ECCV 2018 | 腾讯AI lab & 复旦大学合作提出无监督高分辨率的图像到图像转换方法SCAN
机器之心发布
作者:Minjun Li,Haozhi Huang,Lin Ma, Wei Liu, Tong Zhang, Yu-Gang Jiang
在最近由腾讯 AI Lab 主导,与复旦大学合作完成的一篇论文中,作者们提出了一种新型堆叠循环一致性对抗网络(SCAN),它将单个转换过程分解为多阶段的转换,因此同时提升了图像转换质量与图像到图像转换的分辨率。
最近关于无监督的图像到图像转换研究取得了较为显著的进展,其主要思想是通过训练一对具有循环一致性损失(cycle-consistent loss)的生成对抗网络(Generative Adversarial Networks)。然而,当图像分辨率高或者两个图像域具有显著差异时(例如 Cityscapes 数据集中图像语义分割与城市景观照片之间的转换),这种无监督方法可能产生较差的结果。
在本论文中,通过把单个转换分解为多阶段转换,作者提出了堆叠循环一致性对抗网络(SCAN)。其通过学习低分辨率图像到图像的转换,然后基于低分辨率的转换学习更高分辨率的转换,这样做提高了图像转换质量并且使得学习高分辨率转换成为可能。此外,为了适当地利用来自前一阶段的学习到的信息,研究者设计了自适应融合块以学习当前阶段的输出和前一阶段的输出的动态整合。在多个基准数据集的实验表明,与以前的单阶段方法相比,本文提出的方法可以大大提高图像到图像转换的质量。
从最初的 pix2pix,到最近面向高分辨率的 pix2pixHD,有监督的图像到图像转换研究已经取得了很大进展。另一方面,以 CycleGAN、DiscoGAN、ContrastGAN 为代表的方法,重点研究了无监督的图像到图像的转换。
然而当图像分辨率高或者两个图像域具有显著差异时,这些无监督的方法仍然无法取得十分令人满意的结果。受近期多阶段改善网络的启发,本文提出了堆叠循环一致性对抗网络(SCAN),如图 1 所示。给定两个图像域的数据(没有一一对应的匹配),SCAN 通过从粗糙到精细的方式渐进式地学习了高分辨率的图像到图像的转换。由于没有一一对应的匹配图像对,整个学习过程是非监督的。
在 SCAN 中,一个复杂的图像到图像转换问题被分解为多个更简单的转换阶段。最开始低分辨率的阶段学习了大致的图像低频信息转换过程,后续高分辨率的阶段学习了如何逐步添加图像高频细节。
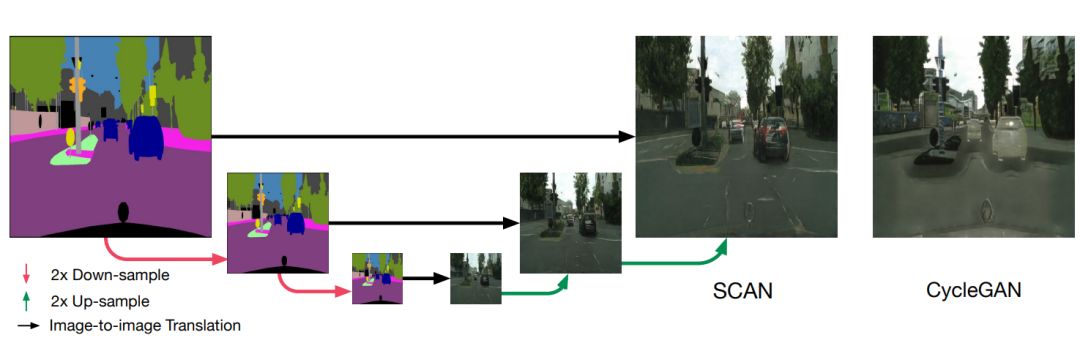
图 1 堆叠循环一致性对抗网络(SCAN)示意图
SCAN 具体的网络设计如图 2 所示。这里展示两阶段的网络设计。可以迭代式地对最后一阶段进行分解,得到由更多阶段组成的转换网络。对于任意的图像集合 X 与 Y,两个变换 G:X→Y 与 F:Y→X 完成两个集合之间的图像转换。通过多阶段图像转化模型把变换分解为 
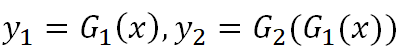
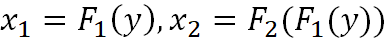
具体方法为:对于不同输入计算两个阶段输出的融合权重α,最后转化结果为两个阶段输出基于融合权重α的线性结合。两个阶段的学习都应用图像转化的非监督学习(3.2.3 节)使得学习过程不依赖任何图像标签对。具体来说,我们同时学习两个方向图像转化,并应用循环一致性约束,限制 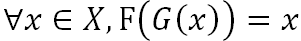
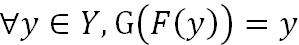
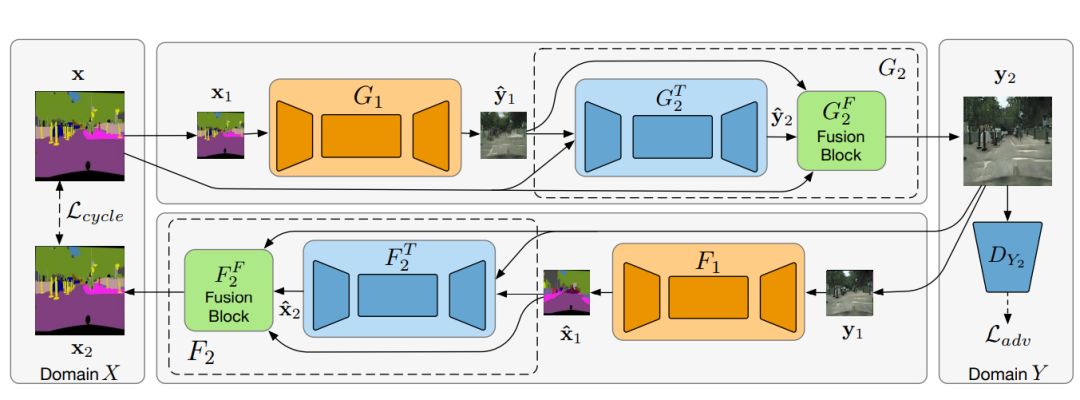
图 2 SCAN 的网络设计(以两阶段网络为例)
在标签图和真实图像互相转换的任务上,我们与 CycleGAN、ContrastGAN、pix2pix 等方法进行了对比。同时也对比了本文方法的一些组件和变种。表 1 展示了不同方法的数值结果。对于标签图转照片(Labels to Photo)任务,我们采用了 FCN scores 来进行比较。对于照片转标签图(Photo to Labels)任务,我们采用了 Segmentation scores 来比较。可以看到,本文方法的结果远超 CycleGAN 和 ContrastGAN 这两种无监督的方法,大大缩小了与有监督的方法 pix2pix 之间的差距。
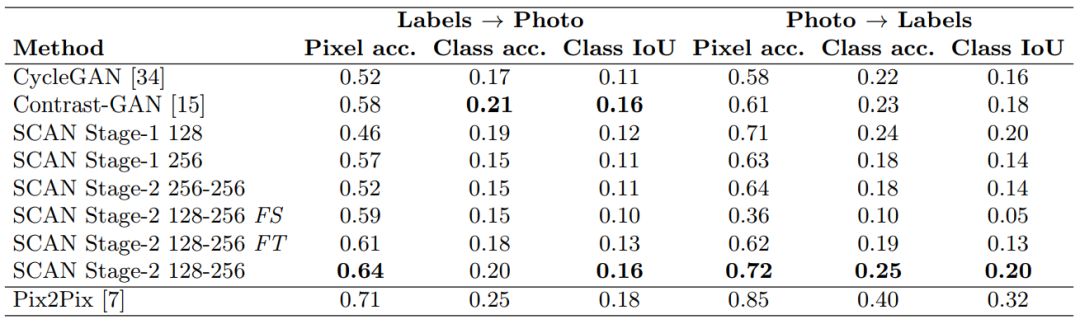
表 1 不同方法数值结果的比较
图 3 展示了在 512x512 分辨率下,标签图转换成照片的直观结果。可以看到,与 CycleGAN 相比,本文提出的 SCAN 能够生成更具真实感的照片。

图 3 标签图转照片的直观结果比较
此外,利用 SCAN 还可以更好地完成涉及物体形状改变的图像到图像转换,如真人头像到动漫头像的转换。图 4 展示了真人头像转动漫头像的直观结果,可以看到眼睛和嘴巴的大小和形状都发生了改变,不再是简单的逐像素变换。

图 4 真人头像转动漫头像的结果
本文为机器之心发布,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者 / 实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告 & 商务合作:bd@jiqizhixin.com


