博客 | 斯坦福大学—自然语言处理中的深度学习(CS 224D notes-2)

本文原载于知乎专栏“AI的怎怎,歪歪不喜欢”,AI研习社经授权转载发布。欢迎关注 邹佳敏 的知乎专栏及 AI研习社博客专栏(文末可识别社区名片直达)。
社长提醒:本文的相关链接请点击文末【阅读原文】进行查看
关键词:内在/外在评价,超参数在类推(analogy)评估中的作用,人类判别和词向量距离间的相关性,根据上下文消歧,窗口(Window)分类。
本文从内在和外在评价开始,展开对词向量的讨论;然后,将词类推(word analogies)作为内在评价的一个样例,同时讨论如何根据它来微调词向量本身。接着,在外在评价领域,我们讨论训练模型的权重/参数和词向量;最后,我们将介绍激动人心的人工神经网络在自然语言处理任务中的重大作用。
一, 如何评价词向量
到目前未知,我们已经介绍了Word2Vec和GloVe如何在语义空间训练和发现潜在的词向量表示。本节中,我们将讨论如何定量的评估不同模型所产出词向量的质量效果。
1, 内部评价:(对特定中间任务的评价;快速计算;帮助理解子系统;与直接任务正相关)
内部评价是对一组词向量集合的评价,这组词向量是使用词嵌入模型(Word2Vec或GloVe)在处理特定的中间子任务(specific intermediate
subtasks)(比如,类推补全)时生成的。这些子任务通常计算简单快速,并且也能帮助理解词向量模型系统。有效的内部评价应当寻找并计算一个合适的指标,它能够评价词向量在子任务评价中的效果。
动机:假设我们要使用词向量作为输入,创造一个问答系统,我们需要:询问问题并计算分词词向量,输入问答系统,再将输出映射至人类可理解的自然语言。
构建该问答系统,核心要点就是如何获得,需要在下游子系统(深度神经网络)中使用的——“词向量表示”。在实际应用中,词向量本身也经常需要调整参数(Word2Vec的向量维数)。受限于深度神经网络中数以百万计的参数规模,耗时巨大,仅靠参数的调整在工业界完全不能承受。因此,一种有能力评价词向量优劣的内部评价技术,就必须要求与最终的学习任务性能或效果正相关。

左边的问答系统评估和优化极其困难,而优化右边的词类推则非常简单,两者目标一致
2, 外部评价:(对直接任务的评价;计算缓慢;难以排查子系统问题;只能通过替换子系统以提高性能)
外部评价是对一组词向量集合的评价,这组词向量是在处理真实任务中产生的。这些任务通常精密复杂,难以计算。比如,一个可以对问答系统的回答质量做出评价的系统,本质上就是一个外部评价。通常,因过度优化而达不到预期的外部评价并不能为我们指明,到底是哪一个特定的子系统出错。每当这时,内部评价才是解决问题的钥匙。
3, 内部评价举例:词向量类推(Word Vector Analogies)
内部评价的流行方案就是,评价词向量在完成类推任务中的表现。类推任务,通常想要解决a:b=c:?的问题。此时,内部评价会去计算,能最大化余弦距离的那个词向量:

对上述公式的直观理解是:为了寻找 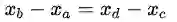
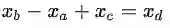
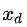
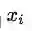
考虑到语料本身的多样性,使用词向量类推等内部评价技术时需要多加小心。比如,①,对City n:State containing City n的语义任务中,仅仅类推出Phoenix:Arizona是不够的,因为全美至少有10个城市叫Phoenix,所以,语料中包含的那个Phoenix,会直接影响结果。②,对Capital City n:Country n的语义任务中,类推出Astana:Kazakhstan也仅表达出最近的含义,毕竟在1997年以前,Kazakhstan的首都还是Almaty,所以,可以预料的是,语料的时态也很重要;③,对普通形容词:最高级形容词和进行时态动词:过去时态动词的2个语法任务中,也存在类似的问题。
4, 内部评价举例:微调参数——类推评估(Analogy Evaluations)
接下来,我们开始讨论,如何使用内在评价系统(词类推补全)来调整词嵌入(Word2Vec和GloVe)模型参数的问题(比如,词向量维度,语料规模,语料来源/类型,上下文窗口大小,上下文对称性)。
首先,我们观察在相同参数下,不同的词嵌入方法,在同一个类推评估任务中的精度表现:

从上表中,我们得到3个结论:
4.1,精度表现显著依赖于词向量模型:在语料训练中,不同的模型使用不同的基本性质,比如,词共现计数或奇异值矩阵;
4.2,精度表现随语料规模的增加而提高:在语料训练中,如果模型没有遇到某一特定情况,自然它也无法准确得到类推结论;
4.3,精度表现在词向量维度过高或过低时都会下降:在语料训练中,词向量维度过低不能俘获必要的性质,表达能力不足;而过高会引入不必要的噪声,泛化能力降低,这也被称为高方差问题(high variance problem)。
下面用3张图片可视化的表现不同参数对模型性能的影响:

训练时间对模型精度的提高和“压榨”

语料规模对模型精度的影响

其他参数对GloVe精度的影响
5, 内部评价举例:相关性评估(Correlation Evaluations)
另一个简单的词向量评估就是,将人类对单词相似度的评估与词嵌入模型计算出的余弦相似度进行比较。在人类已标注过的相似度语料中,不同模型的表现如下表所示:

6, 扩展阅读:词性消歧
Huang ET AL在2012年发表的论文《Improving Word Representations Via Global Context And Multiple Word Prototypes》中提出,可以用以下4步解决NLP中的词性消歧问题(比如,Run在不同的上下文中会有名词和动词两个含义):
6.1,汇总歧义单词的全部共现窗口的上下文,共现窗口固定大小(比如,5);
6.2,使用加权平均的方法将每一个收集的上下文表示为单一词向量(比如,idf权重);
6.3,使用球面k均值聚类歧义词的上下文词向量表示;
6.4,最后,每一个歧义词向量都会被重新标注到它的关联类别上,同时也能被用来训练该类别的其他词向量。
二, 外在任务(Extrinsic Tasks)的训练
虽然内在任务(Intrinsic Task)在开发词嵌入模型中影响巨大,但现实问题的最终目标,通常是,如何使用词向量作为输入,解决外在任务(Extrinsic Task)。现在我们开始讨论,处理外在任务的通用方法:
1, 问题的定义:
大多数NLP的外在任务都被认为是分类任务。比如,给定一个句子,判断它的积极,消极和中性的情绪;同时,在命名实体识别(NER)任务中,给定上下文和中心词,我们想知道该中性词是人名,组织机构名还是时间。
这类问题通常从训练数据集{xi,yi}1-N开始,xi是使用词嵌入模型训练出的d维词向量,yi是C维的one-hot向量,用来表示最终的预测目标(情绪,中心词,命名实体或买卖决策),选择一种机器学习模型,使用最优化方法(梯度下降,L-BFGS,牛顿法)训练模型参数(比如,以二维词向量作为输入,使用逻辑回归或SVM等简单的决策边界模型,解决分类问题)。但在NLP应用中,我们引入“再训练输入词向量”(retraining the input word vectors)的概念来训练外在任务。
2, 再训练词向量(Retraining Word Vectors)
将内在任务优化后的词向量作为输入,通常能解决大多数外在任务的问题。但这些预训练好的(pretrained)词向量仍可以使用外在任务进一步训练(retrained),进一步提高分类性能。需要注意的是,再训练词向量充满风险。
再训练词向量前,我们需要确保语料集足够大,以至于能覆盖已知词典的绝大多数单词。因为Word2Vec和GloVe会将语义相近的单词在词空间中汇聚到一起,在一个较小的词库集内,对词向量再训练,会使得单词在词空间内移动,以至于在最终的分类任务上表现变差。因此,如果语料不是足够大,请不要再训练词向量。
1, Softmax分类和正则化
3.1,Softmax分类函数的形式如下: 词向量x属于j类别的概率:

3.2,使用交叉熵损失函数,计算j类别在训练集上的损失:

3.3,因为one-hot向量的原因,交叉熵有C-1个0值,只有当x属于第j类的位置下标才等于1。因此,假设k是j类的下标,简化后的损失函数:

3.4,扩展简化后的损失函数至N个点的数据集上:k(i)函数,表示可以返回样本xi所属正确类别的下标:

让我们接着看,训练该模型需要迭代和更新的参数个数(模型权重W和词向量x),对线性决策边界模型来说,至少需要1个d维的输入词向量,并将它分类至C个类别中。因此,模型至少需要更新C·d个参数。进一步的,如果我们要训练词典V中的所有的d维词向量,则整个简单线性决策边界模型而言,将至少需要更新C·d+|V|·d个模型参数!
如此一个简单的线性分类器竟然也需要这么多参数,模型的过拟合自然也接踵而至。因此,为了降低过拟合的风险,我们引入一个正则化项,它建立在贝叶斯定理(Bayesian belief)的基础上,同时,参数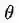
3.5,于是,最小化带正则项的损失函数:

如果相对客观的参数 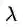
4, 窗口分类:(Window Classification)
到目前为止,我们已经讨论了,外在任务中,如何使用单个词向量的预测问题。但在自然语言天然的歧义性,将使问题变得复杂。比如,“to sanction”在不同的语境下,将表达“to permit”或“to punish”的双重含义。于是,训练模型的输入是一个包含中心词和上下文的词向量序列,上下文词的数量,即上下文窗口大小,也依赖于需要解决的问题。通常,较小的窗口在语法测试上表现较优,而较大的窗口更能理解语义。

拥有对称上下文窗口大小的中心词,Paris,能消歧地名或人名
因此,我们将带正则项损失函数的 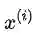
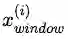

在计算词向量梯度时,我们也从单个词向量的梯度计算,变成上下文词向量的梯度,用以在实现中迭代更新其各自对应的词向量:

5, 非线性分类器:神经网络的必要性

线性模型有限的分类能力导致较多被错误分类的样本,相反,非线性模型表现更精准可靠
推荐阅读

【AI求职百题斩】已经悄咪咪上线啦,还不赶紧来答题?!

想知道正确答案?
回公众号聊天界面并发送“1225挑战”即可获取!
点击 阅读原文 查看本文更多内容↙



