专栏 | 李飞飞主讲斯坦福大学 CS231n 课程笔记:K 近邻算法&线性分类

AI 科技评论按:本门课程是李飞飞主讲的斯坦福 CS231n 计算机视觉课程,吉林大学珠海学院的赵一帆进行了笔记方面的整理。笔记如有出错,请及时告知。本文对应章节:数据驱动的图像分类方式:K 最近邻与线性分类器。上一章节:计算机视觉历史回顾与介绍
回到图片上来讨论KNN:

可以看到,它实际上表现的不是很好。这里标记了红色和绿色,图像分类正确与否取决于它的最近邻值,可以看到 KNN 的表现效果不是很好,但如果使用一个更大的 K 值,那么投票操作的结果就可能会达到前三名或者前五名,甚至包括所有的数据范围。
用这种方法来检索相邻数据时,可以想象到这样会对噪声产生更大的鲁棒性。还有另外一个选择,就是当使用 K-近邻算法时,确定应该如何比较相对邻近数据距离值传递不同。

对于迄今为止的例子,已经展示了已经讨论过的 L1 距离,它是像素之间绝对值的总和,另一种常见的选择是 L2 距离,也是欧式距离,即取平方和的平方根,并把这个作为距离。
选择不同的距离度量实际上是一个非常有趣的话题,因为在不同维度里,会在预测的空间里对底层的几何或拓扑结构做出不同的假设。
相对于下面所示的 L1 距离和 L2 距离实际上是一个根据距离的这个围绕着原点的方形和圆,这个方形上的每一个点在 L1 上是与原点等距的,而距离上类似的会是一个圆,它看起来像你所期望的。
这两种方法之间特别指出一件有趣的问题:
L1 距离取决于你选择的坐标系统,如果你选择坐标轴,将会改变点之间的 L1 距离,而改变坐标轴对 L2 距离毫无影响,无论在怎么样的坐标下,L2 距离是一个确定的值。
如果输入一些特征向量,向量中的一些值有一些重要意义的任务,那么 L1 也许会更加适合。
但如果它只是某个空间中的一个通用向量,而不知道其中的不同元素的意义,那么 L2 会更适合些。
还有一点:
通过使用不同的距离度量,可以将 K-最近邻分类器泛化到许多不同的数据类型上,而不仅仅是向量,不仅仅是图像。例如,假设想对文本进行分类,那么只需要用 KNN 指定一个距离函数,这个函数可以测量两段话或者两段话之间的距离。因此,简单的通过指定不同的距离度量,便可以很好地将这个算法应用在基本上任何类型的数据上。
选择不同的距离度量在几何学中是一个有趣的问题。

在左边可以看到一组 L1 距离,右侧是使用 L2 距离。
可以看出,分类器的决策边界其实是相差很大的:
L1 的决策边界趋向于随坐标轴,这是因为 L1 取决于对坐标的选择;
L2 对距离的排序并不会受到坐标的影响,只是把边界放置在存在最自然的地方。
如何根据问题和数据来确定这些超参数?
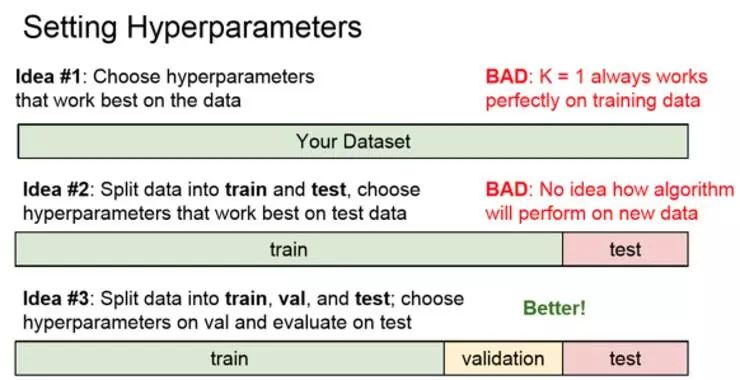
选择能对训练集给出高准确率、表现最佳的超参数。这其实是一种非常糟糕的想法,千万不要这么做。
例如,在之前的 K-最近邻分类算法中,假设 K=1,总能完美分类训练数据,所以如果采用这一策略总是选择 K=1,但是正如之前案例所见的,在实践中让 K 取更大的值,尽管会在训练集中分错个别数据,但对于在训练集中未出现过的数据分类性能更佳,归根到机器学习中,关心的并不是要尽可能拟合训练集,而是要让分类器在训练集以外的未知数据上表现更好。
另一个想法是把数据分成两部分,一部分是训练集,另一部分是测试集,然后在训练集上用不同的超参数来训练算法,然后将训练好的分类器用在测试集上,再选择一组在测试集上表现最好的超参数。
这似乎是个合理的策略,但事实上也非常糟糕。因为机器学习的目的是了解算法表现如何,所以测试集只是一种预估的方法,即在没遇到的数据上算法表现会如何,如果采用这种不同的超参数训练不同算法的策略,然后选择在测试集上表现最好的超参数,那么很有可能选择了一组超参数,只是让算法在这组测试集上表现良好,但是这组测试集的表现无法代表在权限的未见过的数据上的表现。
更常见的做法是将数据分为三组:大部分作为训练集,然后一个验证集,一个测试集。在训练集上用不同的超参数训练,在验证集上进行评估,然后选择一组评估最好的参数,然后再把这组数据放到测试集中跑一跑,这才是要写到论文中的数据,这才是算法在未见过的新数据上的表现。
还有一个设计超参数的方法是交叉验证。
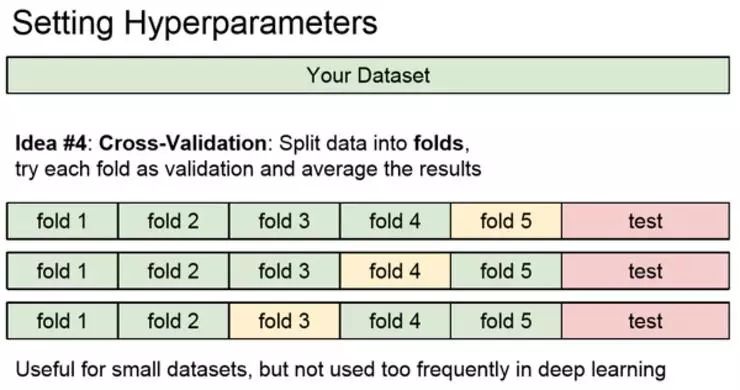
这个在小数据集上比较常用,在深度学习中并不怎么常用。它的理念是,取出测试集数据,将整个数据集保留部分作为最后使用的测试集,对于剩余的数据分成很多份,在这种情况下,轮流将每一份都当做验证集。
经过交叉验证,会得到这样一张图:
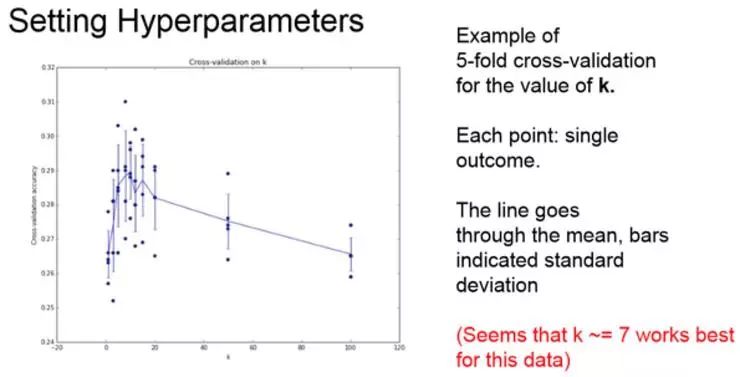
x 轴表示 K-近邻分类器中参数 K 值,y 轴表示分类器对于不同 K 在数据上的准确率。在这个例子中,用了 5 次交叉验证,也就是说对于每个 K 值,都对算法做了 5 次测试来了解表现如何。
使用 K 次交叉验证也许是一个量化它的好方法,可以观察到算法在不同验证集上表现的方差,同时,不光是知道哪样更好,还能看到算法效果的分布。

其实,KNN 在图像分类中很少用到,原因包括刚才谈到的所有问题。一是它在测试时运算时间很长,这和刚刚提到的要求不符;另一个问题在于,像欧几里得距离或者 L1 距离这样的衡量标准用在比较图片上实在不太合适。这种向量化的距离函数不太适合表示图像之间视觉的相似度。
图中左边图的女生和右边三张经过不同处理的图片,如果计算他们和原图的欧式距离,会得到相同的答案,这并不是想要的。可以感觉出来 L2 不适合表示图像之间视觉感知的差异。
还有一个问题称之为维度灾难,如果还记得对 K 近邻的描述,它有点像训练点把样本空间分成几块,这意味着,如果希望分类器有更好的结果,需要训练数据能够密集地分布在空间中。否则最邻近点的实际距离可能会很远。
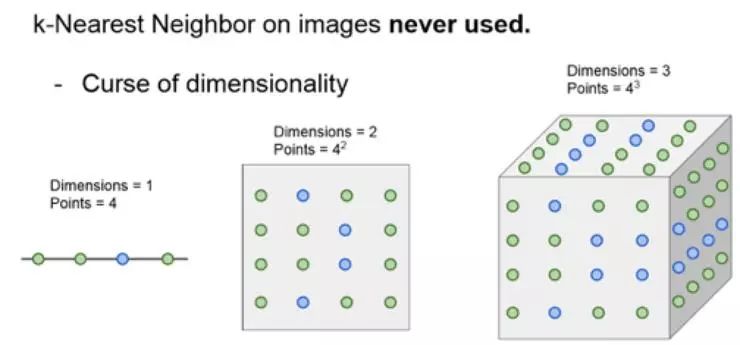
问题在于,要想要密集分布在空间中的数据,意味着需要指数倍地训练数据。
小结:

我们介绍了 KNN 做图像分类的基本思路,借助训练集的图片和相应的标记,我们可以预测测试集中数据的分类。
下面将介绍神经网络,通常会把神经网络比喻为玩乐高。
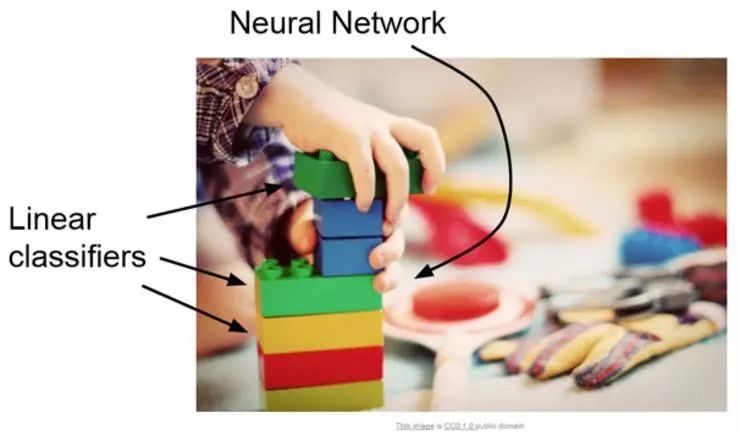
可以将不同种类的神经网络组件组合在一起,来构建不同的大型卷积网络,它是在不同类型的深度学习应用中看到的最基本的构建块之一。这类有关神经网络的模块化性质的例子来自于图像字幕实验室的一些研究。

输入一副图片,然后输出用于描述图像的描述性的句子。这类工作是由一个关注图像的卷积神经网络和一个只关注语言的循环神经网络组成的,把这两个网络放在一起训练最后得到一个超级厉害的系统来做一些伟大的事情。
线性分类器是这种参数模型最简单的例子:
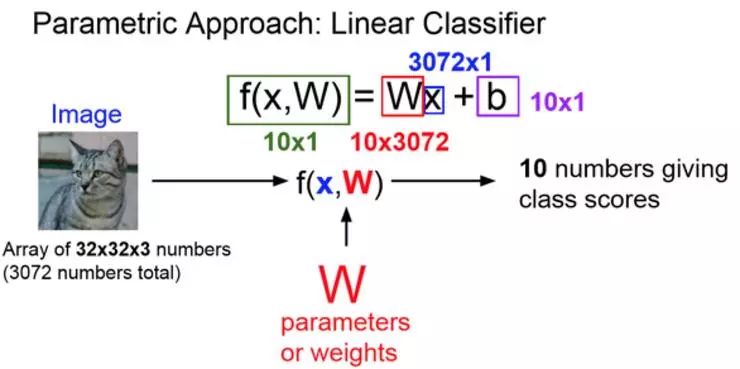
参数模型实际上有两个不同的部分,以这张图片为例子,一组是左边的猫,还有一组是权重参数,通常叫做 W,有时也叫做 θ。现在要写一些包含了输入数据 x 和参数 θ 的函数,就会输出 10 个数字对应 CIFAR-10 中对应的 10 个类别所对应的分数。根据上述描述,比如说猫的分数更大,表面输入 x 是猫的可能性更大。
在最近邻算法的设置中没有参数,取而代之的是通常会保留所有种类的训练集并在测试中使用。但是现在,在一个参数化的方法中,将对训练数据进行总结,并把所有的知识用到这些参数 W 中,在测试的时候,不再需要实际的训练数据,只需要用到参数 W,这使得模型更有效率,甚至可以运行在手机这样的小设备上。
在深度学习中,整个描述都是关于函数 F 的正确结构,可以发挥想象来编写不同的函数形式,用不同的、复杂的方式组合权重和数据,这样可以对应不同的神经网络体系结构。
所以 F(X)=Wx 是一个最简单的线性分类器,如果能把上述方程的维度解出来,前提是图像是 32*32*3 的输入值,要取这些值然后把它们展开成一个 3072 项长列向量,想要得出 10 个类的得分。对于该图像,想要最终得到 10 个数字,从而给出每个类别对应得分情况,也就是说,现在 W 是 10*3072 的矩阵,X 是 3072*10 的矩阵,因此,一旦这两项相乘,就会得到一个列向量,给 10 个类的分数。
通常会添加一个偏置项,它是一个 10 元素的常向量,它不与训练数据交互,而只会给一些数据独立的偏置值。
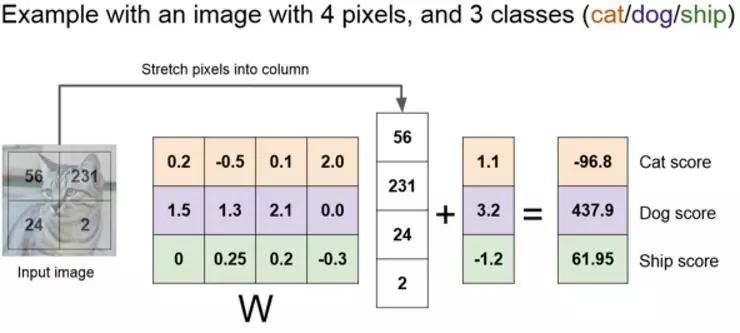
这里有一个简单的例子。左边是一个简单的图像,所以线性分类器的工作是把 2*2 的图像拉伸成一个有四个元素的列向量。
假设这里例子中只有三类,现在权重矩阵是 3*4,可以把线性分类理解为几乎是一种模板匹配的方法,这个矩阵中的每一行对应于图像的某个模板。根据输入矩阵行列之间的乘积或者点积,从而得到图像的像素点。计算这个点积,可以得到在这个类模板和图像的像素之间,有一个相似之处,然后偏置给这个数据对立缩放比例以及每个类的偏置移量。

如果根据这个模板匹配的观点,考虑分类器,实际上,可以取这个权重矩阵的行向量,并且将他们还原为图像。这个例子中,在图像上训练好一个线性分类器,下方是数据集中训练到的权重矩阵中的行向量对应于 10 个类别相关的可视化结果。
举例来说,飞机类别的模板似乎由中间类似蓝色斑点状图形和蓝色背景组成,这就产生一种飞机的线性分类器可能在寻找蓝色图形和斑点状图形的感觉,然后这些行为使得这个分类器更像飞机。车子类别的模板能够看到在中间有一个红色斑点状物体以及在顶部是一个挡风玻璃的蓝色斑点状物体。
但这些看起来很奇怪,它不像一个真正的东西,所以就存在这样一个问题,线性分类器每个类别只能学习一个模板,如果这个类别出现了某种类型的变体,那么它将尝试求取所有那些不同变体的平均值,并且只使用一个单独的模板来识别其中的每一类别。
另一个关于分类器的观点:
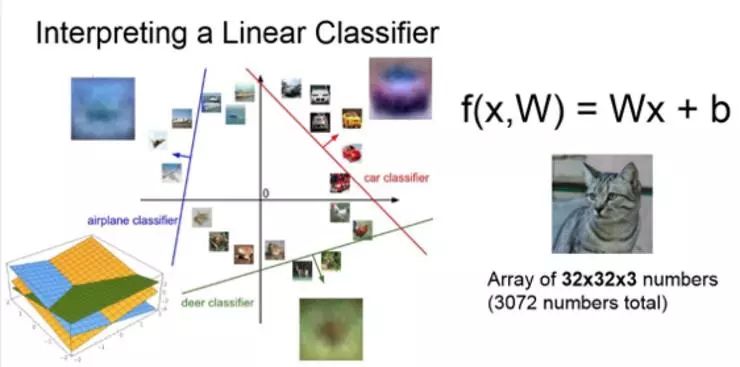
回归到图像,作为点和高纬空间的概念,可以想象成每一张图像都是高维空间中一个点,现在这个分类器在这些线性决策边界上尝试画一个线性分类面来划分一个类别和剩余其他类别。在左上角,看到用来训练的飞机样例,通过训练,这个分类器会尝试绘制这条蓝色直线用以划分飞机与其他类别。
如果观察训练过程,这些线条会随机地开始,然后快速变换,试图将数据正确区分开。
但是当从这个高维空间角度来考虑线性分类器,就能再次看到线性分类器中可能出现的问题:
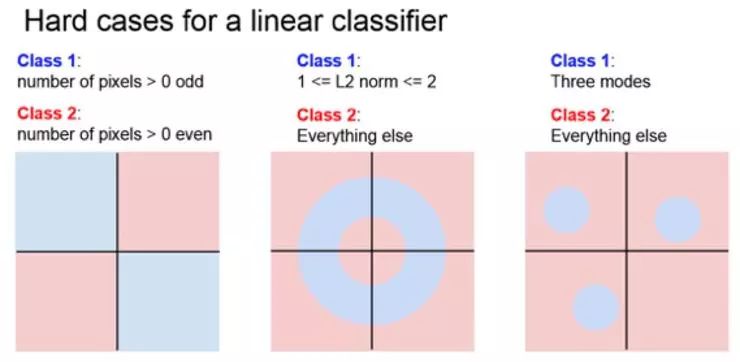
要构造一个线性分类器完全失效数据样例并不难。在左边,假设有一个两类别的数据集,这些数据可能全部,也可能部分是人为的。数据集有红色和蓝色两类,蓝色类是图像中像素的数量,这个数字大于 0 并且是奇数,任何像素个数大于 0 的图像都归为红色类别。
如果真的去画这些不同的决策区域,能看到奇数像素点的蓝色类别在平面上有两个象限,甚至是两个相反的象限。所以,没有办法画出一条独立的直线来划分蓝色和红色,这是线性分类器的困境。
线性分类器难以解决的其他情况是多分类问题。在右侧,可能蓝色类别存在于三个不同的象限,然后其他所有都是另外一个类别。所以对于在之前的例子中看到的像马匹这样的东西,当然在现实中某种情况下也会出现,在马匹的像素空间中,可能一个头向左看,另一个头向右看。目前还没有较好的方法可以在这两个类别之间绘制一条单独的线性边界。
当有多模态数据时,这也是线性分类器可能有困境的地方。
线性分类器存在很多问题,但它是一个超级简单的算法,易于使用和理解。






