基于动态表示和决策门的深度神经网络有效推理|厚势汽车

作者:Mohammad Saeed Shafiee*
编译:同济智能汽车研究所
编辑:啜小雪
入群:加微信号autoHS,入厚势汽车科技群与行业专家讨论更多信息
摘要:在神经网络的深度和其计算成本之间难以权衡的问题使得当前很难将深度神经网络应用于许多工业应用,尤其是在计算能力有限的情况下。在这篇文章中,我们受到这样的想法启发:虽然需要更深的嵌入来区分复杂的样本,但是通过较浅的嵌入可以很好地区分大批量的样本。在本研究中,我们介绍了决策门(d-gate)的概念,训练这些模块来决定是否需要将样本投影到更深的嵌入中,或者是否可以在决策门进行早期预测,从而能够计算不同深度的动态表示。所提出的决策门模块可以与任何深度神经网络集成,并且在保持建模精度的同时降低深度神经网络的平均计算成本。实验结果表明,在 CIFAR10 数据集上训练后,利用提出的决策门模块,ResNet-101 加速约 38%,FLOPS 减少约 39%,DenseNet-201 加速约 46%,FLOPS 减少约 36%,精度仅下降约 2%。
一、介绍
之前的研究[16]已经表明,更深层的网络架构通常会带来更好的建模性能;然而,更深层的网络架构也会带来一些问题。除了变得更容易过拟合和更难训练之外,深度和计算成本之间的权衡使得许多工业应用很难采用更深的架构。
He 等人[7]通过引入残差学习的概念,解决了深层神经网络学习中的退化问题(例如梯度消失),其中学习是基于残差映射,而不是直接基于未参照映射。紧随其后是,Xie 等人[19]利用残差块结构中的初始思想(即分裂-变换-合并策略)来提供更好的子空间建模,同时解决退化问题,从而得到具有改进建模精度的 ResNext 体系结构。为了解决计算成本问题,人们提出了各种各样的方法,包括:精度降低[10]、模型压缩[6]、师生策略[8]和进化算法[13,14]。
最近,条件计算[1,4,12,18,2]和早期预测[17]方法已经被提出来处理这个问题,这些方法涉及网络内不同模块的动态执行。条件计算方法在很大程度上受到以下思想的推动:残余网络可被视为较浅网络的集合。因此,这些方法利用跳跃连接来确定哪些剩余模块需要执行,其中大多数利用了增强学习。
在本研究中,我们主要探究早期预测这个想法,但取而代之的是从软边际支持向量机[3]理论中得到决策启示。特别地,我们引入决策门的概念,训练模块以决定是否需要将样本投影到更深的嵌入中,或是否可以在决策门处进行早期预测,从而能够在不同深度上进行动态表示的条件计算。所提出的决策门模块可以与任何深层神经网络集成,而不需要从头训练网络,从而在保持模型精度的同时降低了深层神经网络的平均计算复杂度。

图1 决策门被直接集成到深层神经网络中,并且被训练来预测决策是在决策门处做出还是需要投影到深层嵌入中。
二、方法论
与浅层结构相比,深层神经网络结构能够提供更好的数据子空间嵌入,从而能够更好地区分数据空间,进而得到更好的建模精度。受软边际支持向量机[3]理论的启发,我们提出了一个假设,尽管对于在较低的网络层的并且位于决策边界的上的样本使用更深的嵌入式子空间是必要的,但是他们实际上对于那些在浅层嵌入式空间并且已经远离决策边界的点已经不重要了。因此,用于确定样本与网络下层中的决策边界之间的距离的有效机制将使得能够在不将样本投影到更深的嵌入空间中,对这些样本执行早期预测成为可能。这种方法将大大降低预测的平均计算成本。然而,设计一种有效的方法来确定样本是否为边界样本是一个具有挑战性的问题。
这里,我们将早期预测问题描述为风险最小化问题,并引入一组直接集成到深层神经网络(参见图1)的单层前向传播网络(我们称为决策门)。决策门模块的目标不仅是确定样本是否需要投影到深嵌入空间中,而且还最小化早期错误分类的风险。具体而言,我们训练决策门模块,该决策门模块通过铰链损耗[5]集成到深度神经网络中,该铰链损耗[5]使得在较低嵌入中早期误分类的风险最小化,同时决定样本是否是边界样本:
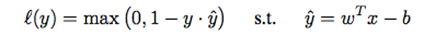
其中,y 是输入数据x的真值标签,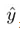
决策门模块是通过用于训练深层神经网络的训练数据来训练的,每个决策门模块的目标是最小化训练数据的分类误差。因此,训练数据上的损失函数可以表述为:
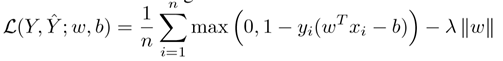
其中 Y 表示所有训练数据的地面实况标记集。关于 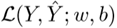
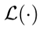
在本质上,所提出的决策门模块可以基于 wTx-b 计算每个样本到决策边界的距离;计算出的距离与各决策门决策阈值t比较以确定是否需要对样品在决策门进行早期预测,或者将样本移动到深度神经网络的更深的网络阶层来提高预测的效果。远离决策边界的样本导致在 wTx-b 中输出较大值;因此,如果样本的决策门距离满足决策门决策阈值,则对应于最大距离的类被分配为该早期预测步骤中样本的预测类标签。
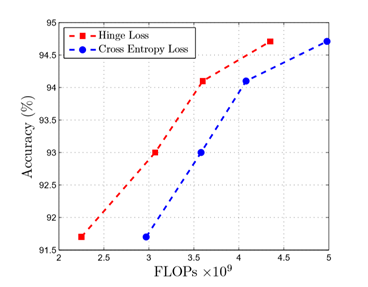
图2:精确度与 FLOP 的数量:通过建议的铰链损失训练有决策门的网络的性能与通过传统的交叉熵损失方法训练的决策门进行比较。可以看出,通过铰链损耗训练的决策门比使用交叉熵损耗时具有更高的计算效率和更高的精度
表1:ReNET-101 和 DeNeNET-201 的实验结果与不同的决策门配置。将每个配置的触发器的平均数和精度与原始网络的平均数进行比较。决策门(T1,T2)表示具有两个决策门模块的网络,分别配置有决策阈值 T1 和 T2。

三、结果与讨论
在 CIFAR10 数据集上,使用两种不同的网络体系结构(ResNet101[7]和DenseNet201[9])来检验所提出的决策门模块的有效性。该决策门模块的一个主要优点是它能够通过调整 d 门决策阈值,进而精确控制建模精度和计算成本之间的平衡。通过降低决策门决策阈值,增加进行早期预测的样本数,从而大大降低网络的预测平均计算成本。在这项研究中,我们结合两 Resnet-101 决策门模块(在第一和第二主块)和 Densenet-201(后的第一和第二的致密块),并探讨不同的决策门配置。在 Pytorch 框架中实现网络,并且基于单个 Nvidia TITAN XP GPU 报告预测速度。
从表 1 中可以观察到,通过集成具有(t1,t2)=(2.5,2.5)的决策阈值的两个决策门模块,ResNet 网络的计算成本可减少 67MFLOPS,同时保持与原始 ResNet-101 相同的精度水平。决策门模块的集成可以使 ResNet-101 网络的计算成本降低 39%(即降低1.95GFLOPS),与原始的 ResNet-101(在决策门 1 和决策门 2 中具有距离阈值(t1,t2)=(1.0,2.0))相比,准确度降低 1.7%,导致 38% 的加速。对 DenseNet-201 的试验表明,在精度只有 2% 下降的情况下,将 FLOP 的数量减少 970MFLOP(36%)是可能的,从而加速 46%。此外,在精度 3% 的范围内,使用决策门模块可以达到与原来的 DenseNet-201 相比 2.3 倍的加速。基于实验结果,提出的决策门模块导致预测速度显著增加,使得它非常适合于工业应用。
除了提出的决策门模块外,本文的主要贡献之一是引入了用于训练决策门模块的铰链损耗。过去的研究[11]认为交叉熵在决策边界和训练数据之间产生的差距很小。因此,由于 Softmax 输出中没有有价值的信息,所以很难信任 Softmax 层的置信值来决定样本。为了验证所提出的决策门中铰链损耗与交叉熵损耗相比的有效性,进行了额外的对比实验。更具体地,两个决策门以与报告相同的方式添加到 ResNET101。然而,不是训练使用建议的铰链损耗,而是通过交叉熵损失来训练决策门。这使我们能够比较铰链损耗与交叉熵损失对决策门功能的影响。
图 2 显示了基于所提议的铰链损失法训练决策门的网络的精确度与 FLOP 的数量,与使用常规交叉熵训练过程训练相比。可以观察到,在网络中具有相同数量的 FLOP 的情况下,基于所提出的铰链损耗训练决策门的网络与通过交叉熵损耗训练的网络相比,提供了更高的建模精度。当判决门被配置成使得网络使用较少数量的触发器时,精度间隙呈指数增加。这说明了上述使用交叉熵损失和决策边界的问题。
参考文献
[1] Emmanuel Bengio, Pierre-Luc Bacon, Joelle Pineau, and Doina Precup.Conditional computation in neural networks for faster models. arXiv preprintarXiv:1511.06297, 2015.
[2] Tolga Bolukbasi, Joseph Wang, Ofer Dekel, and Venkatesh Saligrama.Adaptive neural networks for efficient inference. arXivpreprint arXiv:1702.07811, 2017.
[3] Corinna Cortes and Vladimir Vapnik. Support-vector networks. Machinelearning, 20(3):273–297, 1995.
[4] Ludovic Denoyer and PatrickGallinari. Deep sequential neural network.arXiv preprint arXiv:1410.0510, 2014.
[5] Ürün Dogan, Tobias Glasmachers, and Christian Igel. A unified viewon multi-class support vector classification. Journal ofMachine Learning Research, 17(45):1–32, 2016.
[6] Song Han, Huizi Mao, and William J Dally. Deep compression:Compressing deep neural networks with pruning, trained quantization and huffmancoding. arXiv preprint arXiv:1510.00149, 2015.
[7] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residuallearning for image recognition. In Proceedings of the IEEE conference oncomputer vision and pattern recognition, pages 770–778, 2016.
[8] Geoffrey Hinton, Oriol Vinyals, and Jeff Dean. Distilling theknowledge in a neural network. arXiv preprint arXiv:1503.02531, 2015.
[9] Gao Huang, Zhuang Liu, Laurens Van Der Maaten, and Kilian QWeinberger. Densely connected convolutional networks. In CVPR, volume 1, page3, 2017.
[10] Benoit Jacob, Skirmantas Kligys, Bo Chen, Menglong Zhu, Matthew Tang,Andrew Howard, Hartwig Adam, and Dmitry Kalenichenko. Quantization and trainingof neural networks for efficientintegerarithmetic-only inference. arXiv preprint arXiv:1712.05877, 2017.
[11] Xuezhi Liang, Xiaobo Wang, Zhen Lei, Shengcai Liao, and Stan Z Li.Soft-margin softmax for deep classification. In InternationalConference on Neural Information Processing, pages 413–421. Springer, 2017.
[12] Lanlan Liu and Jia Deng. Dynamic deep neural networks: Optimizingaccuracy-efficiency trade-offs by selective execution. arXivpreprint arXiv:1701.00299, 2017.
[13] M. Shafiee, A. Mishra, and A. Wong. Deep learning withdarwin: Evolutionary synthesis of deep neural networks. arXiv:1606.04393, 2016.
[14] M. Shafiee and A. Wong. Evolutionary synthesis of deepneural networks via synaptic cluster-driven genetic encoding. In NIPS Workshop,2016.
[15] Shai Shalev-Shwartz, Yoram Singer, Nathan Srebro, and Andrew Cotter.Pegasos: Primal estimated subgradient solver for svm. Mathematical programming,127(1):3–30, 2011.
[16] Karen Simonyan and Andrew Zisserman. Very deep convolutional networksfor large-scale image recognition. arXiv preprint arXiv:1409.1556, 2014.
[17] Surat Teerapittayanon, Bradley McDanel, and HT Kung. Branchynet: Fastinference via early exiting from deep neural networks. In Pattern Recognition(ICPR), 2016 23rd International Conference on, pages 2464–2469. IEEE, 2016.
[18] Zuxuan Wu, Tushar Nagarajan, Abhishek Kumar, Steven Rennie, Larry SDavis, Kristen Grauman, and Rogerio Feris. Blockdrop: Dynamic inference pathsin residual networks. In Proceedings of the IEEE Conference on Computer Visionand Pattern Recognition, pages 8817–8826, 2018.
[19] Saining Xie, Ross Girshick, Piotr Dollár, Zhuowen Tu, and Kaiming He.Aggregated residual transformations for deep neural networks. In ComputerVision and Pattern Recognition (CVPR), 2017 IEEE Conference on, pages5987–5995. IEEE, 2017.
-END-
文章精选
---自动驾驶---
---厚势汽车科技周报---
厚
势
汽
车
为您对接资本和产业
新能源汽车 自动驾驶 车联网
联系邮箱
sasa@ihoushi.com

点击阅读原文,查看文章「康奈尔大学:一种用于测试自动驾驶深度学习的工具DeepTest」



