【泡泡图灵智库】LS-VO:学习稠密光流子空间用于鲁棒的视觉里程计估计(ICRA)
泡泡图灵智库,带你精读机器人顶级会议文章
标题:LS-VO: Learning Dense Optical Subspace for Robust Visual Odometry Estimation
作者:Gabriele Costante†,1 and Thomas A. Ciarfuglia†,1
来源:ICRA 2018
编译:刘小亮
审核:黄文超
欢迎个人转发朋友圈;其他机构或自媒体如需转载,后台留言申请授权

摘要

大家好,今天为大家带来的文章是—— LS-VO:学习稠密的光流子空间用于鲁棒的视觉里程计估计,该文章发表于ICRA 2018。
这个工作提出一种新的深度神经网络架构用于解决相机的自运动估计问题,运动估计网络通常从图像序列开始学习类似于光流(OF)场的特征。该OF可以通过较低维度的潜在空间来描述。先前的研究工作已经展示了如何找到这个空间的线性近似。我们提出了使用自编码器网络来发现OF流形的非线性表示。此外,我们提出同时学习潜在的空间和运动估计任务,以便学习的OF特征成为OF输入的更鲁棒描述。我们称这种新架构为潜在的空间视觉里程计(LS-VO)。实验表明,LS-VO相对于基准的性能显著提高,而估计网络的参数数量仅略有增加。
主要贡献
1、提出了一种新的端到端架构,同时学习OF潜在空间和相机自运动估计。 我们称这种架构为潜在空间-VO,Latent Space-VO(LS-VO)。
2、通过实验证明了所提出的架构的在变化中的强度。包括外观变化,模糊和大的相机速度变化。
3 、通过实验证明了所提出的方法对其他端到端架构的适应性。而由于参数增加,并没有增加过拟合的可能性。
算法流程
一、本文整体方法架构:
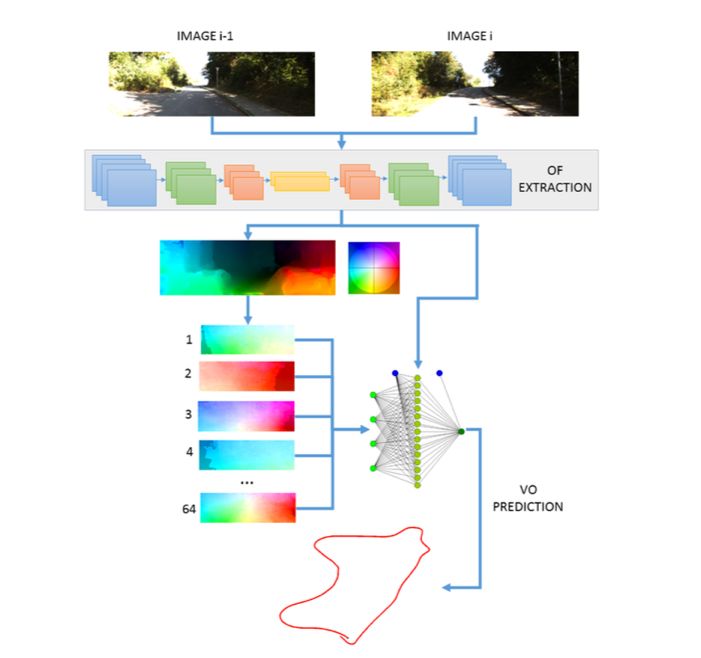
图1本文方法概述:本文提出了一种网络架构,同时学习光流场的潜在空间表示并估计运动。 联合学习使得估计对输入域变化更加稳健。 潜在表示是估计网络的输入,同时也是较低级别的特征。
二、LS-VO整体网络的架构
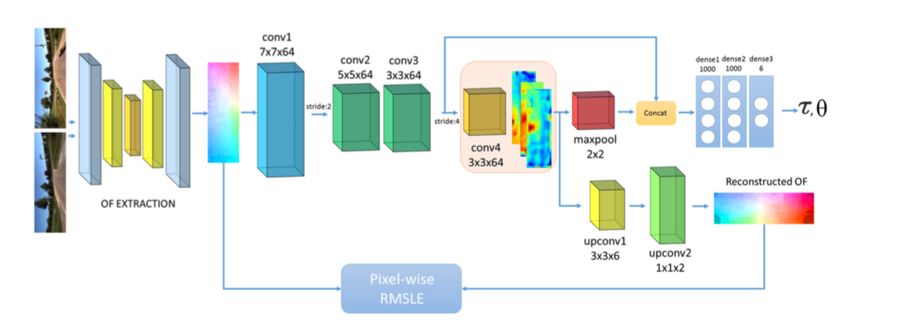
图2 LS-VO网络架构。 共享部分由Flownet OF提取部分组成,然后是三个开始特征提取的卷积层组成。 编码器的最后一层conv4不与Estimator网络共享。 从conv4中产生潜在变量。 解码器网络获取这些变量并重建输入,而Estimator将它们连接到conv3输出。 然后三个完全连接层产生运动估计。
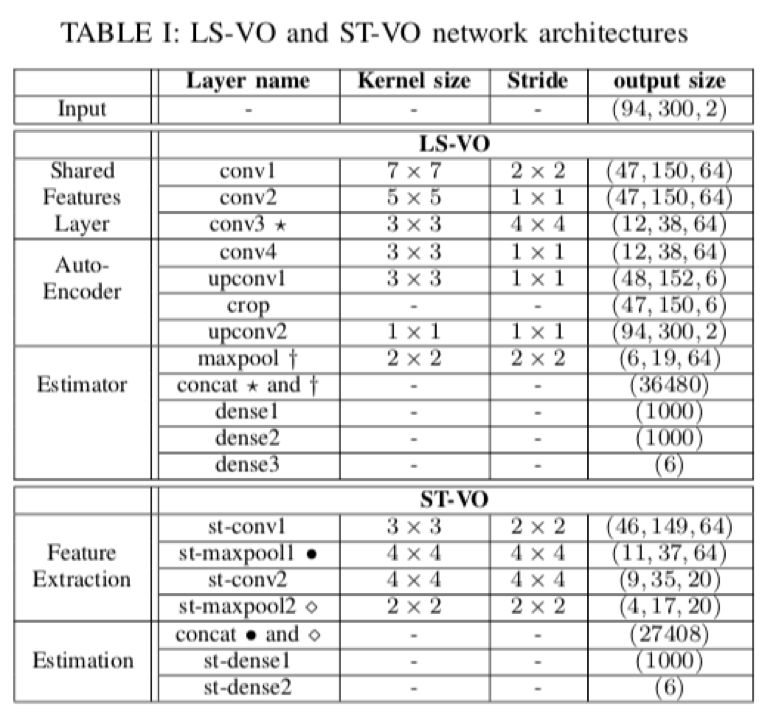
表一 LS-VO和ST-VO网络架构(ST-VO:单任务VO,Single Task)
主要结果
数据集 :KITTI 和 Malaga 2013 ,训练使用 Nvidia Titan Xp
一、在KITTI数据集上面的比较,包括几何方法VISO-M,和ORBSLAM2-M。两个数据集的角速率估计上面基本LS-VO性能都比较好,而去基于学习的方法不会跟踪丢失。特别对于相对模糊的数据序列d2进行分析,突出本文对于模糊图像的鲁棒性。

表二 关于KITTI实验的所有方法的表现总结。 几何方法在标准速率下对两个数据集的角速率估计(以deg / m为单位)表现更好,但通常在其他数据集上失败(失去跟踪)。 在所有情况下,学习方法的行为都是一致的:即使一般误差增加,即使在测试的最差条件下,它们也永远不会失去跟踪,并且轨迹总是有意义的。
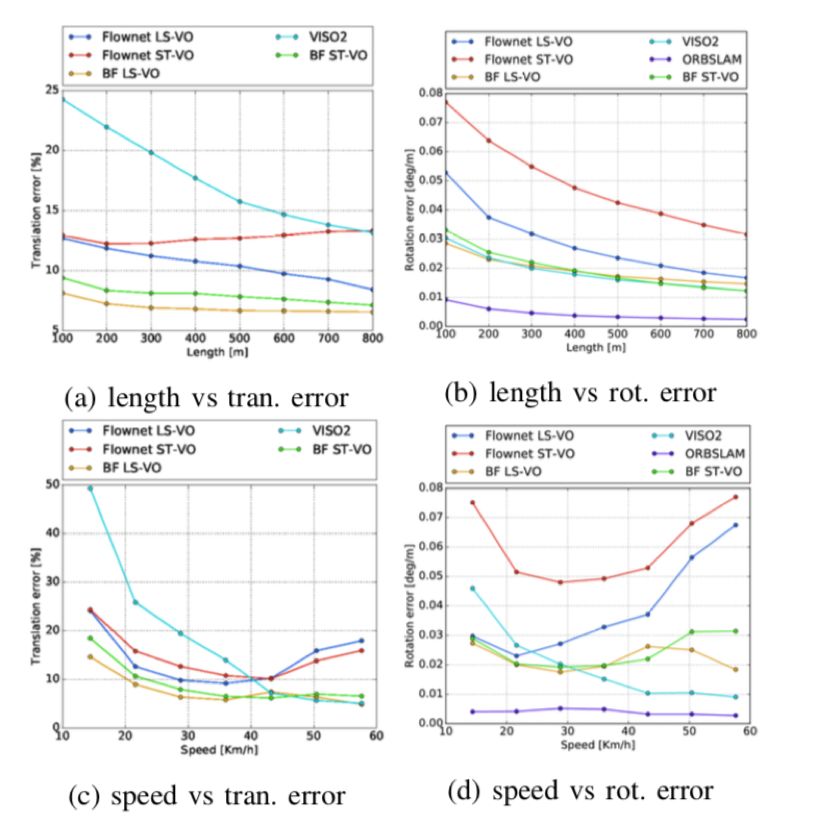
图3 KITTI数据集上所有方法之间的比较,没有序列子采样。 很明显,LS-VO网络的性能优于ST等,而在BF OF输入的情况下,它几乎总是更好。 几何方法在角速率方面优于学习方法。因为ORBSLAM2-M在(a)和(b)中误差大于其他方法,为了轴清晰度,所以未示出。
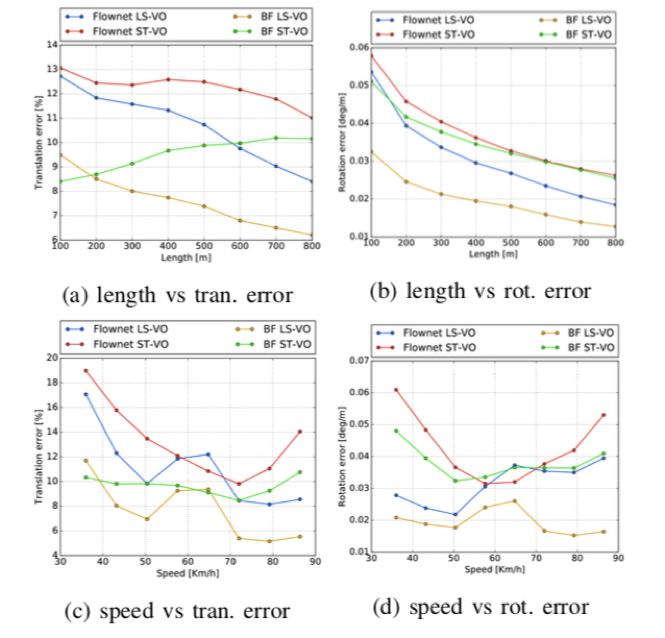
图4 KITTI d2数据集上四种网络的比较。 同样,LS-VO架构优于其他架构,速度约为60Km / h。
图5 KITTI d2轨迹:对所有架构的子采样序列计算的轨迹(d2 - 5Hz)。
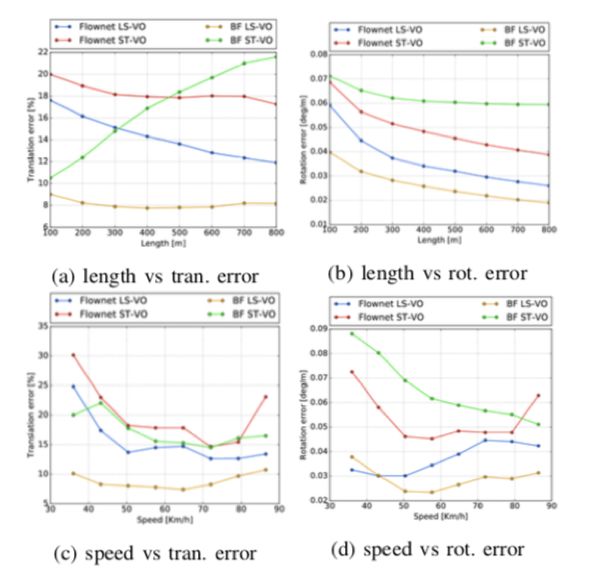
图6 在模糊KITTI d2序列的四种架构的性能。 ST和LS-VO网络之间的性能差异很大。 出于轴刻度的原因,已省略VISO2-M。
二、同样本文在Malaga数据集上面做了对比实验,整体表现和KITTI上面相似。

表三 关于Malaga实验的所有方法的表现总结。和表二中情况一样。 在这组实验中,为简单起见,仅分析了端到端架构。
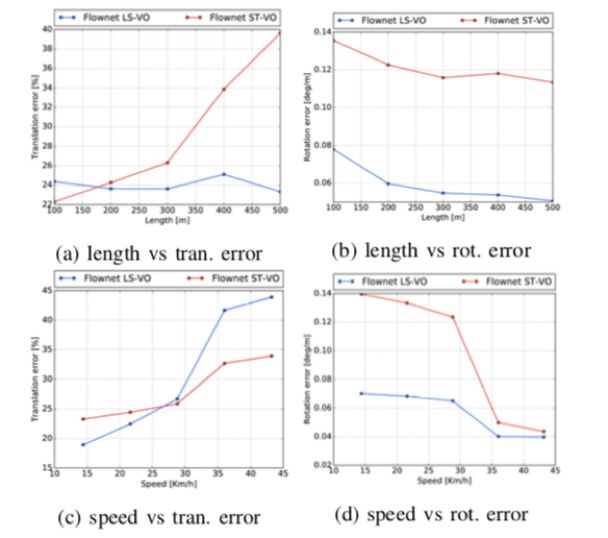
图7 在模糊的Malaga d2序列的端到端架构的性能。 如图6(c)所示,高速缺少样本使得LS-VO网络略微过度拟合这些样本,但在所有其他方面,其行为类似于图6。

Abstract
This work proposes a novel deep network architecture to solve the camera Ego-Motion estimation problem. A motion estimation network generally learns features similar to Optical Flow (OF) fields starting from sequences of images. This OF can be described by a lower dimensional latent space. Previous research has shown how to find linear approximations of this space. We propose to use an Auto-Encoder network to find a non-linear representation of the OF manifold. In addition, we propose to learn the latent space jointly with the estimation task, so that the learned OF features become a more robust description of the OF input. We call this novel architecture Latent Space Visual Odometry (LS-VO). The experiments show that LS-VO achieves a considerable increase in performances with respect to baselines, while the number of parameters of the estimation network only slightly increases.
如果你对本文感兴趣,想要下载完整文章进行阅读,可以关注【泡泡机器人SLAM】公众号。
点击阅读原文,即可获取本文下载链接。
欢迎来到泡泡论坛,这里有大牛为你解答关于SLAM的任何疑惑。
有想问的问题,或者想刷帖回答问题,泡泡论坛欢迎你!
泡泡网站:www.paopaorobot.org
泡泡论坛:http://paopaorobot.org/bbs/


泡泡机器人SLAM的原创内容均由泡泡机器人的成员花费大量心血制作而成,希望大家珍惜我们的劳动成果,转载请务必注明出自【泡泡机器人SLAM】微信公众号,否则侵权必究!同时,我们也欢迎各位转载到自己的朋友圈,让更多的人能进入到SLAM这个领域中,让我们共同为推进中国的SLAM事业而努力!
商业合作及转载请联系liufuqiang_robot@hotmail.com


