NAVER提出字符级别的文本检测网络:CRAFT
点击上方“CVer”,选择加"星标"或“置顶”
重磅干货,第一时间送达

作者:柏林Designer
https://zhuanlan.zhihu.com/p/64811950
本文已授权,未经允许,不得二次转载
Character Region Awareness for Text Detection
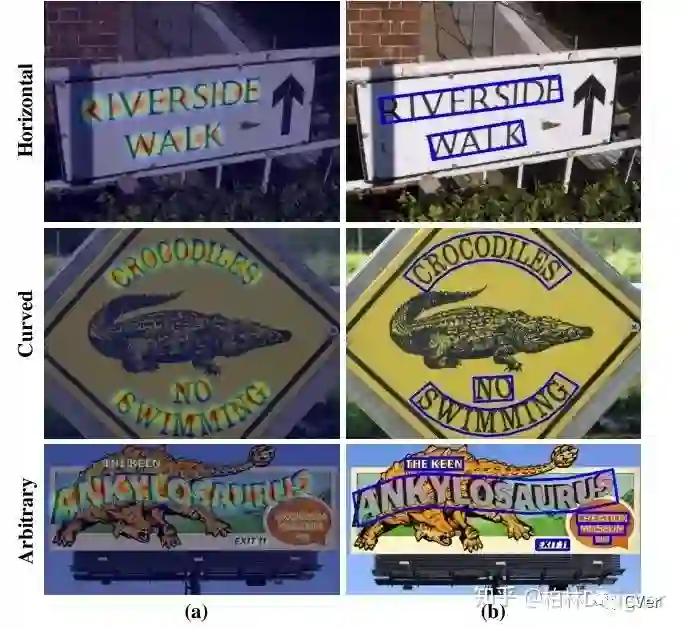
KeyWords Plus: CVPR2019 Curved Text

paper :https://arxiv.org/abs/1904.01941
NAVER:line的母公司,韩国的最大的互联网公司,字符级别的文字检测,采用了CAM热力图的操作去检测每一个字符
Introduction
字符级别的文本检测网络,用的是分水岭算法生成label,采用heatmaps去得到激活值最大的目标区域,有点attention的感觉。
1、论文创新点
1.提出了一篇字符级别的检测算法
2.预测得到 :1.The character region score 2. Affinity score. The region score is used to localize individual characters in the image, and the affinity score is used to group each character into a single instance.
3.Propose a weakly- supervised learning framework that estimates character- level ground truths in existing real word-level datasets.
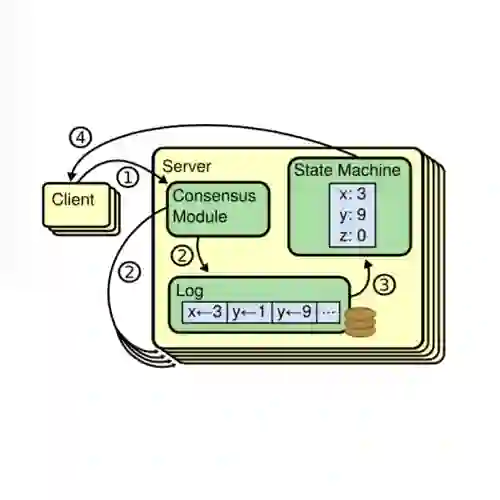
2、算法主体
改论文主要预测每个字符区域和字符之间的一个紧密程度预测,因为没有字符级别的label,所以模型训练在一个弱监督的方式下。网络的backbone采用VGG16,之后接上采样最终输出两个通道:the region score and the affinity score
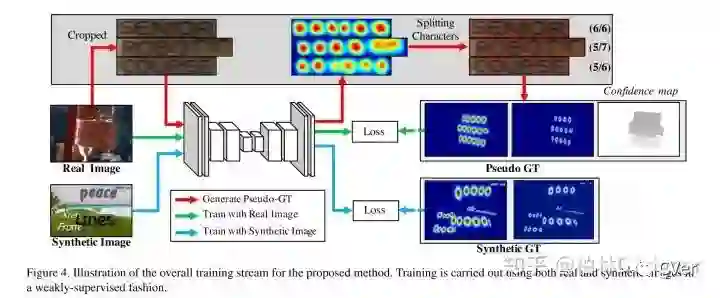
训练在一个弱监督学习的方式下,有人造合成的数据集具有字符级别的label,real image没有字符级别的标注时,自己检测合成产生label再进行训练。如上图所示,对真实场景中的数据集和人造合成的数据集有不同的训练方式。
3、label generation

分别产生Region Score GT和Affinity Score GT
the following steps to approximate and generate the ground truth for both the region score and the affinity score:
1) prepare a2-dimensional isotropic Gaussian map;
2) compute perspective transformbetween the Gaussian map region and each character box;
3) warp Gaussian mapto the box area.
使用小感受野也能预测大文本和长文本,只需要关注字符级别的内容而不需要关注整个文本实例。
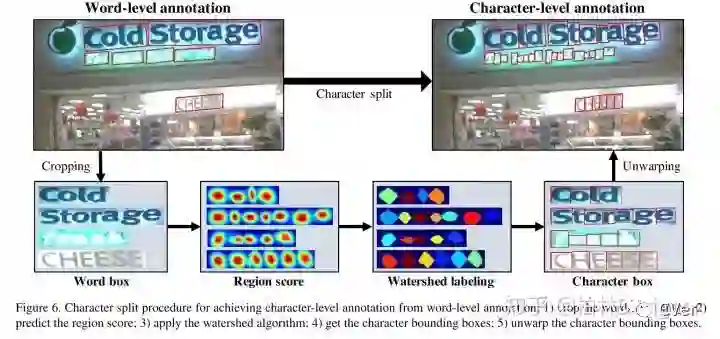
三步产生字符级别的label:
1、抠出文本级别的内容
2、预测region score区域
3、运用分水岭算法
4、得到字符基本的文字框
5、贴上文字框
为了防止在弱监督方式下产生的错误label带偏网络,该论文提出了一个评价方式(虽然我没有咋看明白),大概就是计算一个

4、Post-processing
正常文本后处理分为以下几步:
1、首先对0-1之间的概率图进行取阈值计算
2、使用Connected Component Labeling(CCL) 进行区域连接
3、最后使用opencv的MinAreaRect去框出最小的四边形区域

不规则文本检测后处理分为以下几步(如上图所示):
1、先找到扫描方向的局部最大值(blue line)
2、连接所有the local maxima上的中心点叫做中心线
3、然后将the local maxima lines旋转至于中心线垂直
4、the local maxima lines上的端点是文本控制点的候选点,为了能更好的覆盖文本,将文本最外端的两个控制点分别向外移动the local maxima lines的半径长度最为最终的控制点。
5、Experiment Results
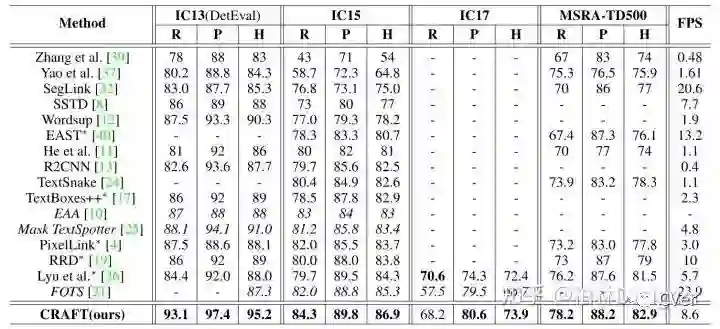

6、Conclusion and Future work
个人观点:不太受感受野的限制,只关注单个文字,对于长文本和不规则文本不必特意去设置相应大小的卷积提升感受野。
反馈与建议
邮箱:<weij ia_wu@yeah.net>
CVer-文本检测&识别群
扫码添加CVer助手,可申请加入CVer-文本检测&识别群。一定要备注:文本检测+地点+学校/公司+昵称(如文本检测+上海+上交+卡卡)

▲长按加群
这么硬的论文分享,麻烦给我一个在在看

▲长按关注我们
麻烦给我一个在看!