魔改Attention大集合

极市导读
如何对attention进行高效改进?本文盘点了相关论文,并梳理出它们的引用量、代码实现、算法复杂度和关键点,方便对比使用。
Efficient Attention
| Paper (引用量) | 源码实现 | 复杂度 | AutoRegressive | Main Idea |
|---|---|---|---|---|
| Generating Wikipedia by Summarizing Long Sequences[1] (208) | memory-compressed-attention[2] |
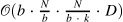 |
 |
|
| CBAM: Convolutional Block Attention Module[3] (677) | attention-module[4]  |
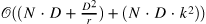 |
|
|
| CCNet: Criss-Cross Attention for Semantic Segmentation[5] (149) | CCNet[6] |
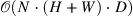 |
|
|
| Efficient Attention: Attention with Linear Complexities[7] (2) | efficient-attention[8] |
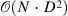 |
|
|
| Star-Transformer[9] (24) | fastNLP[10] |
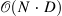 |
|
|
| Generating Long Sequences with Sparse Transformers[11] (139) | torch-blocksparse[12] |
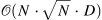 |
 |
|
| GCNet: Non-local Networks Meet Squeeze-Excitation Networks and Beyond[13] (96) | GCNet[14]  |
|
|
|
| SCRAM: Spatially Coherent Randomized Attention Maps[15] (1) | - | 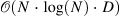 |
|
|
| Interlaced Sparse Self-Attention for Semantic Segmentation[16] (13) | IN_PAPER | 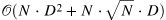 |
|
|
| Permutohedral Attention Module for Efficient Non-Local Neural Networks[17] (2) | Permutohedral_attention_module[18] |
|
|
|
| Large Memory Layers with Product Keys[19] (28) | XLM[20] |
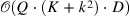 |
|
|
| Expectation-Maximization Attention Networks for Semantic Segmentation[21] (38) | EMANet[22] |
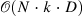 |
|
|
| Compressive Transformers for Long-Range Sequence Modelling[23] (20) | compressive-transformer-pytorch[24] |
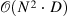 |
|
|
| BP-Transformer: Modelling Long-Range Context via Binary Partitioning[25] (8) | BPT[26] |
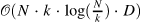 |
|
|
| Axial Attention in Multidimensional Transformers[27] (5) | axial-attention[28] |
|
|
|
| Reformer: The Efficient Transformer[29] (69) | trax[30] |
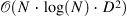 |
|
|
| Transformer on a Diet[31] (2) | transformer-on-diet[32] |
|
||
| Sparse Sinkhorn Attention[33] (4) | sinkhorn-transformer[34] |
|
||
| SAC: Accelerating and Structuring Self-Attention via Sparse Adaptive Connection[35] (1) | - | |
||
| Efficient Content-Based Sparse Attention with Routing Transformers[36] (11) | routing-transformer[37] |
|
||
| Longformer: The Long-Document Transformer[38] (15) | longformer[39] |
|
||
| Neural Architecture Search for Lightweight Non-Local Networks[40] (2) | AutoNL[41] |
|
||
| ETC: Encoding Long and Structured Data in Transformers[42] (2) | - | |
||
| Multi-scale Transformer Language Models[43] (1) | IN_PAPER | |
||
| Synthesizer: Rethinking Self-Attention in Transformer Models[44] (5) | - | |
||
| Jukebox: A Generative Model for Music[45] (9) | jukebox[46] |
|
||
| GMAT: Global Memory Augmentation for Transformers[47] (0) | gmat[48] |
|
||
| Masked Language Modeling for Proteins via Linearly Scalable Long-Context Transformers[49] (0) | google-research[50] |
|
||
| Hand-crafted Attention is All You Need? A Study of Attention on Self-supervised Audio Transformer[51] (0) | - | |
||
| Transformers are RNNs: Fast Autoregressive Transformers with Linear Attention[52] (1) | fast-transformers[53] |
|
||
| Linformer: Self-Attention with Linear Complexity[54] (3) | linformer-pytorch[55] |
|
||
| Real-time Semantic Segmentation with Fast Attention[56] (0) | - | |
||
| Fast Transformers with Clustered Attention[57] (0) | fast-transformers[58] |
|
||
| Big Bird: Transformers for Longer Sequences[59] (0) | - | |
推荐阅读




登录查看更多
相关内容

Attention机制最早是在视觉图像领域提出来的,但是真正火起来应该算是google mind团队的这篇论文《Recurrent Models of Visual Attention》[14],他们在RNN模型上使用了attention机制来进行图像分类。随后,Bahdanau等人在论文《Neural Machine Translation by Jointly Learning to Align and Translate》 [1]中,使用类似attention的机制在机器翻译任务上将翻译和对齐同时进行,他们的工作算是是第一个提出attention机制应用到NLP领域中。接着类似的基于attention机制的RNN模型扩展开始应用到各种NLP任务中。最近,如何在CNN中使用attention机制也成为了大家的研究热点。下图表示了attention研究进展的大概趋势。



相关VIP内容
相关资讯
相关论文