二值分类熵界分析—国科大UCAS胡包钢教授《信息论与机器学习》课程第五讲
【导读】熵界分析是建立信息类学习目标与传统经验类学习目标(如误差)之间关系的基础理论内容。熵界分析对于理解两种学习目标十分重要。二值分类(如支持向量机)是机器分类学习中最为基本的单元。在第三章中我们图示了二值分类的熵界。这只是对熵界从机器学习角度的初始理解。本章给出了在机器学习背景下推导熵界的全新理论知识,说明信息论与机器学习综合后可以获得共同进展。

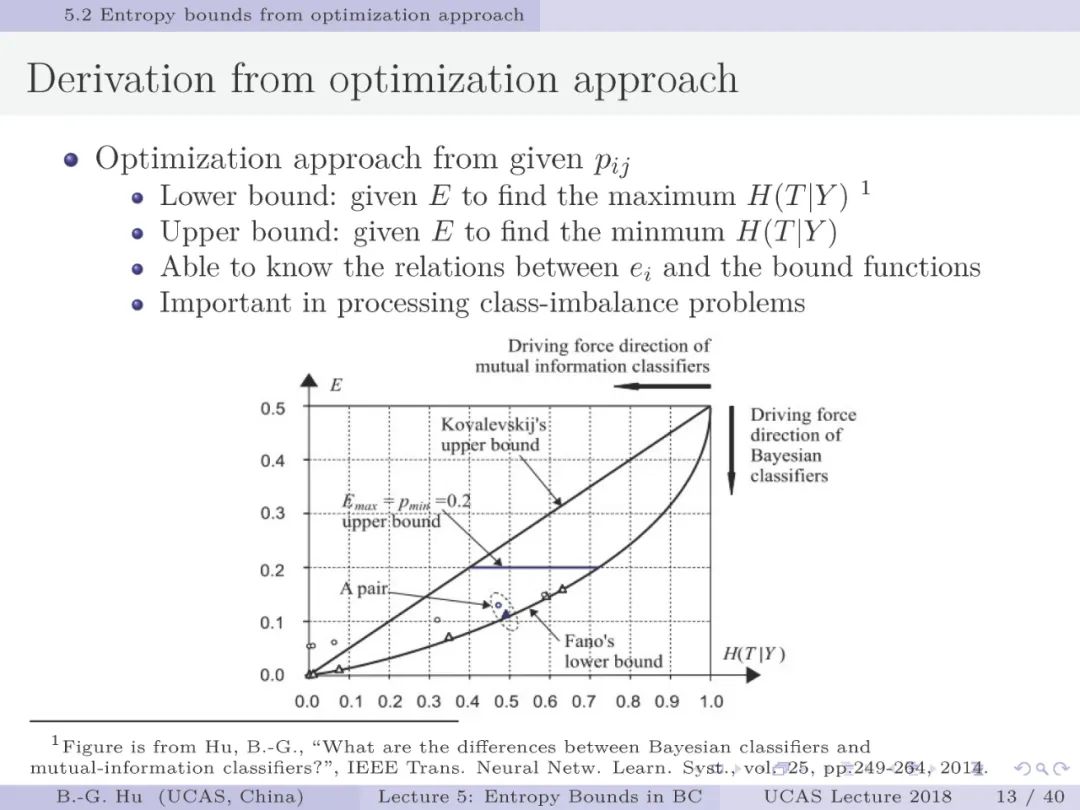
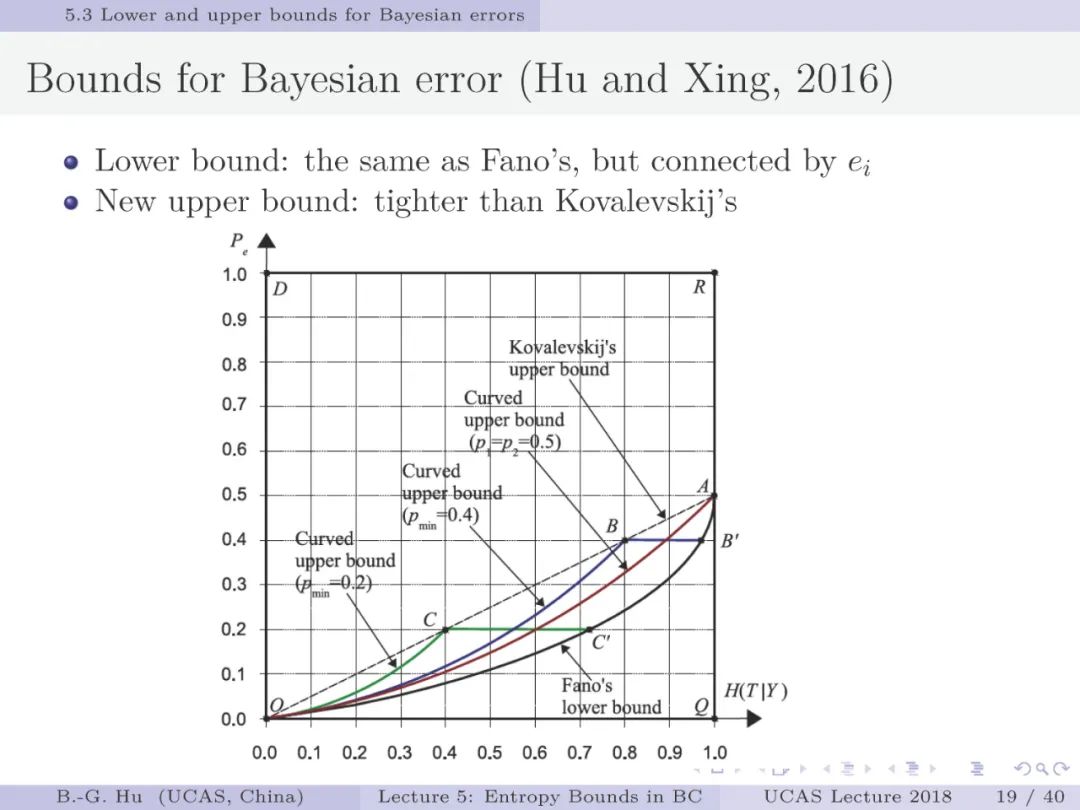
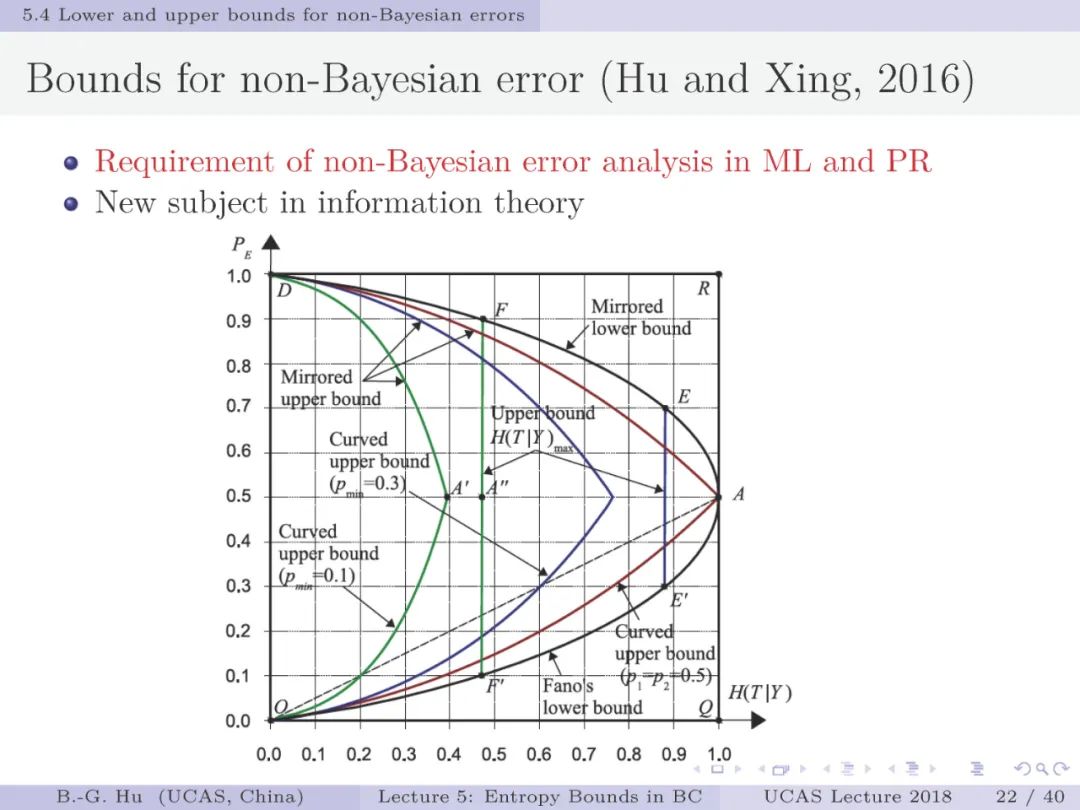
首先,我们区别考虑贝叶斯误差与非贝叶斯误差两种情况的熵界分析。由于多数分类器是以非贝叶斯方法出现,如深度学习,支持向量机,决策树等。因此非贝叶斯误差熵界分析更为重要。而传统信息论研究中仅考虑贝叶斯误差。其次,新的熵界分析是从联合概率分布为初始条件,应用优化方式导出上下界。而传统方法是从条件概率分布为初始条件,应用不等式方法推导熵界(如第三章中的Fano下界)。再有,新方法能够建立条件熵与误差类别(e_1与e_2)之间关联,增加了对误差方面更全面的解释性。而传统分析中只能有总误差(e=e_1+e_2)方面信息理解。最后,对于原有Fano下界发现的新知识(或解释)有:该界不仅对应两个随机变量是独立情况(互信息等于零,或条件熵为最大),也可以对应非独立情况(互信息不等于零)。对于原有Kovalevskij上界发现的新知识有:对于贝叶斯误差情况,新推导的上界为严格解、比Kovalevskij上界更紧且只有两点经过Kovalevskij上界(第19页)。
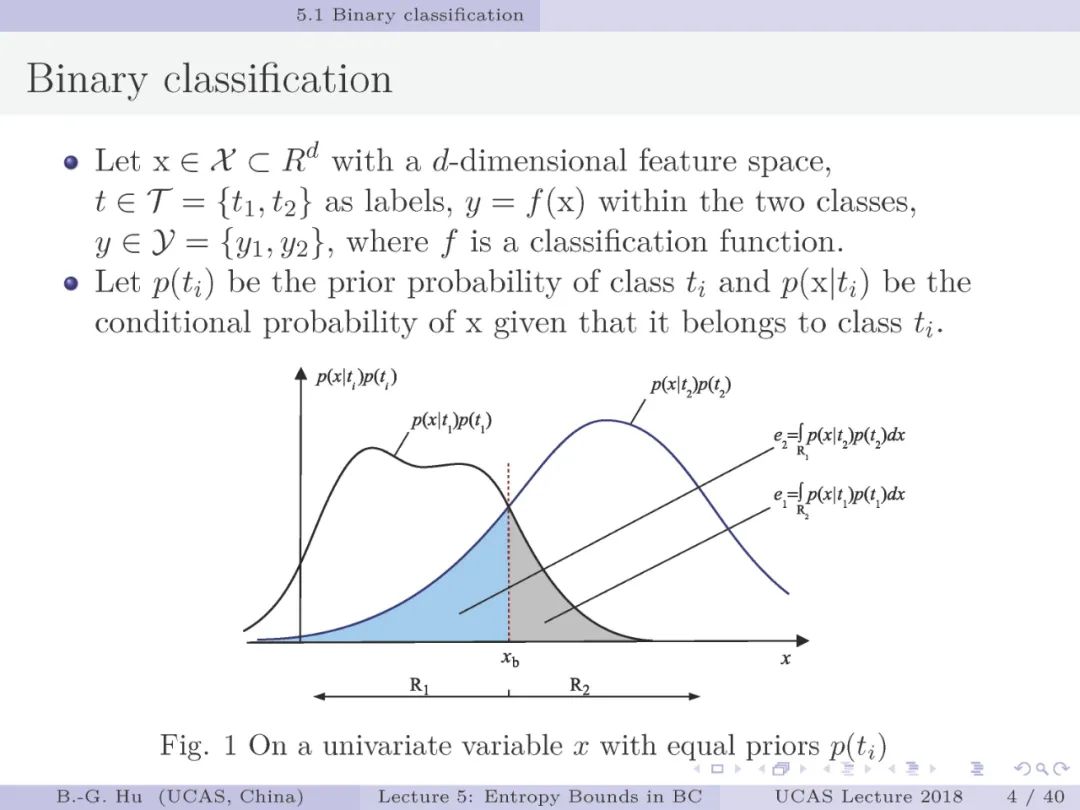
第4-10页:要理解贝叶斯误差在机器学习情况下只是理论上存在,因为我们无法获得数据中实际概率分布信息。在此我们是通过分类问题中给定的混淆矩阵推出联合概率分布的估计(第10页)。只有当总误差e大于最小类别比率p_min时,我们才能判定这是非贝叶斯误差(想想为什么)。否则是无法判定,因此通常该e可以对应贝叶斯误差或非贝叶斯误差情况(第8页)。
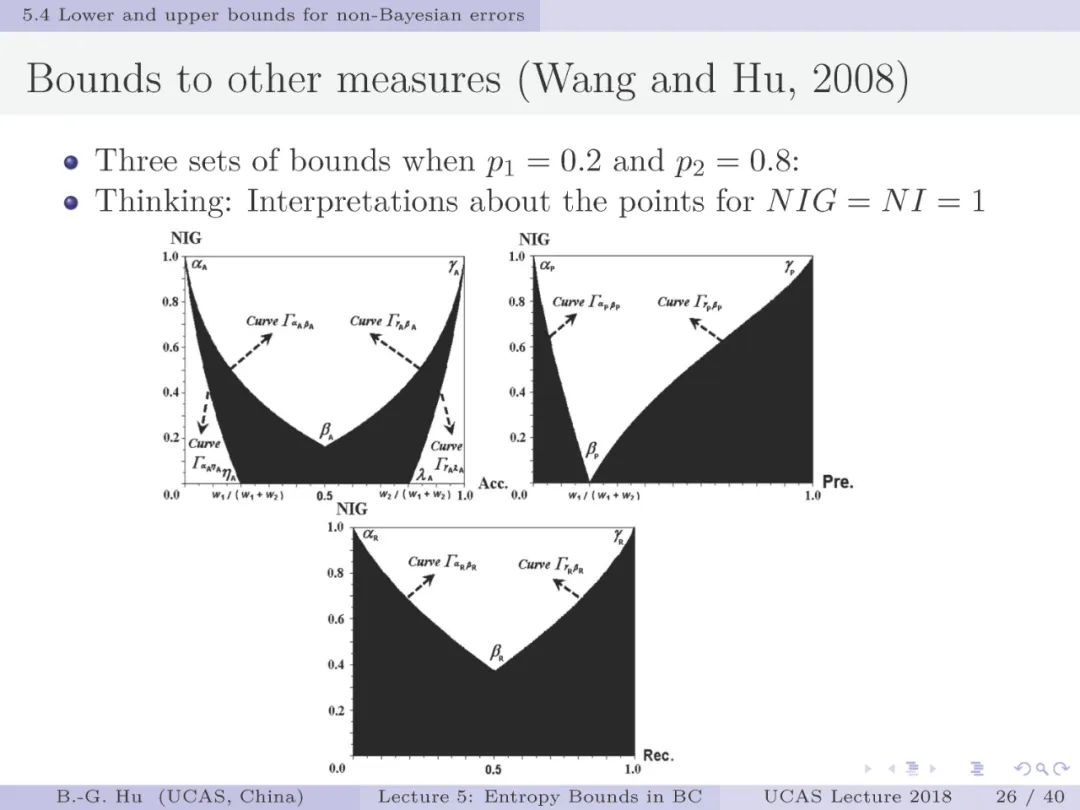
第25-26页: 这是王泳博士首次推导了互信息与分类准确率A、召回率R、精确率P之间的熵界分析。从数学关系表达上讲,应该用两个独立变量更为正确。而实际推导结果显示,应用这三个变量A、R、P表达,方可获得这样更为简洁的数学表达式。这三个变量构成冗余关系,即任一个变量可以由其它两个变量导出。第26页图首次给出了熵界分析的另一种表达方式。其中熵界形状是与类别比例相关,并能够变化。这个熵界分析隐含为非贝叶斯误差情况。
第40页: 这页包扩了本人的三个作品。一个工具箱,两个图标设计。工具箱适用于多分类问题中24个信息指标计算,因此读者可以验证课件中的全部例题。并可以输入你个人的任意混淆矩阵进行计算。工具箱需求在Scilab开源平台上运行,这是与Matlab十分相似的软件。读者可以自行下载有关软件。如果应用其它类平台,可以参照工具箱中代码自行编写。这些作品除了源自个人喜欢之外,还有一种“不甘”心态:中国人不是天生的盗版者或搭车人,我们会成为被世人尊重的创造者。只是要早明白这个道理并实践。其中图标OpenPR对应我们模式识别国家重点实验室于2011年开展的“开放模式识别项目”。希望研究者能够提供相关的软件与工具箱或数据等,以促进相关领域学术交流与积累。
作业:
1. 对第26页图示中NI=1时的情况给出有关分类结果的解释。
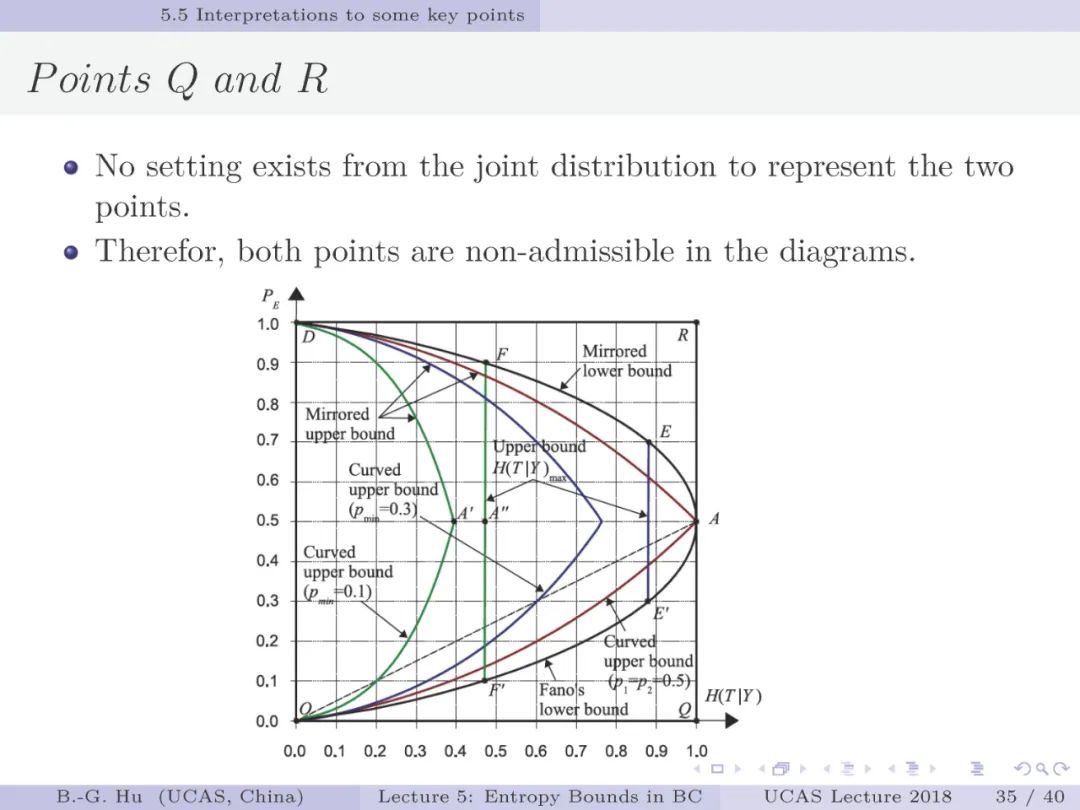
2. 对第5.5中全部实例应用个人实际数值计算来考察正确否?给出个人对实例中熵界的内涵及其分类方面的解释。
3. 思考你能否推出三类别分类的熵界分析公式吗?
附录(用于课间交流话题):
这里分享我个人与开源软件相遇后的经历说明人生当要:向大师学习,走创新之路。2001年由于工作原因我了解到法国科学家发展的开源软件Scilab。兴奋之后是一种共鸣:开源世界,精彩缤纷,大可作为。事实上,我在1980-1983年期间硕士研究生工作就极大地受益于美国加州大学伯克利分校两位学者Wilson与Bathe(师生关系)1974年发布的开放源码有限元程序SAP-4软件(向他们致敬并特别致谢北京大学力学系几位老师的教学推广工作)。向开源原理与历史学习激励我们编写了一份教材:《科学计算自由软件-SCILAB教程》,(清华大学出版社, 2003年1月,在此感谢赵星博士与康孟珍博士)。就我所知,这应是国内第一本包含版权协议与开源内容的计算机教材。体现了思想原理大于技术细节的教学理念。我们中法实验室LIAMA在与国内多所大学合作从2001年起举办研讨会,2002年起增加软件竞赛之后(在此感谢所有曾支持或参与推广Scilab活动的人员),我个人参照Linux企鹅图标方式为Scilab设计了海鹦(Puffin)吉祥物(在此感谢张之益老师相助完成图标计算机绘制)。其中采用卡通形象的海鹦高昂着头寓意:“创开源,我自豪”。英文解释语为“Be Proud of Developing Open Source”[1]。这个说法也是针对当时微软企业在国内推销产品时的用语:“用正版,我自豪”。而我理解应是“用正版,我坦然。创开源,我自豪”的价值观。同学们的参赛作品让我们看到了中国学生是太优秀了。可惜的是我们教育机构及老师们引导工作是否做到位了?我个人也是出国留学后才逐步明白“走创新之路”道理[2],经历了懵懂到开窍的过程。许多创造可能不是能力问题,而是观念问题。学生时代如果有了好的知识产权文化并具体实践开源软件,中国发展是否能有另一番景象?
最后建议读者了解一下大西洋海鹦[3],它犹如大熊猫一样可爱。而法文维基百科海鹦栏目中还介绍了我的作品[4]。特别感谢法国两位科学家对自由软件Scilab与海鹦吉祥物作出的进一步诠释[5]。读者还可以看到更多开源软件的吉祥物[6],是不是很好玩?不知你会有否冲动也设计一个吉祥物?
1. http://www.nlpr.ia.ac.cn/2005papers/gjhy/gh68.pdf
2. http://www.doc88.com/p-2502490697770.html
3. https://en.wikipedia.org/wiki/Atlantic_puffin
4. https://fr.wikipedia.org/wiki/Macareux_moine
5. http://ftp.sun.ac.za/ftp/pub/mirrors/scilab/www.scilab.org/puffin/puffin.html
6. http://chl.be/mascots/
前期课程链接:
第一讲:
国科大UCAS《信息论与机器学习》课程,中国科学院自动化研究所胡包钢研究员
第二讲:
国科大UCAS胡包钢教授《信息论与机器学习》课程第二讲:信息论基础一
第三讲:
国科大UCAS胡包钢教授《信息论与机器学习》课程第三讲:信息论基础二
第四讲:
熵与其它信息量估计—国科大UCAS胡包钢教授《信息论与机器学习》课程第四讲
课件文件:

































附录文件:













专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“ITML2020” 就可以获取《国科大UCAS《信息论与机器学习》课件》专知下载链接






