原来Transformer就是一种图神经网络,这个概念你清楚吗?
选自NTU Graph Deep Learning Lab
作者:Chaitanya Joshi
机器之心编译
参与:一鸣、杜伟、Jamin
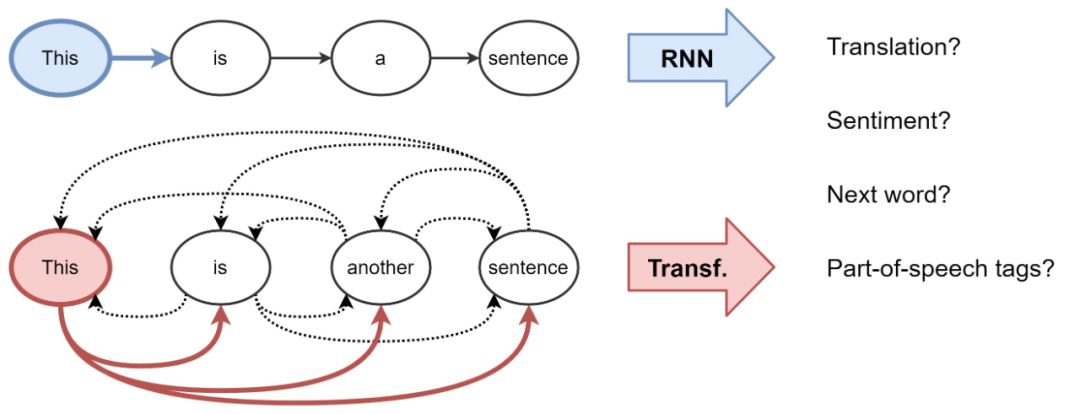
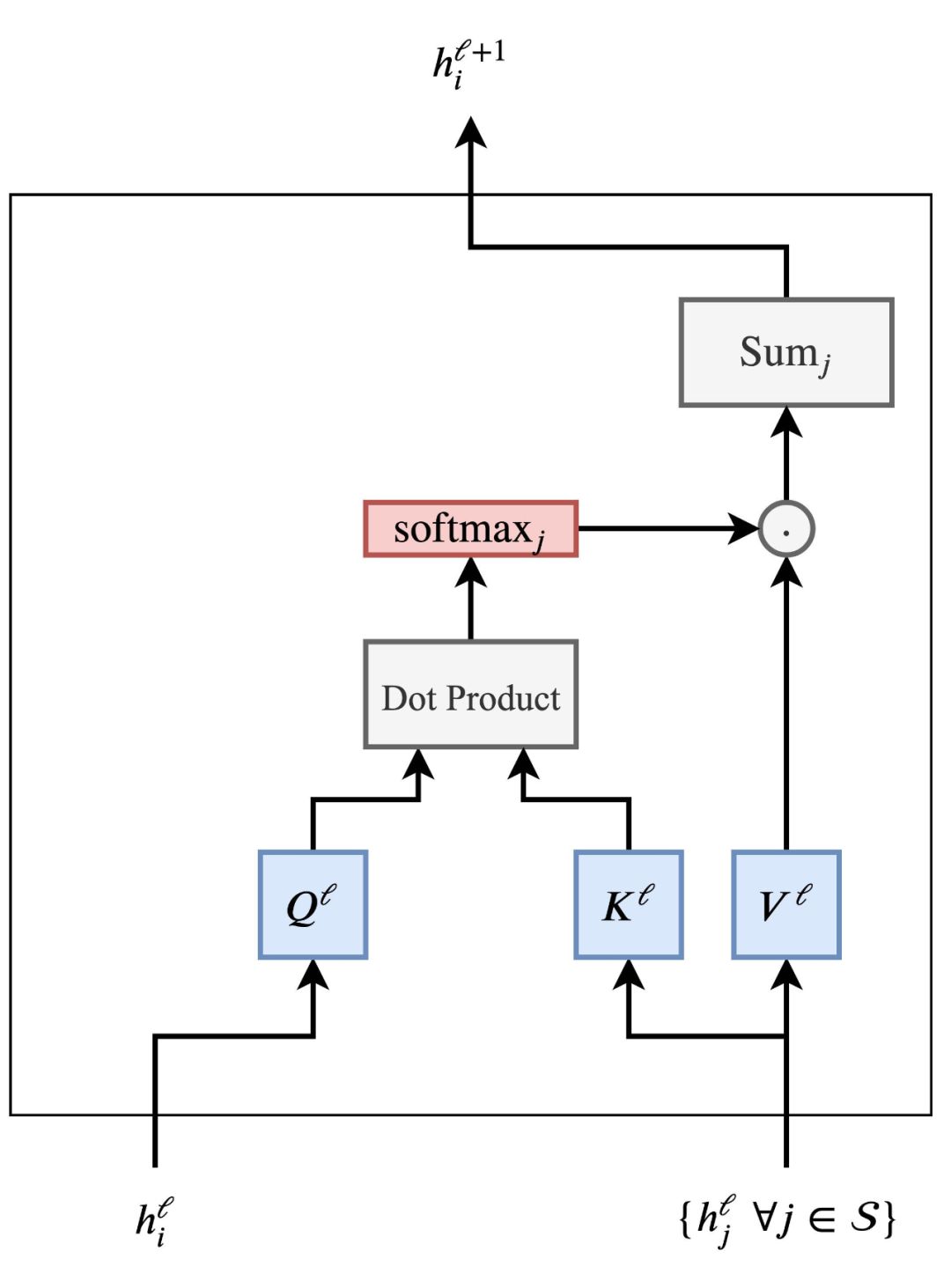
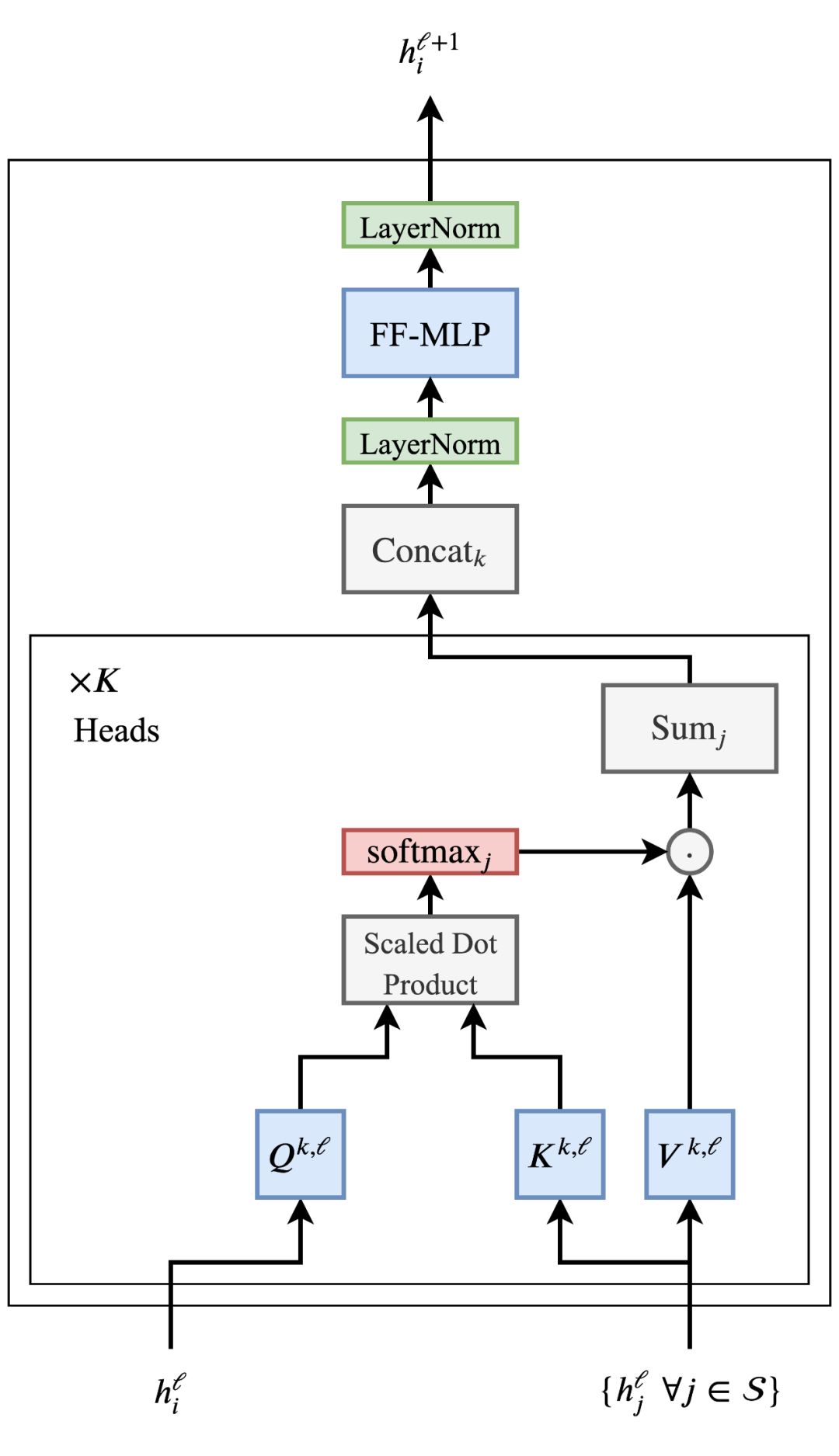
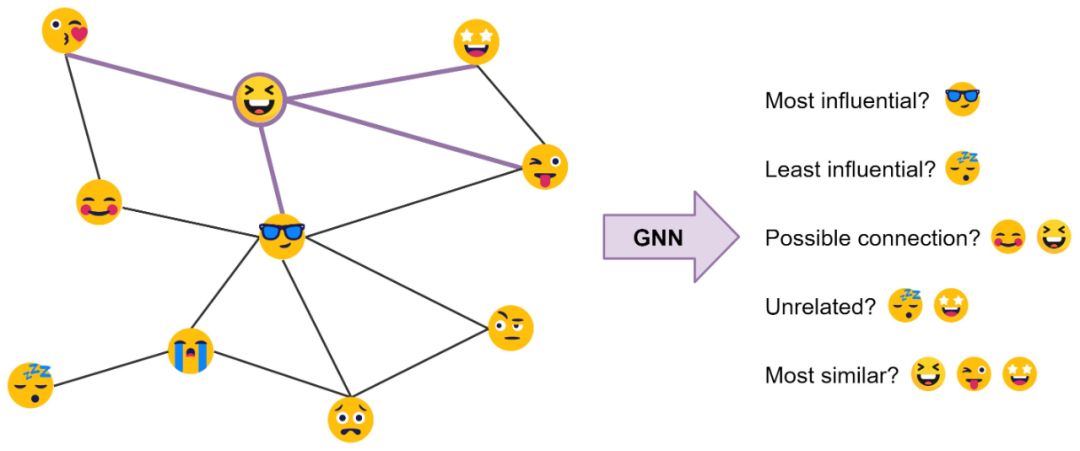
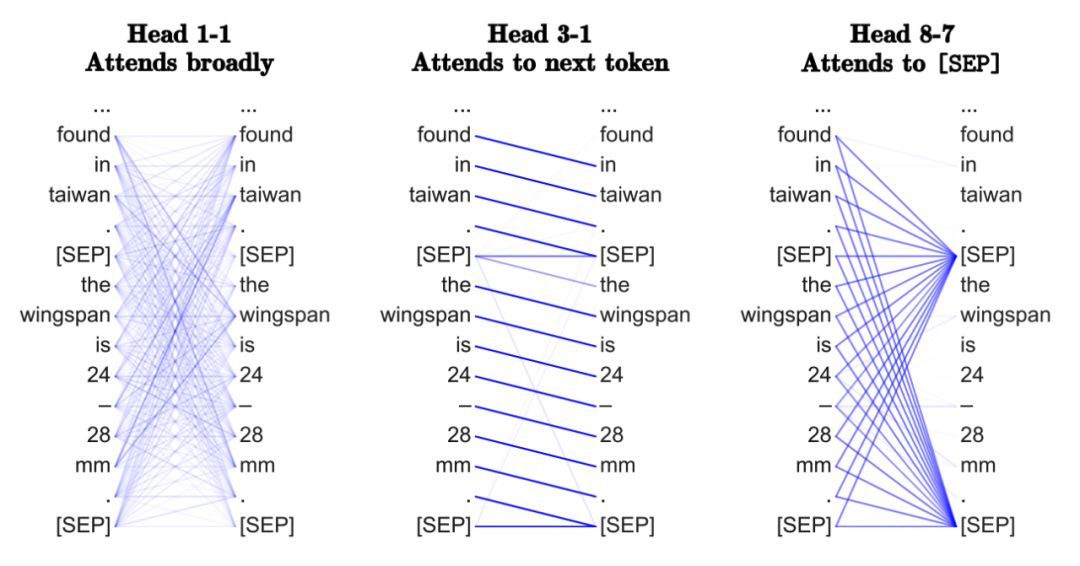
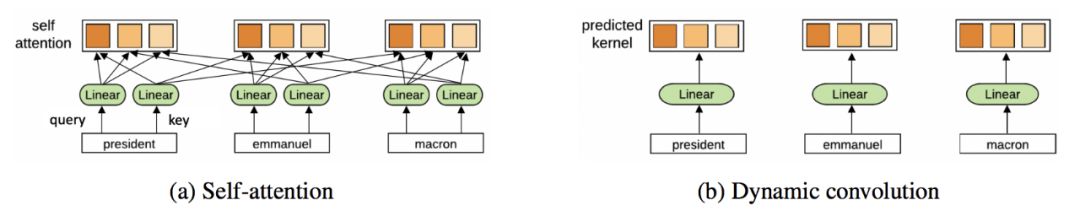
Transformer和GNN有什么关系?一开始可能并不明显。但是通过这篇文章,你会从GNN的角度看待Transformer的架构,对于原理有更清楚的认知。

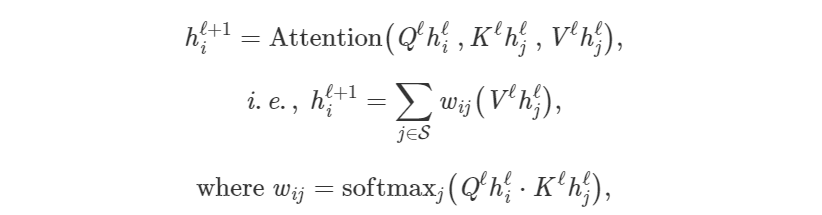
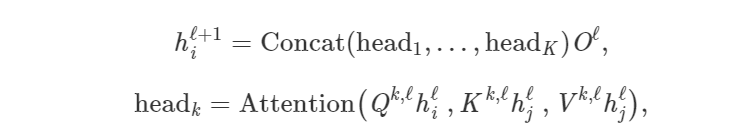
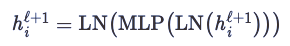
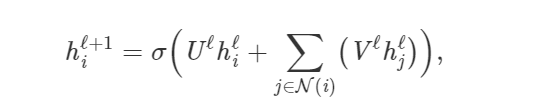
登录查看更多
相关内容

Transformer是谷歌发表的论文《Attention Is All You Need》提出一种完全基于Attention的翻译架构



相关VIP内容
相关资讯
相关论文