干货 | 聚焦「信息压缩」,IBM 携手 MIT 再解读「信息瓶颈」理论

提出有效的互信息评估方式,并将聚类引入「信息压缩」。
AI 科技评论按:深度学习的发展带给人工智能领域的影响可谓是革命性的,然而该领域目前还存在很多未解决的问题,其中就包括不可解释性等问题。而希伯来大学计算机科学家和神经学家Naftali Tishby 等人提出的「信息瓶颈」理论,则尝试来解决神经网络的一系列问题,自提出以来便一直受到 AI 界的广泛关注。IBM 研究院也开展相关研究来分析这一理论,以期能够解决神经网络中的某些问题,相关成果发表在 IBM 研究院官网博客上,AI 科技评论编译如下。
虽然对于神经网络理论的研究工作日趋增多,但我们对于深度学习的宏观行为理解仍存在许多不足之处。例如,训练期间由哪些因素驱动内部表征的演变、学习到的表征属性以及如何充分训练神经网络去处理信息等方面存在的问题,一直都没有得到解决。此外,我们对于神经网络的了解大多数都源于揣测,而缺乏实证。
「信息瓶颈」理论试图解决上述这些问题。作为 MIT- IBM Watson AI 实验室双方密切合作的成果,我们在 2019 年国际机器学习大会(ICML)会议论文「深度神经网络中信息流的评估」(Estimating Information Flow in Deep Neural Networks),从数学和经验的角度对「信息瓶颈」理论进行了分析,其中更是特别聚焦于其预测的「信息压缩」现象。
「信息瓶颈」理论
「信息瓶颈」理论(Schwartz-Ziv & Tishby 2017 年论文等,见参考文献)试图解释涉及信息压缩的神经网络泛化问题,这个概念是指在神经网络学习对输入编码时,输入 X 和隐藏层 T(图 1)之间的互信息在训练过程中迅速上升,之后在神经网络学习丢弃与任务无关的非关联信息(图 2)时,该互信息缓慢下降(压缩)。每一个连续的层都被视为在不断压缩输入。最终证明,这种淘汰掉无关信息的方式,可以使分类器的泛化效果更好,因为这样的话,当被给定一种新的此前从未见过的输入,神经网络仅仅提取出相关信息,而不会受到无关信息的误导。
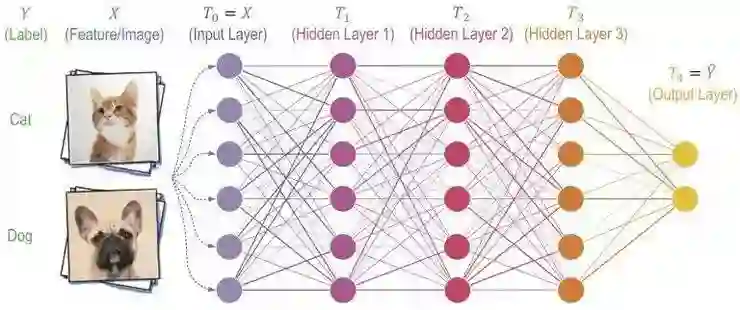
图 1:深度神经网络的前馈(假设的)
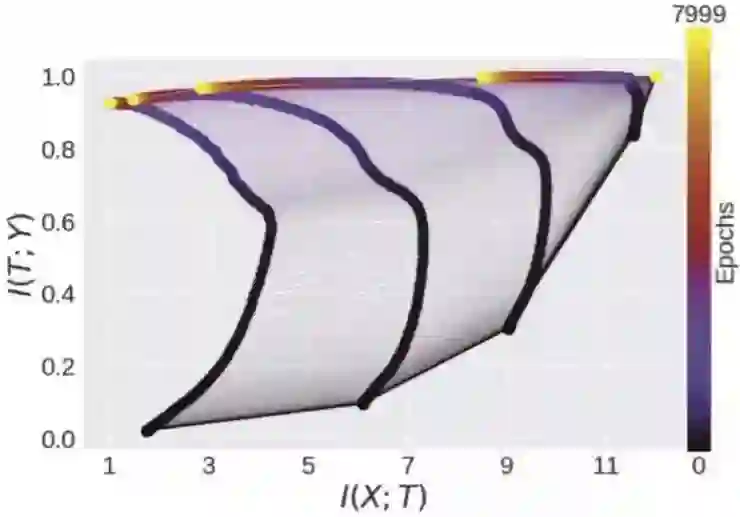
图 2:信息瓶颈。图中显示了训练过程中 5 个隐藏层中互信息的轨迹
虽然某种程度上这是一个较为诱人的观点,但遗憾的是,当网络是确定性的时候,输入 X 和隐藏层 T 之间的互信息并不依赖于网络参数(而在实践中,几乎所有的神经网络都是确定性的)。为了解决这个问题,先前的工作通过对每个神经元进行分箱处理(量化)和互信息进行计算(成为分箱隐藏层的离散熵),得出互信息的估计值。图 3 表明该计算与分箱大小高度相关,从而证实它并没有对互信息进行计算。

图 3:分箱估计的不连续性
噪声神经网络与互信息评估
当网络是确定性的时候,互信息是非信息性的,而当网络是随机性的时候,互信息是富信息性的。因此,我们通过在每个神经元输出中添加高斯噪声 Z 来定义形成的噪声神经网络(图 4)。这种噪声同时存在于神经网络的训练和测试中,从而使相关的互信息评估变得有意义。在这种情况下,我们提出了一种有效的互信息评估方式,它能以极大极小最优速度收敛为真实的互信息(且不依赖于分箱)。

图 4:噪声神经网络
将聚类作为压缩的驱动因素
我们的论文通过将单神经元分类和噪声通道上的信息传输联系起来,能够开发出一个数学直觉,即信息压缩(在随机网络中严格观察或在确定性网络中使用分箱估计)通常都应该由内部表征聚类引起。具体来说就是,在隐藏表征 T 中,映射同一类 Y 的不同输入 X 的隐藏层与彼此越来越接近。
要从经验上评估这一点,可参考 Schwartz-Ziv、 Tishby 在其 2017 年一篇论文中提出的数据和模型,该模型使用具有双曲正切函数(tanh)激活的全连接 12-10-7-5-5-4-3-2 体系结构对 12 维输入进行二进制分类。图 5 显示了标准偏差 0.005(测试精度 97%)的加性噪声结果,说明了各训练期中互信息估计、训练/测试损失和不断演变的内部表征之间的关系。互信息的上升和下降对应着表征在每一层中的扩展或聚合程度。例如,当高斯函数开始沿着一条曲线彼此偏离时(参见顶部第 5 层隐藏表征的散点图),在 28 epoch 之前,互信息一直呈增长趋势;到 80 epoch 左右,它们开始聚合,互信息随之下降。随着训练的进行,饱和的双曲正切单元将高斯函数推到立方体的相反角落,进一步减少了互信息。
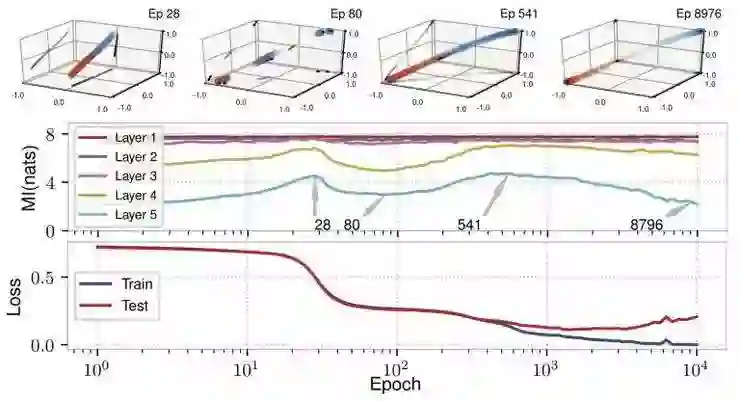
图 5:训练过程中的 I(X;Y) 压缩。最上面一行显示的是在选定 epochs 中隐藏表征的最终层的散点图,按颜色进行类标签编码
如图 6 所示,我们使用权重的正交规范化规则(Cisse 等人 2017 年论文),不仅可以消除这种压缩,实际上也改进了泛化。隐藏表征不再聚合在一起,这与信息压缩的缺失是直接对应的。我们在这方面进行了更多的实验,从而有力地证实了信息压缩是由聚类引起的。
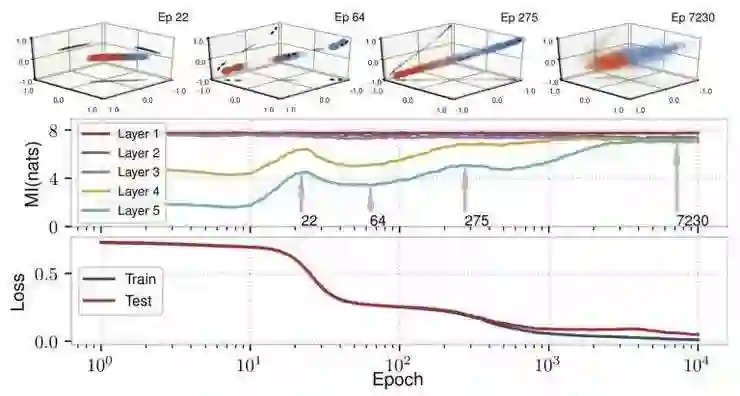
图 6:使用正交规范化消除压缩
其他重要说明
由聚类引起的「压缩」概念之所以重要,基于两个原因。首先,它揭开了「信息压缩」的神秘面纱,用一个更具体的公式取而代之。其次,它为直接研究聚类打开了大门,聚类可能不会遭遇源自与互信息估计相关的维数的极端「诅咒」(我们证明了样本复杂度在维数上呈指数级增长)。事实上,我们能够将聚类的若干(初步的)测量方法延展到针对 MNIST 扫描数字任务进行分类的全卷积神经网络上,从而在训练过程中观察到类似的「压缩」行为。
此外,与「信息瓶颈」理论相反,我们发现压缩对于泛化来说并不是必要的,不过,鼓励使用压缩(通过几何聚类)是否能够促进更好的泛化性能仍然是一个有待解决的问题。
论文:Estimating Information Flow in Deep Neural Networks
论文作者:Ziv Goldfeld, Ewout van den Berg, Kristjan Greenewald, Igor Melnyk, Nam Nguyen, Brian Kingsbury, Yury Polyanskiy
论文下载地址:https://www.research.ibm.com/artificial-intelligence/publications/paper/?id=Estimating-Information-Flow-in-Deep-Neural-Networks
参考文献:
[Shwartz-Ziv, R. and Tishby, N. Opening the black box of deep neural networks via information. arXiv:1703.00810, 2017]
[Cisse, M., Bojanowski, P., Grave, E., Dauphin, Y., and Usunier, N. Parseval networks: Improving robustness to adversarial examples. In Proceedings of the International Conference on Machine Learning (ICML), 2017]
via:https://www.ibm.com/blogs/research/2019/06/deep-neural-networks/
2019 年 7 月 12 日至 14 日,由中国计算机学会(CCF)主办、雷锋网和香港中文大学(深圳)联合承办,深圳市人工智能与机器人研究院协办的 2019 全球人工智能与机器人峰会(简称 CCF-GAIR 2019)将于深圳正式启幕。
届时,诺贝尔奖得主JamesJ. Heckman、中外院士、世界顶会主席、知名Fellow,多位重磅嘉宾将亲自坐阵,一起探讨人工智能和机器人领域学、产、投等复杂的生存态势。

今日限量赠送3张1000元门票优惠码,门票原价1999元,打开以下任一链接即可使用,券后仅999元,限量3张,先到先得,送完即止。
https://gair.leiphone.com/gair/coupon/s/5d0763011a53f
https://gair.leiphone.com/gair/coupon/s/5d0763011a2f6
https://gair.leiphone.com/gair/coupon/s/5d0763011a01e




