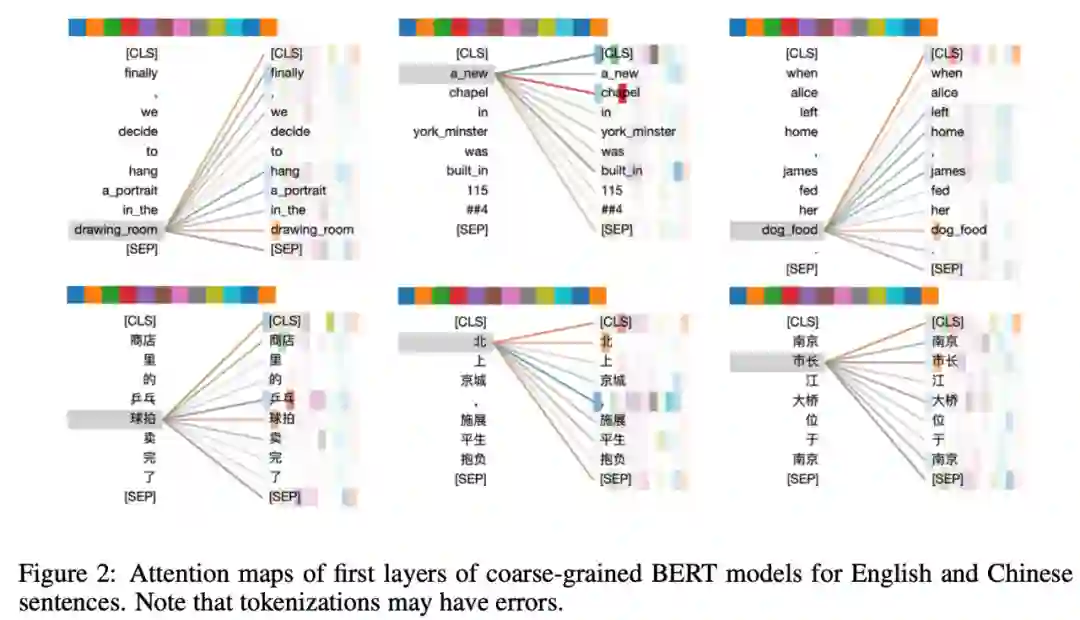
下图 2 显示了中英文相同句子粗粒度模型的首层注意力图。
在英文句子中,单词组成的短语包括「drawing room」、「york minister」和「dog food」,前两个句子中的注意力是恰当的,但最后一个句子则因为不正确的标记化而出现了不恰当的注意力。类似地,在中文句子中,高注意力权重的「球拍(bat)」和「京城(capital)」都是合理的,但「市长(mayor)」不合理。但请注意:错误的标记化是不可避免的。
![]()
接下来详细解读 AMBERT 模型的细节和实验结果。
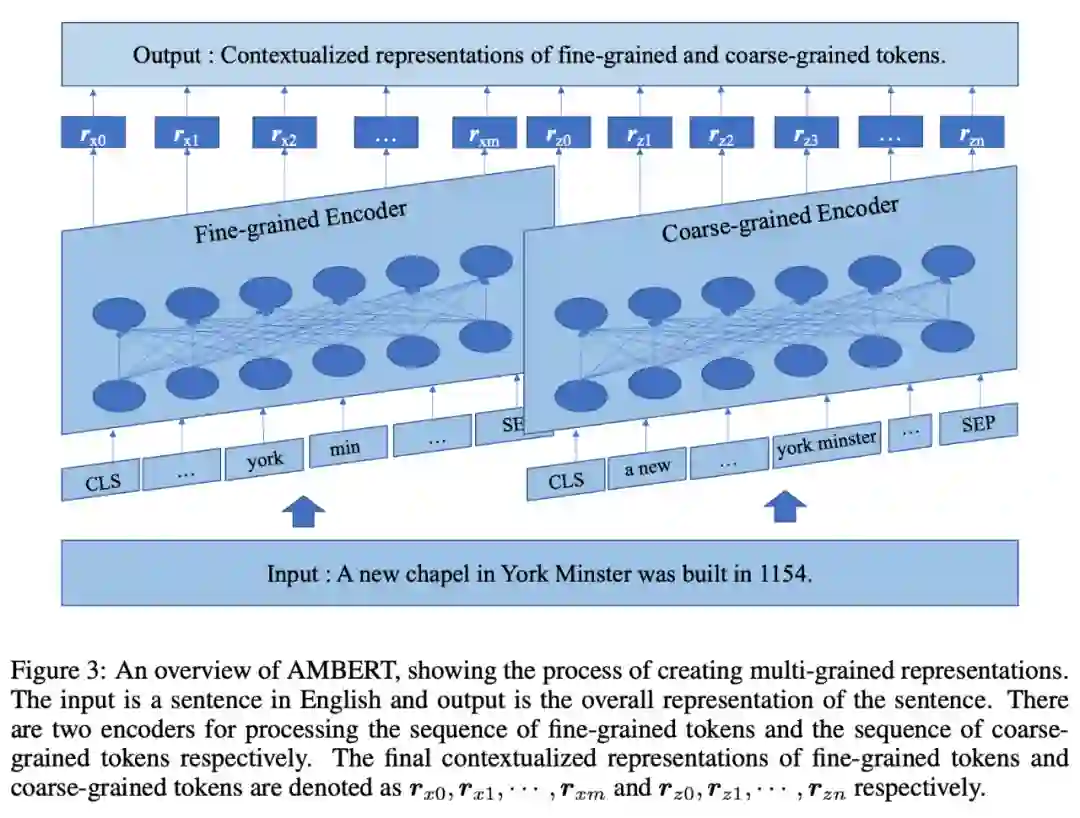
研究者在下图 3 中给出了 AMBERT 的整体框架。AMBERT 以文本作为输入,其中,文本要么是单个文档中的长序列,要么是两个不同文档中两个短序列的级联。接着在输入文本上进行标记化,以获得细、粗粒度的 token 序列。
![]()
具体来说,AMBERT 具有两个编码器,分别用于处理细、粗粒度 token 序列。每个编码器具有与 BERT(Devlin 等人,2018)或 Transformer 编码器(Vaswani 等人,2017)完全相同的架构。
此外,两个编码器在每个对应层共享相同的参数,但两者的嵌入参数不同。细粒度编码器在对应层上从细粒度 token 序列中生成上下文表示,而粗粒度编码器在对应层上从粗粒度 token 序列中生成上下文表示。
最后,AMBERT 分别输出细、粗粒度 token 的上下文表示序列。
AMBERT 的预训练主要基于掩码语言建模(mask language modeling, MLM)进行,并从细、粗粒度两个层面展开。出于比较的目的,研究者在实验中只使用了预测下一个句子(next sentence prediction, NSP)。
![]()
在分类任务上的 AMBERT 微调中,细、粗粒度编码器分别创建特定的 [CLS] 表示,并且这些表示都用于分类任务。微调过程被定义为以下函数的优化:
![]()
类似地,我们可以对跨度检测(span detection)任务上的 AMBERT 进行微调,其中细粒度 token 的表示与对应粗粒度 token 的表示实现了级联。
研究者还提出了 AMBERT 的两种替代模型 AMBERT-Combo 和 AMBERT-Hybrid,它们也依赖于多粒度的标记化。研究者在实验部分也将三者进行了比较。
在实验部分,研究者分别在中英文基准数据集上,将 AMBERT 与细、粗粒度 BERT 基线以及 AMBERT-Combo 和 AMBERT-Hybrid 替代模型进行了比较。
下表 1 展示了分类任务的结果。可以看到,AMBERT 将 BERT 基线方法的平均得分提升了约 1.0%,并且其性能优于 AMBERT-Combo 和 AMBERT-Hybrid 替代模型。
![]()
下表 2 展示了机器阅读理解(Machine Reading Comprehensive, MRC)任务上的结果。可以看到,AMBERT 将 BERT 基线的平均得分提升了约 3.0%。
![]()
此外,研究者还在 CLUE 排行榜上将 AMBERT 与当前最优模型进行了比较,结果如下表所示:
![]()
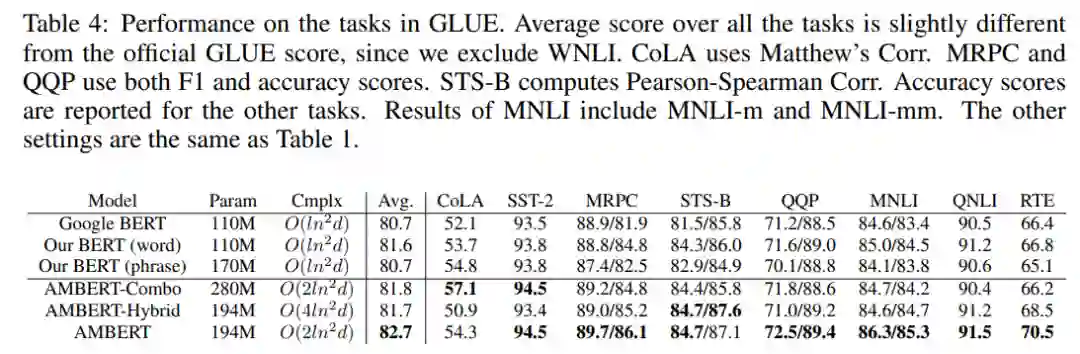
研究者在 GLUE 任务上将 AMBERT 与 BERT 模型以及 AMBERT-Combo、AMBERT-Hybrid 替代模型进行了比较。Google BERT 的结果出自原论文,Our BERT 的结果由研究者获得。
如下表 4 所示,AMBERT 在大多数任务上的性能优于其他模型,并且 AMBERT 等多粒度模型能够取得优于单粒度模型的结果。在多粒度模型中,AMBERT 在参数和计算量更少的情况下依然实现了最佳性能。
![]()
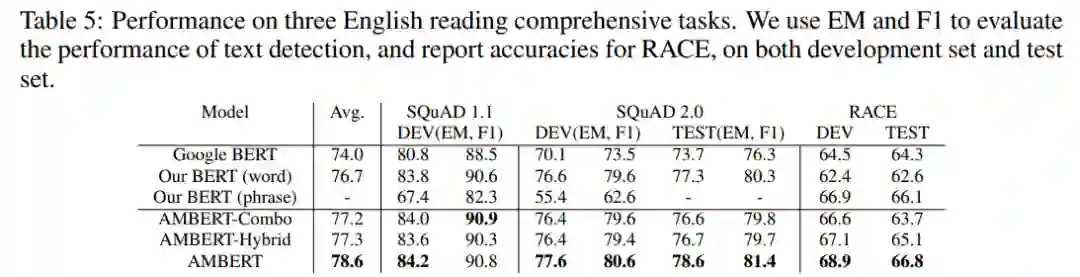
研究者在 SQuAD 任务上将 AMBERT 与其他 BERT 模型进行了比较。Google BERT 结果出自原论文或者由研究者使用官方代码运行获得。
如下表 5 所示,AMBERT 在 SQuAD 任务上显著优于 Google BERT。Our BERT (word)通常表现良好,Our BERT (phrase)在跨度检测任务上表现糟糕。
此外,在RACE任务上,AMBERT在所有开发集和测试集的基线中表现最好。
AMBERT是最佳的多粒度模型。
![]()
最后,研究者在 GLUE 和 MRC 任务上将 AMBERT 与 SOTA 模型进行了比较,结果如下表 6 所示:
![]()
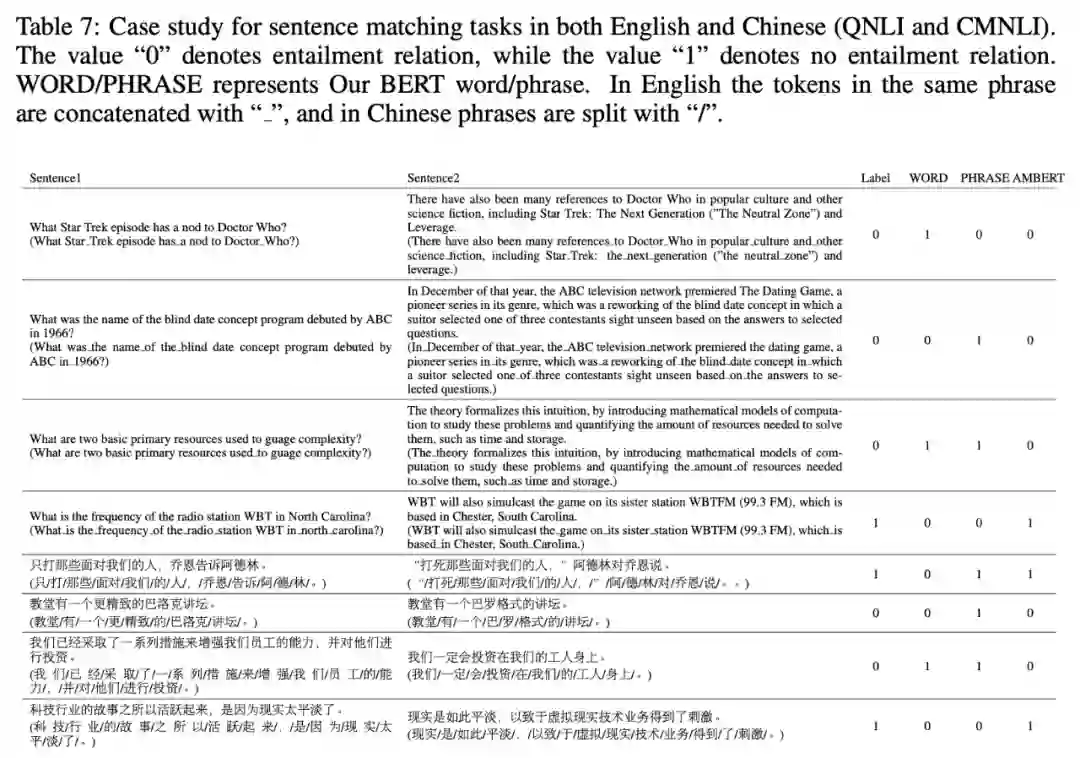
研究者对 BERT 和 AMBERT 的结果进行了定性研究,结果如下表 7 所示,研究者给出了蕴含任务 QNLI 和 CMNLI 的一些随机示例。其中数值「0」表示有蕴含关系,数值「1」表示无蕴含关系。WORD/PHRASE 表示 Our BERT 的词或者短语。
![]()
机器之心联合旷视科技开设线上公开课:
零基础入门旷视天元MegEngine
,通过6次课程帮助开发者入门深度学习开发。
9月1日,旷视科技移动业务团队研究员王鹏将带来第6课《部署进阶:推理端优化》,将介绍 MegEngine 框架中模型量化方案、量化相关模块和使用方法,并实例讲解使用MegEngine进行模型量化的流程。欢迎大家入群学习。
![]()
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com