WSDM Cup 2020 引用意图识别赛道冠军解决方案(附答辩视频、PPT和代码)
发现、新理论的研究论文发表数量呈指数型增长,并且论文被引用量(H-index)通常被学术界衡量论文的影响力贡献程度。然而,随着学术界的竞争越来越激烈,部分期刊中出现了一种“强制引用”的情况,也是就论文作者需要引用该期刊的相关文章,以提高期刊的影响因子。这些行为是对任何科学家和技术人员所要求的最高诚信的冒犯,并且如果任其发展,可能会破坏公众的信任并阻碍科学技术的未来发展。该竞赛是该系列竞赛中的第一场竞赛,探讨了网络搜索和数据挖掘技术在多大程度上可以用来区分多余的引文和真实的引用识别。赛题详解可参考:https://biendata.com/competition/wsdm2020/
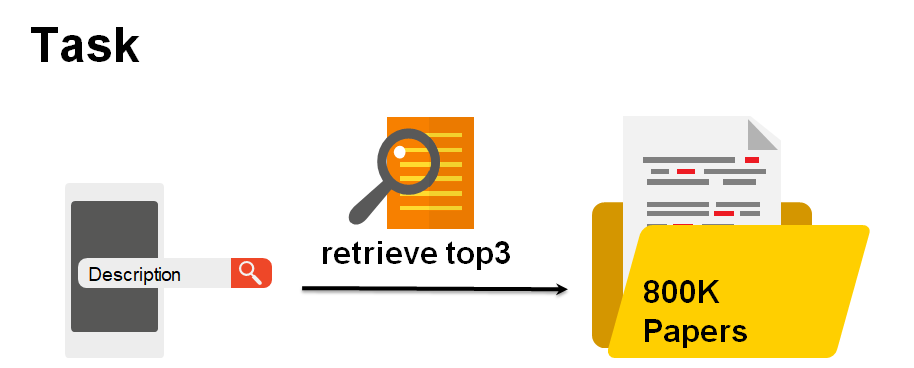
冠军方案
作者:应承轩
学校:大连理工大学
个人网站:https://ying.cx/
研究方向:信息检索
答辩视频:
解决方案:https://github.com/chengsyuan/WSDM-Adhoc-Document-Retrieval
摘要
对语义检索任务的最新研究表明,像BERT这样的预训练语言模型具有令人印象深刻的重排序性能。在重排序过程中,将使用(查询,文档)对来提供经过微调的语言模型,并且整个时间复杂度与查询大小和召回集大小均成正比。在本文中,我们基于置信度得分描述了一种简单而有效的提前停止策略。在我们的实验中,这种策略可以避免多达30%的不必要的推理计算成本,而不会牺牲太多的排名精度。
代码:https://github.com/chengsyuan/WSDM-Adhoc-Document-Retrieval
「Our team dlutycx ranked first on the unleak track.」

方案
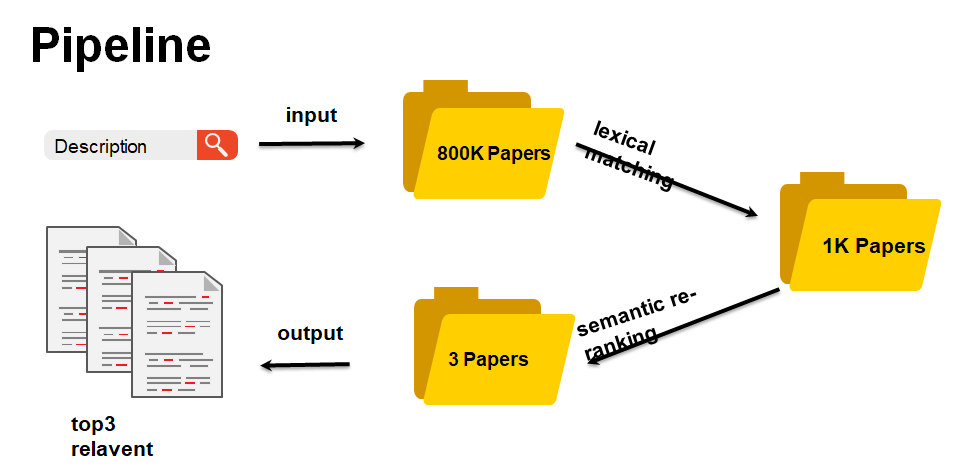
我们的方案主要分为三个主要阶段:
-
数据清洗:数据丢失的文档将被删除,与此任务无关的文本也将被删除。 -
召回阶段:通过无监督方式(例如BM25或文档嵌入相似性)从整个候选文档数据库中检索设置给定问题的候选集。 -
排序阶段:这些文档中的每一个都通过一种计算精准度更高的方法进行评分和排名。
数据清洗
在清理步骤中,我们仅删除丢失的数据。然后,我们清除与主题不直接相关的文本。具体而言,我们删除引文中每个句子不包含("「##」").
召回阶段
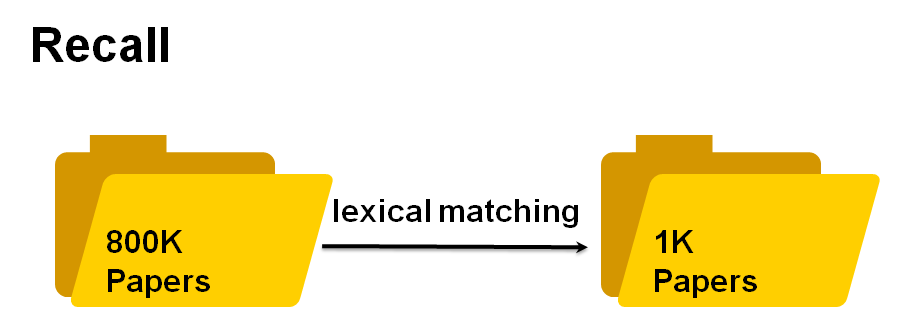
在召回步骤中,我们使用Okapi BM25来衡量查询和文档之间的词汇相似度。计算公式如下:
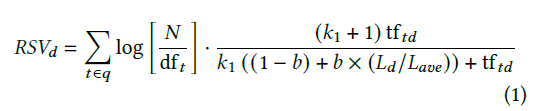
排序阶段
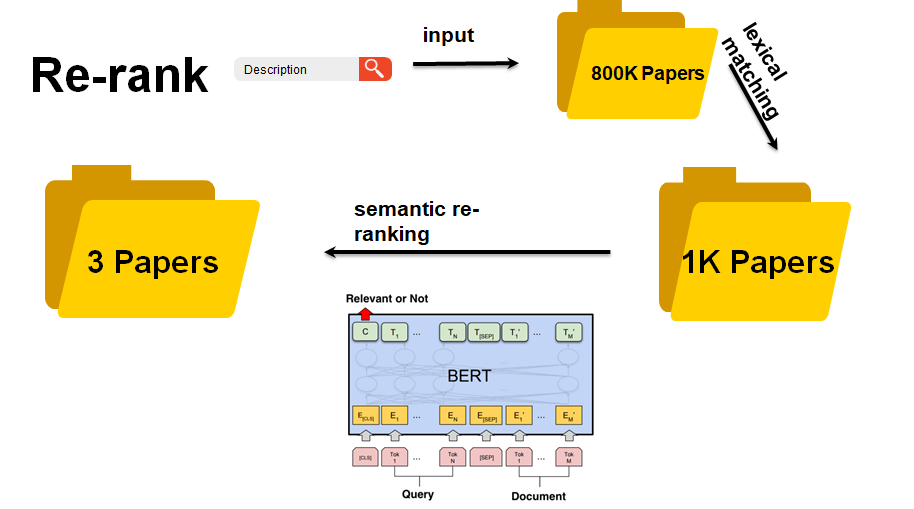
在重排序步骤中,我们使用预先训练的BioBERT获得相似性评分。然后,采用交叉熵损失来微调BioBERT:
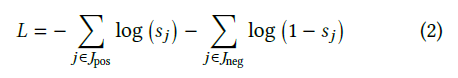
其中 是相关段落的索引集, 是使用BM25检索的前20个文档中不相关段落的索引集。为了平衡正负比率,我们对正文档19x进行了过度采样。
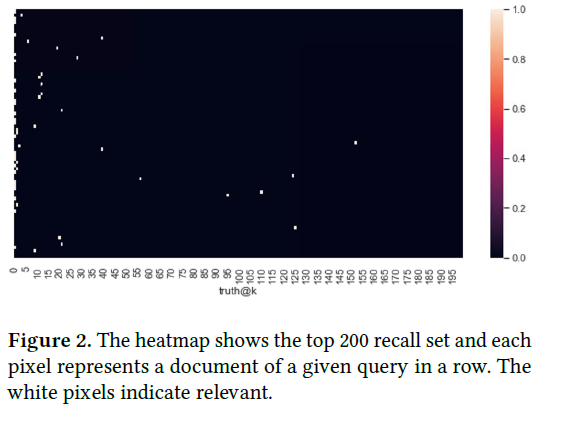
对BioBERT进行微调后,在重新排序时,我们将此模型用作固定评分器 。在以下算法中,我们描述了广泛使用的常规重排策略:如算法1所示,常规重排序策略是简单地遍历召回集中的每个文档。正如我们在图2中可以看到的,真实文档不是均匀分布的。它们聚集在最高位置。为了解决这个问题,我们设计了一种早期停止策略。如算法2所示,当重新排名(经过微调的BERT模型)显示高置信度时,我们可以认为此文档是最相关的文档。

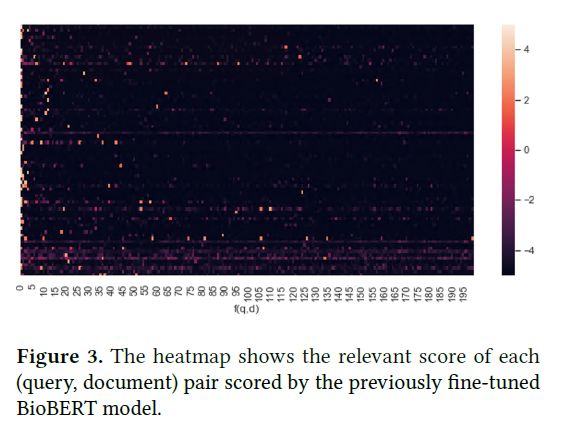
如图3所示,最高分的分布与图2不同。如果在重排序过程中采用算法2,则如果不相关的文件的得分大于正数,则我们可能会误将不相关的文件检索为正确文件。误报文件高于阈值。为了缓解这种问题,我们提出了一种自适应的提前停止重新排序策略,如算法3所示。我们相信基于经验的批处理大小𝑏atch size可以减少假阳性文档,并获得
增益(排行榜的指标)。


更多详细细节可以参考原始论文的解决方案:An Adaptive Early Stopping Strategy for Query-based Passage Re-ranking http://www.wsdm-conference.org/2020/wsdm_cup_reports/Task1_dlutycx.pdf
专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“WSDM2020” 就可以获取《答辩视频、PPT、论文》论文专知下载链接






