邓侃解读:深度学习病历分析前沿进展
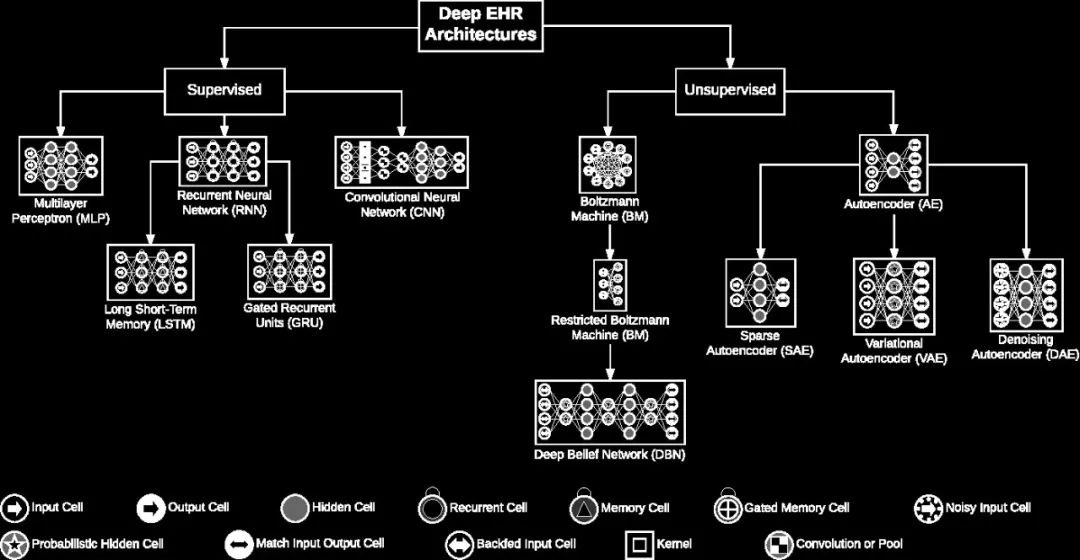
最常见的用于电子病历(EHR)分析的深度学习架构
【2018 新智元 AI 技术峰会倒计时 16 天】
3月29日,将于北京举办的 2018 年中国 AI 开年盛典——2018 新智元 AI 技术峰会,我们邀请到了德国总理默克尔的科学顾问、诺贝尔奖唯一计算机领域评委、工业 4.0 教父、世界顶级自然语言处理专家 Wolfgang Wahlste 教授。Wahlster 教授将亲临 329 峰会现场,分享欧洲对人工智能科技发展和 AI 产业化的思考。与诺奖评委面对面,点击文末阅读原文,马上参会!
抢票链接:
http://www.huodongxing.com/event/8426451122400
新智元专栏
作者:邓侃
编辑:闻菲
【新智元导读】邓侃博士又一力作,看深度学习如何让电子病历分析取得突破:Word2Vec、AutoEncoder让文字转换为张量,有助于更精准的预测;医学知识图谱,让我们能够清晰、量化地定义疾病表型;将图像也编码成张量,构建统一的患者画像,完整表达病情描述,实现临床导航和发病预测……曾经是冷门中的冷门,正在迎来一个又一个的进展。

2018年1月,谷歌头号技术大神 Jeff Dean,携手谷歌大脑项目组 30 余名研究人员,联袂发表了一篇论文,题为 “Scalable and accurate deep learning for electronichealth records”。
把深度学习技术应用于病历数据分析,原先是深度学习这个热门领域中的冷门。谷歌大脑这篇论文,把冷门引爆成了热门。
其实,把深度学习技术应用于病历数据分析,并非只有谷歌大脑在做。2018年2月,佛罗里达大学的几位学者,梳理了这个领域的前沿进展,在 Arxiv 上发表了一篇综述,题为 “Deep EHR: A Survey of Recent Advances in Deep LearningTechniques for Electronic Health Record (EHR) Analysis”。
纵览性的论文,总是值得读读。了解同行,促进自己。
病历数据是一条时间序列,记录着收集病情、诊断、治疗的过程。
病历数据也是一条空间路径。不妨把症状、体征、化验和检查指标、疾病、药品、手术等等,都视为离散的点。诊断和治疗的过程,是把这些离散的点,串连在一起,成为一条路径。
不论是用时间序列,还是空间路径,给病历数据建模,验证模型是否正确的办法之一,是验证模型的预测是否精准。譬如输入病情描述,预测罹患什么疾病。
学者们遇到的第一个问题是,如何表达病情描述?一个办法是直接用词汇,例如 “胃痛”、“腹泻”、“白细胞计数超标” 。也可以换一个办法,先做编码(encoding),把词汇转换成张量,然后把张量作为模型的输入。
研究发现,先做编码预处理,会使预测精度大大提高。为什么会这样?
想一想地图,标定位置的办法有两个,一个是用名称,譬如 “清华大学正门” ,另一个是用坐标(lat,lon)。很显然,用坐标数值来标定位置,更有利于规划导航路线。
原因是,坐标数值更容易表达各个位置之间的空间距离。而名称词汇却无法做到相同效果,单从名称词汇来看,谁知道 “清华大学正门” 与 “五道口” 的距离有多远?
如何把医学词汇转换成数值张量?老套路,word2vec。外加一些改进,譬如 autoencoder。
数值张量有多神奇?“胃痛” 与 “腹泻”,无一字相同,但是两个张量,距离相近。
编码,把文字词汇转换为数值张量,不仅能够提高疾病预测的精度,而且有利于病历结构化。
“患者无诱因出现咳嗽,持续三日,夜间加剧,浓痰”,咳嗽是主词,其余是属性。用传统方法提炼主词与属性,非常吃力。
把文字词汇转换成数值张量,相当于把这段话,投射到医学知识图谱上去,谁是主词,谁是属性,一清二楚。
知识图谱,无非是点和边的关系。用数值张量而不是用文字词汇,来表达图谱中的点,是共识。更大的挑战,是如何表达图谱中的边。
不存在单一症状与单一疾病之间的静态关系。临床实践表明,多个症状多个化验和检查指标,组合在一起,才能正确诊断罹患的是什么疾病。而且病情组合与疾病之间的关系,往往是非线性的,不能用一个静态常数来表达。
也就是说,医学知识图谱与电子地图相比,点相似,而边不同。
一个解决办法是把小点聚合成大点,譬如把与某个疾病相关的,多个症状体征和多个化验检查指标的组合,聚合在一起,形成一个超点(hypernode),然后把这个超点与这个疾病关联在一起。
病情组合的超点,与疾病之间的关联,不再是复杂的非线性关系,而是简单的常数关系。病情组合的超点与疾病,是一对一对等关系。一对一对等关系意味着什么?病情组合的超点变成疾病表型(phenotyping)。
疾病表型的新方法,这事儿意义重大。
医学教科书对各种疾病的表型定义,往往界定不清。同样一个病情组合,可能符合多种疾病的表型。为什么医学教科书不把多种相似疾病之间的甄别边界,描述得更清晰、更量化?因为文字词汇很难把非线性的边界,表达得很准确。
教科书的描述不清晰,医生们如何甄别相似疾病呢?靠自己在实践中摸索。医生正式上岗前,都要有很长的实习期。一代又一代医生,以一代又一代患者的生命为代价,自行总结疾病的甄别界定,而且这个经验往往无法分享传承。
如果医学知识图谱的张量超点,能够精确地界定疾病表型,功德无量。
不仅可以把文字词汇,编码成数值张量,而且也可以把医学影像的像素,也编码成数值张量。
这样不仅可以智能地自动地读片,撰写检查报告。而且,更大的意义在于,把文字与图像编码成统一的数值张量,用一个张量,完整地表达患者的病情描述。
完整的病情描述,大大便利了疾病的诊断,指导下一步需要做的化验和检查,推荐合理的用药处方,为基层医生提供智能的临床导航,大大提高基层医生的临床水平。
如果把患者历次病历,汇总起来,编码成更大的张量,这个更大的张量,实际上等同于患者的健康画像。精准的健康画像,能够预测未来几年,该患者罹患各种疾病的概率。
发病预测的意义,不再局限于临床医学,而且涉及到医疗保险,跨界到了经济学领域。
深度学习模型的本质,是多层隐节点,通过非线性函数相连。输入病情描述数据组合,输出疾病诊断。但是光有结果,没有解释,很难赢得医生和患者的信任。
如何解释深度学习模型的内部推理过程?一个办法是反向追溯。
输入病情描述数据组合,深度学习模型输出疾病诊断。从输出的诊断,反向追溯。确定在最后一层隐节点中,哪些隐节点起了关键作用。然后追溯到倒数第二层隐节点,倒数第三层……渐次反向追溯到输入,查看输入的病情描述组合中,哪些病情描述,对诊断起到决定性作用。
反向追溯,不仅仅可以用诊断解释,也可以用于确定医学知识图谱中的超点的组合。譬如说,通过反向追溯,确定某个疾病与哪些病情描述有关。把这些病情描述,组合起来,构建成医学知识图谱中的超点(hypernode)。
同时,不断变换病情描述的超点中,各个小点的取值,估算各个小点的取值分布,确定什么样的取值分布,会导致疾病的发生,从而界定疾病的表型(phenotyping)。
同理,不断变换患者画像中,各个小点的取值,估算各个小点的取值分布,确定什么样的取值分布,会增加未来发病的概率,从而把不同的患者,聚类成相似人群,方便医保精算。
病历数据处理,有四大难点:1. 多模态,2. 数据缺失,3. 时间跨度不一致,4. 脱敏。
多模态的问题,已经基本解决。把文字、音频、像素,全部编码成统一的数值张量。换句话说,数值张量是超越语言音频图像的数学语言,可以表述各种模态的语义。
数据缺失的解决办法,是通过其他相关数据,猜测缺失数据的取值。如何知道哪些数据之间有关联?办法是,预先构建医学知识图谱。
心电图数据的时间跨度,以秒计;脉搏血压的时间跨度,以小时计;查房记录,以天计……不同数据的时间跨度不一致,如何把它们对齐?一个思路是卷积,分层次整合细粒度的数据。
HIPAA 法案规定,病历中 18 项数据涉及患者隐私,譬如姓名和住址。脱敏的问题,等同于在病历的各个段落中,识别这 18 项数据。数值张量的编码,让脱敏问题变得简单。只需要用 attention,在病历的各个段落,找到与患者姓名和住址相近的张量即可。
一句话的总结:深度学习技术,让病历分析取得突破性进展。
相关论文

地址:https://arxiv.org/abs/1706.03446
【2018 新智元 AI 技术峰会倒计时 16 天】
点击阅读原文查看嘉宾与日程
峰会门票火热抢购,抢票链接:
http://www.huodongxing.com/event/8426451122400
【扫一扫或点击阅读原文抢购大会门票】





