应对时间序列问题有何妙招(Kaggle比赛亚军)
Kaggle 上 Corporación Favorita 主办的商品销量预测比赛于两个月前落下帷幕,此次比赛的奖金池共计三万美元,吸引到 1675 支队伍参赛。
这场比赛是基于时间序列数据的基础机器学习问题,论文中阐明了总体分析和解决方案。本文作者在比赛中取得了第二名的成绩。
比赛地址:https://www.kaggle.com/c/favorita-grocery-sales-forecasting
论文地址:https://arxiv.org/pdf/1803.04037.pdf
作者的方法基于空洞卷积神经网络(dilated convolutional neural network)并进行了改善,来对时间序列进行预测。利用这种技术,在 n 个示例批次中不断迭代,能够快速和准确地对大量时间序列数据进行处理。
比赛背景
Kaggle 等竞赛平台举办的时间序列比赛目前已经成为机器学习流行赛事,这些竞赛有助于推进机器学习顶尖技术的发展,将其用于实际领域。
时间序列是不太为人所知的分析领域。由于数据存在着季节性、动态性和周期性的特征,数据序列是非线性的,并存在噪声,因此很难准确进行识别和预测。
神经网络在近几年的热度急剧增长,这使人们对预测有了截然不同的理解。硬件的进步使得我们能够在一定时间内利用深度神经网络解决问题。目前,深度学习是一个可行的解决方案,利用这项技术,近年来研究者们在基准数据集的分类精度上打破了很多记录。
作者在本文中讨论了解决 Corporacion Favorita Grocery Sales Forecasting 商品销量预测问题的方法,描述并分析了将卷积神经网络应用于时间序列数据。
数据集描述
数据被分为两部分——训练数据和测试数据。训练数据用于模型训练,测试数据被分为几部分,分别用于在公共和私人的排行榜上进行模型的准确性评估。这场比赛中,Corporacion Favorita 提供 125,497,040 个训练观察值和 3370,464 个测试观察值。
数据集由按日销售额、商店编号、商品编号和促销信息组成。此外,主办方还提供交易信息、石油价格、商店信息和假期。
该竞赛使用 NWRMSLE(标准化加权均方根对数误差)作为评价指标。
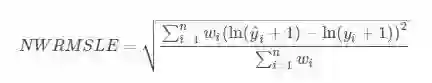
问题定义
实体店中的采购和销售需要保持平衡。稍微将销售预测过量,店里就会积存许多货物,要是积压了不易储存的商品会更加糟糕。而要是将销量预测过低,设想一下,当顾客把钱都付了,却发现没货,那这家店的口碑将会急剧下降。
此外,随着零售商增加新的门店,那里的顾客又可能存在独特的需求,比如他们想要新的产品,口味随季节而变化,那问题将变得更加复杂,产品市场如何真的很难预知。
在这次比赛中,主办方希望参赛者建立一个更准确的预测产品销量的模型。作者的目标是建立一个可能应用于实际,并具有最高准确度的销量预测模型。
主要存在如下三种挑战:
噪声数据:尽管组织者尽力准备并提供了大量数据,但其中存在有噪声标签的数据。有些数据(石油价格、假期、交易)与目标没有关联,在之后根本不会使用。
不可见数据:有这样一种情况,在测试集中出现了不可见的数据。由于存在这类不可见的商店/商品数据,模型的行为将不可预测。原因如下:训练集中不包括销售额为 0 的记录,但是测试集包含所有的商店/商品组合(不管商店此前是否销售该商品)。最后,作者假设这些不可见的组合只是零销售额数据,用 0 来进行替换。
准确度:因为这个实验是严格按照比赛规则进行的,作者尝试了所有可能用来提高预测准确度的方法。
可选方案
下面的这些架构基于神经网络,但在这个比赛中,最终结果不如作者最后使用的 WaveNet 模型,但他们相信这种架构可以提供一种完全不同的方法来解决问题,产生出一些有趣的洞见,甚至在其他比赛中超越 WaveNet。
循环神经网络
循环神经网络(RNN)可以将当前节点的输出作为下一个节点的输入,可以如下描述:相较于其他深度学习算法,RNN 已经被广泛用于预测时间序列问题,并被定位为预测此类数据数组问题的最先进的方法。
这些网络的效率可以通过重复的连接来解释,这些连接允许网络访问以前的时间序列值的整个历史。
可以将 RNN 看成同一个网络的多个副本,每个副本会传递消息给后续副本。由于自身属性,RNN 与序列和列表密切相关。在过去的几年中,将 RNN 应用于时间序列预测问题上已经取得了惊人的成果。
其中具有象征意义的是 LSTMs,这是一种非常特殊的 RNN,在许多任务上,它比标准 RNN 的表现要好得多。
GRU 架构也可以作为解决当前问题的方法,它们与 LSTMs 相似,结构更简。
作者的方法
基于 WaveNet CNN 网络并做了一些额外的扩展和修改。
近年来,深度学习技术的发展促使研究人员探索出各种时间序列预测方法,其中就有 WaveNet。WaveNet 是一个生成模型,这意味着模型可以针对一些条件输入生成实值数据(real-valued data)序列。
该架构背后的核心思想是空洞因果卷积(dilated causal convolutions)。由于没有循环连接和跳跃步骤,空洞卷积训练起来比 RNN 要快。
目前,因果卷积存在的问题之一是:为了增大感受野,需要用到多层卷积或者或很多大滤波器。
空洞卷积不存在这些问题,它使用上采样滤波器代替特征映射(feature maps)。换句话说,空洞卷积允许只增加核的视野在层间维持特征映射的大小,另外,可以用更少的参数捕获输入的全局视图。
为了能够产生 16 天的预测值,作者对模型进行了修改。因为训练使用的是下一步预测值,错误会持续累积。为了解决这个问题,他们使用 sequence to sequence 方法,编码器和解码器不会共享参数。解码器将会在产生长序列时处理累积的噪声。这里还用了亚当优化器更新网络权重。数据是通过小批次产生的,随机采样 128 个序列。
由于整个数据集大约包含 17 万序列 x 365 天,所以在每次训练迭代中都能向模型输入不同的数据。考虑到这一点,该模型能很好地处理过拟合问题。
在训练过程中,学习率衰减系数设置为 0.0005。作者将过去 16 天的训练数据做成一个集合,并将其用于验证。销售量的变化和促销信息可以用来生成的季度和年度模型。
在最后若干个上千或上万的的小批次中,模型会稍微出现过拟合,所以结果会有一点波动。
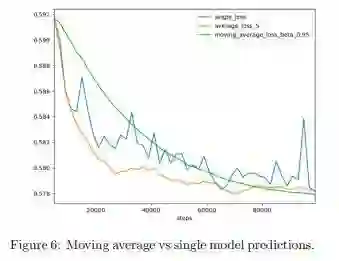
为了解决过拟合问题,平滑短期波动,着重于长期的动态性和周期性趋势,作者用到移动平均法(Moving average)。在 5000 次小批量迭代之后,模型开始预测,之后每过 2000 次迭代产生预测。在特定的迭代之后,如下图所示,5 个模型的平均性能优于单个模型。为了将模型准确性进一步提高,最终,作者使用指数移动平均法(exponential moving average),利用局部交叉验证(local cross-validation)计算出平滑因子(smooth factor)。
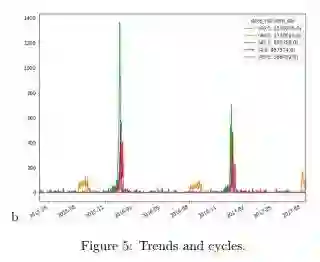
该模型有很好的捕获时间序列数据规律的能力,因此很多特性都没有被使用。其中一些是单位产品销售额和促销信息。
总结
企业面临一个明显的问题——市场是不可预测的。任何销售预测,无论你的分析条件多么严谨,都可能是完全错误的。如果市场状况保持相对不变,一种可靠的预测方法就是使用历史数据。作者的经验表明,卷积神经网络非常善于处理历史数据,捕捉季节性的趋势、周期和无规律的趋势,如下图所示。

他们描述了一种使用 CNN WaveNet 的方法,这是一个 sequence to sequence 架构,在销售预测方面,它是解决时间序列预测问题的有效方法(如下图)。
在未来,需要对层数更多的 CNN 进行更深入的研究,以完成更复杂的任务。为了训练更深的网络,需要大量的数据。在未来,对不同类型和领域的数据进行分析可能是另一个有趣的方向。此外,将不同技术融合起来也能获得相当的准确性。
回复:思维导图 获得Python学习必备思维导图电子版
回复:量化交易 获得量化投资编程课程与资料
回复:AI实验 获得20+开源小实验,真枪实战体验AI之趣
回复:深度学习笔记 获得深度学习完整信息图下载地址
回复:题库 获得人工智能面试题库,帮你顺利拿到offer!







