无问西东,只问哈希
“假设我是一串高维数据,这串数据将被加密,当数据的加密完成,它会生成一段二值码,当这段码字代替原始数据被用于检索任务时,就会加速检索的过程,这个加密过程,就是哈希。”
哈希,是化繁为简、以简驭繁;是在纷繁的数据世界中,通过学习千千万万个它,来寻找那个独一无二的你。今天,来自电子科技大学的沈复民教授,将带领大家一起,在纷繁的数据世界中,无问西东,只问哈希
文末,大讲堂特别提供文中提到所有文章的下载链接。


我的报告将分为四部分,首先介绍什么是哈希,接下来介绍哈希中的一个独特方法——离散优化,然后是离散哈希的应用,最后介绍我们在SIGIR 2017上一个利用哈希汉明检索的分类工作。
什么是哈希(Hashing)
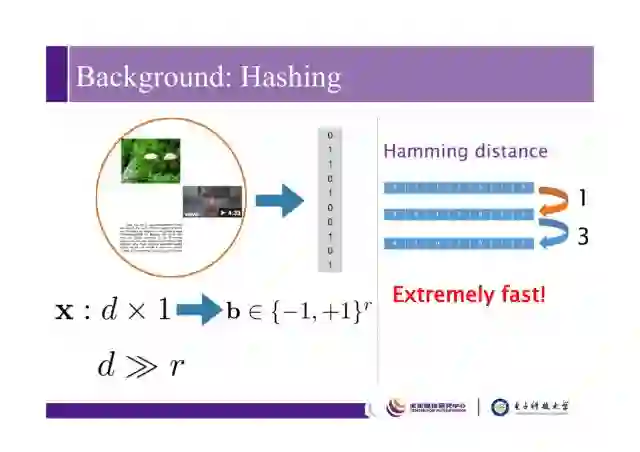
针对图像、视频或者文本数据库,哈希的主要工作是将高维数据变成低维紧凑的二值码,比如将d维数据变成r维,d远远大于r,一般r维数据在几十比特到几百比特之间。将数据变成哈希码后计算数据之间的距离或相似性会非常快,常用汉明距离来衡量,汉明距离的计算可以用CPU的一些快速指令,比如XNOR(异或非)或POPCOUNT。
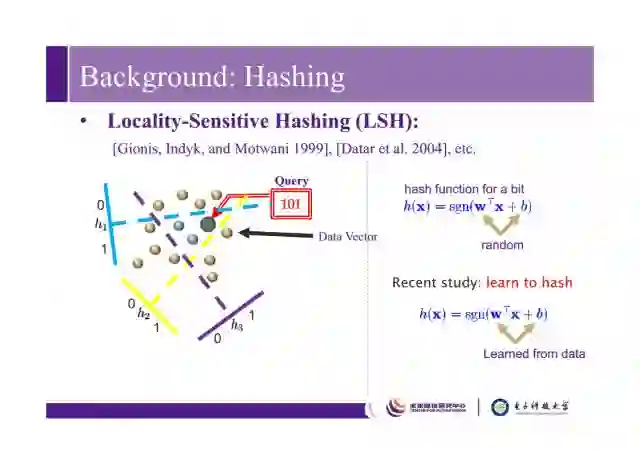
哈希里面最著名的一个工作,也是工业界应用最多的一个工作是Locality-sensitive hashing(LSH),它在1999年被提出来。假设有一堆数据x,我们将这堆数据投影到空间里,通过如下操作将它变为0或者1。
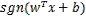
如上图左边所示,随机在空间里划几个超平面,就可以把数据分到不同空间里,比如中间这个小三角的区域就可以赋值为101,之前w,b是随机生成得到的,而现在更多是基于机器学习或者依赖于数据而得到的。

哈希的一个主要应用是最近邻搜索,比如对于一个蝴蝶图片,我们希望在数据库中搜索到和它在视觉上最近似的图片。

LSH有很多不同的变种,它不仅支持欧几里得空间,还可以支持更多的维度,比如 lp 范数、余弦相似度、高斯、卡方核等。它的优点是简单易用,有次线性的搜索时间,缺点是需要很长比特的哈希码或者非常多的哈希表才能达到预期的性能。

因此,最近的学术界更多的研究集中于基于学习的哈希,期望通过此方法学习到更有效紧致的哈希码。


有监督的哈希方法也非常多,比如SSH同时利用有标签和无标签的数据进行哈希,MLH基于结构化的支持向量机,KSH是基于核的有监督哈希,FastH通过经典算法Graph Cuts解决哈希问题,SDH通过离散优化生成二进制码,COSDISH是基于列抽样的离散监督哈希,以及近来基于深度学习方法的哈希DSeRH等等。

深度学习目前在计算机视觉和多媒体领域已经取得了显著的成绩,哈希领域也涌现了非常多的深度学习方法,效果都很不错。但是,目前大多数基于深度学习的哈希都是有监督的,而无监督方法却寥寥无几。

如上图是有监督的基于深度哈希方法和基于浅层模型方法的比较,可以看出深度方法比传统方法效果好很多。但是如下面表格所示,左边ITQ和IMH是基于浅层模型的无监督方法,右边的DH和UH是典型的基于深度学习的无监督方法,中间是结合卷积神经网络的特征和浅层ITQ模型的方法,可以看出目前的无监督深度哈希方法很大程度依赖于深度学习提取的特征,因此目前无监督的深度哈希还有很大的提升空间。

哈希和流形学习方法有什么区别呢?如图左边是著名的Laplacian Eigenmaps(拉普拉斯特征映射)公式,加上如下三个条件后,就是我们所谓的spectral hashing(谱哈希)
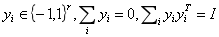
第一个条件保证所学哈希码的离散性,第二个条件保证学习出来的哈希码是平衡的,第三个条件保证学习到的哈希码是不相关的,以此可以学到更有效的紧凑的哈希码。从形式上看,哈希和流形学习之间的区别很小,主要在如上三个限制条件上。但其中最主要的,离散条件(二值化)的限制使得哈希学习的研究和传统的流形学习方法或其他降维方法产生很大区别,主要体现在优化上面。

所谓哈希学习问题只指,对于数据X,我们期望学到它的紧致表达哈希码B(r比特),B是r×n的,同时期望学习到一个预测函数(哈希函数)。因为变量B是离散的,所以不能用传统的梯度下降方法去解,这一问题是典型的混合整数问题,通常为NP hard(non-deterministic polynomial,缩写NP,非确定性多项式)问题。

在2015年之前,求解该问题基本分两步。第一步是将离散限制去掉,这就变成了连续优化的问题,可以用传统的梯度下降方法去求解,它的缺点是很难得到比较好的局部最优解;第一步去掉离散限制之后得到了连续的结果,第二步通过设定阈值进行二值化操作,比如将大于阈值的转为1,小于阈值的转为0,由此就得到了哈希码。当然,也可以利用类似2011年ITQ这篇工作去减少量化损失。这种方法的缺点是对于长哈希码(比如超过100比特),量化偏差会很大,使得学出来的哈希码不是很有效。
离散优化

我们从2015年开始研究离散优化问题,试图在不去掉binary constraint的条件下去解哈希问题,这是哈希和传统流形学习方法的区别,我们希望能够求解哈希的原本问题。

这是我们在CVPR2015的一个有监督的离散哈希工作。假设有一个数据X,我们希望学习到它的二进制代码B,同时使其很容易被分类到Y(groundtruth)这个标签矩阵上,希望通过W这个矩阵将B很容易分到正确的类别上。这里面有三个变量B,W,F
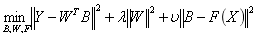

可以用迭代优化来求解该问题,依次求解W,F,B。其中最主要的就是求解B,它其实是一个二进制值优化问题。

B是离散的,因此我们提出了Discrete Cyclic Coordinate descent(DCC,离散循环坐标下降)方法,保留了binary constraint,直接求解矩阵B难度是很大的,因此我们通过逐比特地学习来解决这个问题。

在每一次迭代的时候都可以得到optimal,close-form solution,所以整个优化过程非常快。

如左图是对离散方法和常用two-step方法的对比,可以看出,随着比特数的升高,差距越来越大,离散方法比relaxed方法好很多。右图是和主流的有监督方法的比较。结论:离散优化对哈希问题本身是比较重要的。

我们沿着这个方向做了很多工作,总结起来,离散优化对于哈希问题本身来说是非常重要的。简单统计了一下,有监督的离散哈希方法(SDH)不仅支持linear cascaded loss,还支持hinge loss;更重要的,它训练的复杂度是O(n)的,因此可以快速学习整个数据库的二进制值,可以把整个数据库放入训练过程中,而不需要抽取一部分训练数据学出哈希函数之后再做inference。

刚才说的SDH方法可以支持几种损失函数,但它毕竟不是通用的,对于非常复杂的loss error,SDH方法就不能胜任了,因此我们能不能找到一种方法满足loss是任意的,只要是平滑的就可以求解。

这是我们在TIP2016做的一个工作,我们的方法被证明一定是能够收敛的,也通过实验证明了这个方法比relaxed方法好很多。如果B属于C,则损失是0,否则损失为正无穷,也就是将原本问题转化为该问题,就是smooth+non-smooth loss 问题,通过这个方法可以快速得到。该方法和SD方法区别在于,SDH需要逐比特地学,而这个方法可以学整个B。

该方法被证明一定是可以收敛的,并且比SDH更快,可以把该方法应用到有监督和无监督哈希中。
离散哈希的应用

这部分主要介绍离散哈希的应用。

这里其中一个应用是做了MIPS(Maximum Inner Product Search,内积最大值搜索),和approximate nearly search还是有很大区别的,
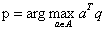
这个问题是指,假设数据库A中存储了很多样本a,我们希望依据query q从数据库中搜索到与query q有最大内积的样本a。这是一个无监督学习的工作,假设S是groundtruth,这里用A和X做一个内积,希望对数据库的A学一个哈希函数,对X学另一个哈希函数,通过同时学习这两个哈希函数去拟合groundtruth,这其实是一个inner product fitting的问题,通过学一个非对称的哈希函数来实现。
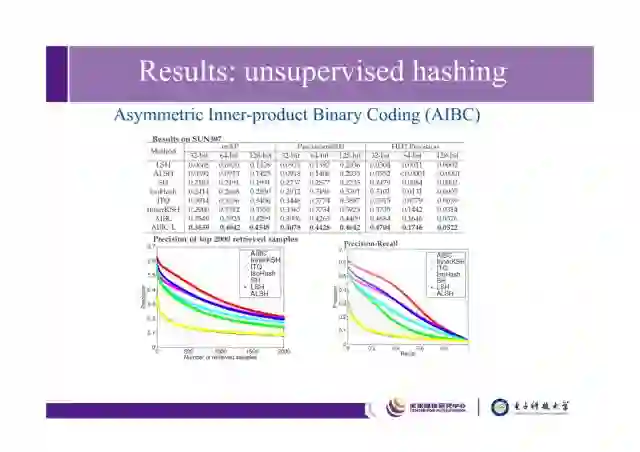
这个工作发表在ICCV2015上,这是和当时无监督哈希方法的比较结果。

这是我们2016SIGIR上和新加坡国立大学张含望老师合作的一个工作。Collaborative filtering,大家知道协同滤波一般用在推荐系统里,它实际是一个矩阵分解问题。一般推荐系统中用户量和数据量是非常大的,当时我们希望通过二值哈希技术来将它加速。

这是一些结果,可以看出DCF方法较其他方法有明显的提升。
利用哈希汉明检索分类

下面介绍SIGIR2017上的一个工作,初衷是,现在有非常多的哈希工作,基本都是针对检索问题,很少有针对分类问题的算法。能不能把哈希用在分类问题上呢?另外,把图像变成哈希码后,对图像分类是用传统的分类方法,还是把哈希码当作real-valued features呢,能不能利用二进制码本身的特质,来加速分类的过程呢?

这里的思想非常简单,一句话称之为“classify binary data with binary weights”,之后用二进制码进行分类,比如从d维变成r维,分类器W是d×C维的,把他变成r×C维的二进制,将得分y也变成二值的。很显然的好处是,左边需要dC次浮点数乘积操作,右边需要rC次XNOR操作,速度比左边快很多。这个工作是我们组和北大、腾讯AI Lab以及英国的东英吉利亚大学合作的。

简单介绍一下它的框架,通过对训练图片提取特征,得到HD real-valued features,通过joint learning方式同时学习图像和标签的binary code,利用binary code把分类问题变成利用哈希码做汉明检索的问题。

这是它的formulation,其中主要部分如上图红框所示,bi是imagei的二进制码,wci是指第i张图片groundtruth的类别,希望wci和bi的内积大于wc和bi的内积,我们定义这个部分叫inter-class margin,这里的损失函数可以是任意的,这里采用了两个算法,一个是exponential loss,一个是linear loss。

W和B都是binary metrics,因此求解是非常相似的,我们通过逐比特的方式去解。
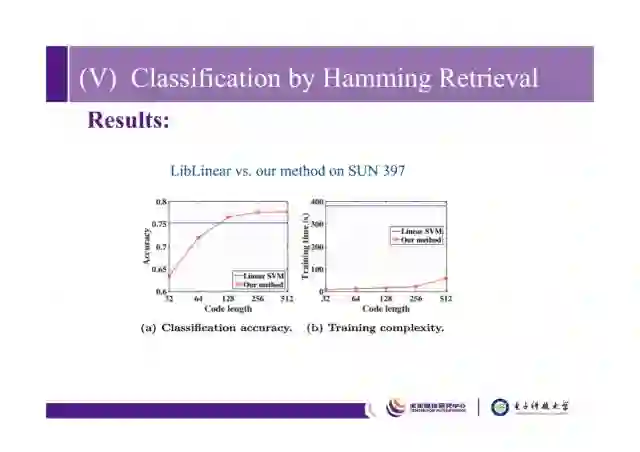
这是在SUN397数据集上的结果,可以看出当哈希码的长度超过128比特时,我们的算法准确率超过linear SVM,训练时间比linear SVM少很多。

我们在SUN397,ImageNet,Caltech-256三个数据集上做了比较,准确率和SVM基本持平,在训练时间和测试时间上明显优于SVM,也比传统哈希方法好。

这是和其他哈希方法的比较结果。

总结起来,我们将线性分类问题转化成了汉明检索问题,把数据和分类器同时进行二值化处理,它也支持很多empirical loss函数,并且有效减小存储和训练测试消耗资源。

接下来简要介绍我们在CVPR2017上一个sketch retrieval问题,可以搜索和sketch query语义相关的图片,传统上有很多基于手工特征和深度特征的方法,这里我们采用哈希方法来做。

如图是DSH(deep sketch hashing)方法的框架,natural image 和 sketch image在图像结构上的差异是非常大的,如果直接用cross model retrieval的跨模态检索方法去做,效果不佳, 所以提出了自动提取sketch token的方法,希望Bs和BI内积能够和groundtruth吻合,同时我们还利用了word embedding把类别映射到一个word vector上,希望能够更多地获取语义类别之间的相关性。整体上这个工作把CNN和discrete binary code learning结合起来放到一个统一的框架下。

这是我们整个的formulation,W是groundtruth label metrix,BI是natural image的binary code,Bs是sketch图像的binary code。

这是一个优化的过程,通过迭代优化的方式逐步求解。
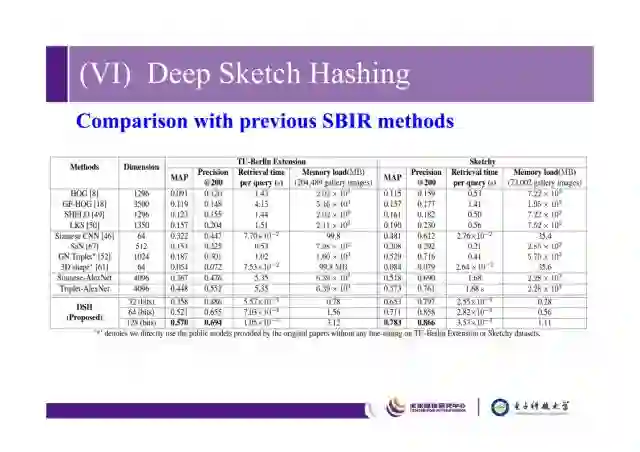
这是我们的DSH方法和以前SBIR(Sketch based image retrieval)方法的比较。
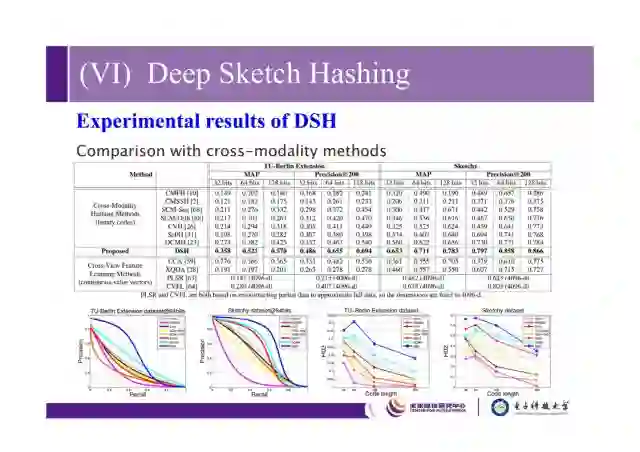
这是我们和之前的cross-modality方法的比较,因为cross-modality不是针对sketch retrieval的方法去设计的,所以它的效果不是特别理想,和real-valued方法比较,我们的方法还具有一定的优势。

这是一些通过deep sketch hashing做的成功案例,这是我们和英国的东英吉利亚大学一起做的工作。

最后讲一下我们在CVPR2017上用哈希去做partial action recognition的工作,传统方法是通过视频序列判断动作,action prediction是通过前序帧来预测后序帧。我们partial action recogtion在丢帧、遮挡的情况下依旧能够预测动作。
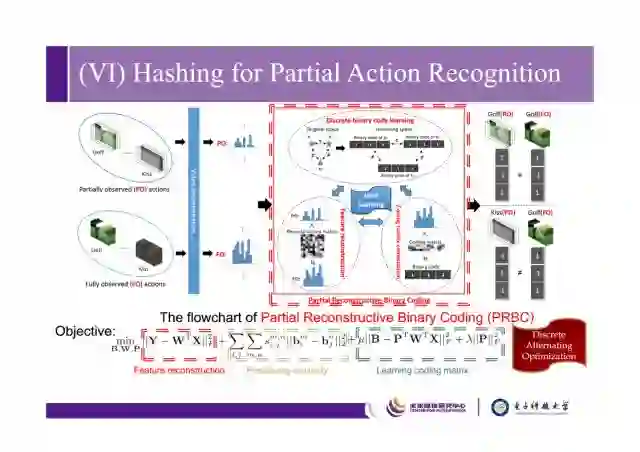
这是整个工作的框架,在公式中,X是partially observed actions,Y是fully-observed actions,希望通过W矩阵对它做一个还原,希望学fully observed action的二进制码,希望二进制码能够还原原先的similarity,这是比较常用的学习哈希码的损失函数,整个学习过程我们通过discrete alternating optimization方法求解。

这是一些结果,虽然学习到的特征是二进制的,但是整个效果可以看出还是不错的。这个工作是我们和北航、东英吉利亚大学以及上交大一起合作的。

除了这个工作,我们在离散哈希中还做了很多工作,如上图所示。

谢谢大家!
文中沈老师提到的文章下载链接为: https://pan.baidu.com/s/1qZZUEJi
本文主编袁基睿,编辑杨茹茵。转载自公众号“深度学习大讲堂”,详情请点击文末“阅读原文”
作者简介:

沈复民,本科毕业于山东大学数学与应用数学专业,南京理工大学与澳大利亚阿德莱德大学联合培养博士,目前任职电子科技大学“百人”教授。他的主要研究领域为大规模图像检索及分类等计算机视觉课题。近三年在相关领域共发表包括顶级会议及期刊CVPR、ICCV、TPAMI、TIP在内的论文九十余篇。他任职SCI期刊Elsevier Neurocomputing、Pattern Recognition Letters等期刊的客座编委,国际会议ACPR的专刊主席,MMM 2016、ICIMCS 2016的special session chair,ICCV、ACM Multimedia,ICMR, ICPR, CCBR等国际会议的PC member,并为多个国际一流期刊包括IEEE TPAMI, IEEE TIP, TKDE, TMM, TNNLS, TCSVT的审稿人。他连续获得ACM SIGIR 2016及ACM SIGIR 2017 Best Paper Award Honorable Mention, IEEE ICME'17最佳论文奖-铂金奖。
个人主页: http://bmc.uestc.edu.cn/~fshen/

五分钟,你可以掌握一个科学知识。
五分钟,你可以了解一个科技热点。
五分钟,你可以近观一个极客故事。
精确解构科技知识,个性表达投融观点。
欢迎关注线性资本。
Linear Path, Nonlinear Growth。




