找不到中文语音预训练模型?中文版Wav2vec 2.0和HuBERT来了

©作者 | 腾讯游戏知几AI团队,西工大ASLP组
来源 | 机器之心
近日,腾讯游戏知几 AI 团队与西工大 ASLP 组联合发布了基于 WenetSpeech 1 万小时数据训练的中文版 Wav2vec 2.0 和 HuBERT 模型。
Wav2vec 2.0 [1],HuBERT [2] 和 WavLM [3] 等语音预训练模型,通过在多达上万小时的无标注语音数据(如 Libri-light )上的自监督学习,显著提升了自动语音识别(Automatic Speech Recognition, ASR),语音合成(Text-to-speech, TTS)和语音转换(Voice Conversation,VC)等语音下游任务的性能。然而这些模型都没有公开的中文版本,不便于应用在中文语音研究场景。
WenetSpeech [4] 是由西工大音频、语音和语言处理研究组 (ASLP@NPU)、出门问问、希尔贝壳联合发布的 1 万多小时多领域语音数据集。为了弥补中文语音预训练模型的空缺,我们开源了基于 WenetSpeech 1 万小时数据训练的中文版 Wav2vec 2.0 和 HuBERT 模型。
为了验证预训练模型的性能,我们在 ASR 任务进行了验证。实验结果表明,在 100 小时有监督数据 ASR 任务上,预训练模型学到的语音表征相对于传统声学 FBank 特征有显著的性能提升,甚至仅用 100 小时有监督数据能够得到和 1000 小时有监督数据可比的结果。
模型链接:
https://github.com/TencentGameMate/chinese_speech_pretrain

模型介绍
1.1 Wav2vec 2.0模型
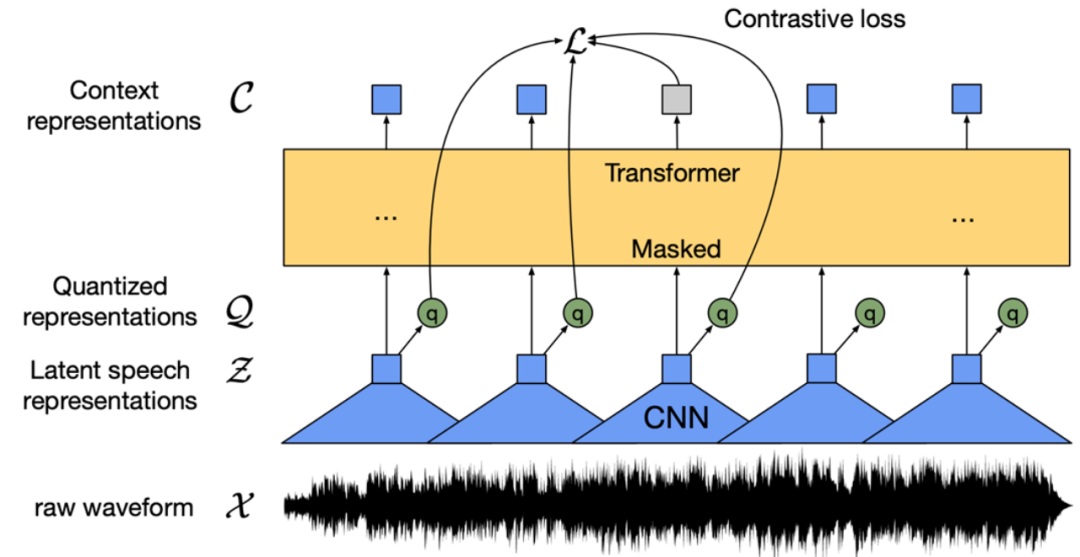
▲ 图1. Wav2vec 2.0 模型结构 (Baevski et al., 2020)
Wav2vec 2.0 [1] 是 Meta 在 2020 年发表的无监督语音预训练模型。它的核心思想是通过向量量化(Vector Quantization,VQ)构造自建监督训练目标,对输入做大量掩码后利用对比学习损失函数进行训练。
模型结构如上图 1,基于卷积网络(Convoluational Neural Network,CNN)的特征提取器将原始音频编码为帧特征序列,通过 VQ 模块把每帧特征转变为离散特征 Q,并作为自监督目标。同时,帧特征序列做掩码操作后进入 Transformer [5] 模型得到上下文表示 C。最后通过对比学习损失函数,拉近掩码位置的上下文表示与对应的离散特征 q 的距离,即正样本对。
原论文中,Wav2vec 2.0 BASE 模型采用 12 层的 Transformer 结构,用 1000 小时的 LibriSpeech 数据进行训练,LARGE 模型则采用 24 层 Transformer 结构,用 6 万小时的 Libri-light 数据训练。训练时间方面,BASE 模型使用 64 块 V100 显卡训练 1.6 天,LARGE 使用 128 块 V100 显卡训练 5 天。在下游 ASR 评测中,即使只用 10 分钟的有监督数据,系统仍可得到 4.8 的词错误率(Word Error Rate, WER)结果。
1.2 HuBERT模型
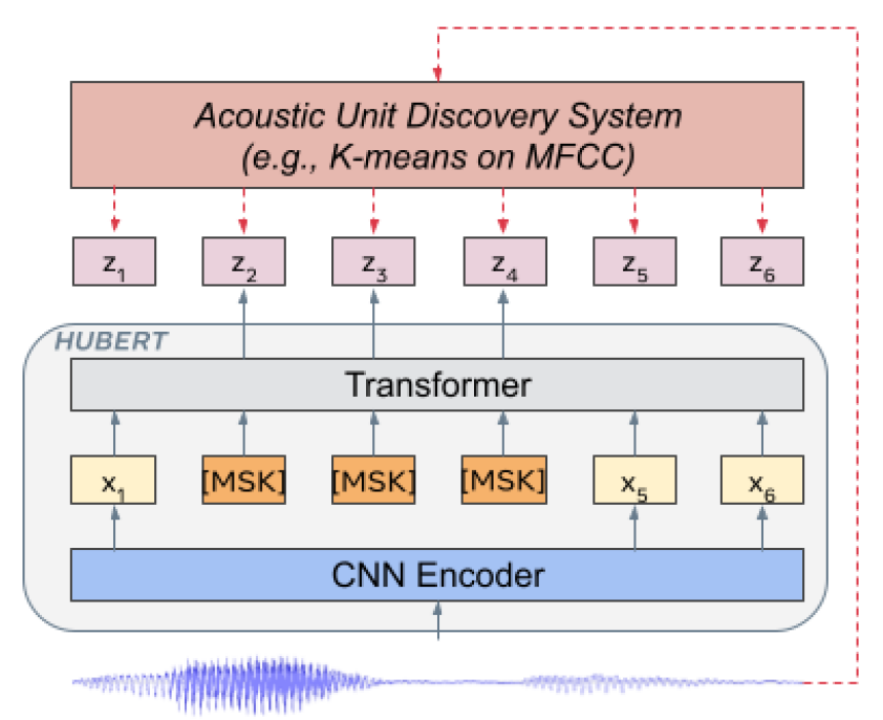
▲ 图2. HuBERT 模型结构 (Hsu et al., 2021)
HuBERT [2] 是 Meta 在 2021 年发表的模型,模型结构类似 Wav2vec 2.0,不同的是训练方法。Wav2vec 2.0 是在训练时将语音特征离散化作为自监督目标,而 HuBERT 则通过在 MFCC 特征或 HuBERT 特征上做 K-means 聚类,得到训练目标。
HuBERT 模型采用迭代训练的方式,BASE 模型第一次迭代在 MFCC 特征上做聚类,第二次迭代在第一次迭代得到的 HuBERT 模型的中间层特征上做聚类,LARGE 和 XLARGE 模型则用 BASE 模型的第二次迭代模型提取特征做聚类。从原始论文实验结果来看,HuBERT 模型效果要优于 Wav2vec 2.0,特别是下游任务有监督训练数据极少的情况,如 1 小时、10 分钟。

中文预训练模型
2.1 实验配置
我们使用 WenetSpeech [4] train_l 集的 1 万小时中文数据作为无监督预训练数据。数据主要来源于 YouTube 和 Podcast,覆盖了各种类型录制场景、背景噪声、说话方式等,其领域主要包括有声书、解说、纪录片、电视剧、访谈、新闻、朗读、演讲、综艺和其他等 10 大场景。我们基于 Fairseq 工具包 [6] 分别训练了 Wav2vec 2.0 和 HuBERT 模型,遵循 [1,2] 的模型配置,每个预训练模型模型包括 BASE 和 LARGE 两种大小。对于 BASE 模型,我们使用 8 张 A100 显卡,梯度累计为 8,模拟 64 张显卡进行训练。对于 LARGE 模型,我们使用 16 张 A100 显卡,梯度累计为 8,模拟 128 张显卡进行训练。
2.2 下游语音识别任务验证
为了验证预训练模型在下游 ASR 任务的效果,我们遵循 ESPnet [7,8,9] 工具包中的 Conformer [10] 模型实验配置,即将预训练模型作为特征提取器,对于输入语音提取预训练模型各隐层表征进行加权求和,得到的语音表征将替换传统 FBank 特征作为 Conformer ASR 模型的输入。
Aishell 数据集
我们使用 Aishell 178 小时训练集作为有监督数据进行训练,分别对比了使用 FBank 特征、Wav2vec 2.0 BASE/LARGE 模型特征和 HuBERT BASE/LARGE 模型特征的字错误率 (Character Error Rate, CER) 结果。同时,我们额外对比了使用 WenetSpeech train_l 集 1 万小时中文数据进行训练时,其在 Aishell 测试集上的效果。训练数据使用了变速(0.9、1.0、1.1 倍)和 SpecAugment 数据增广技术,解码方式为 beam search,使用了基于 Transformer 的语言模型进行 rescoring。

▲ 表1. 不同模型在 Aishell 测试集上的字错误率(CER%)结果
根据表 1 结果可以看到,通过结合上万小时无监督数据训练的预训练模型,下游 ASR 任务效果均有显著提升。尤其是使用 HuBERT LARGE 模型时,在 Test 集上得到约 30% 的 CER 相对提升,实现了目前在 178h 有监督训练数据下业界最好结果。
WenetSpeech 数据集
我们使用 WenetSpeech train_s 集 100 小时中文数据作为有监督数据进行训练,分别对比了使用 FBank 特征、Wav2vec 2.0 BASE/LARGE 模型特征和 HuBERT BASE/LARGE 模型特征的字错误率 (Character Error Rate, CER) 结果。同时,我们额外对比了使用 WenetSpeech train_m 集 1000 小时和 train_l 集 1 万小时中文数据 FBank 特征训练的模型结果。训练数据没有使用变速或 SpecAugment 数据增广技术,解码方式为 beam search,没有使用语言模型 rescoring。
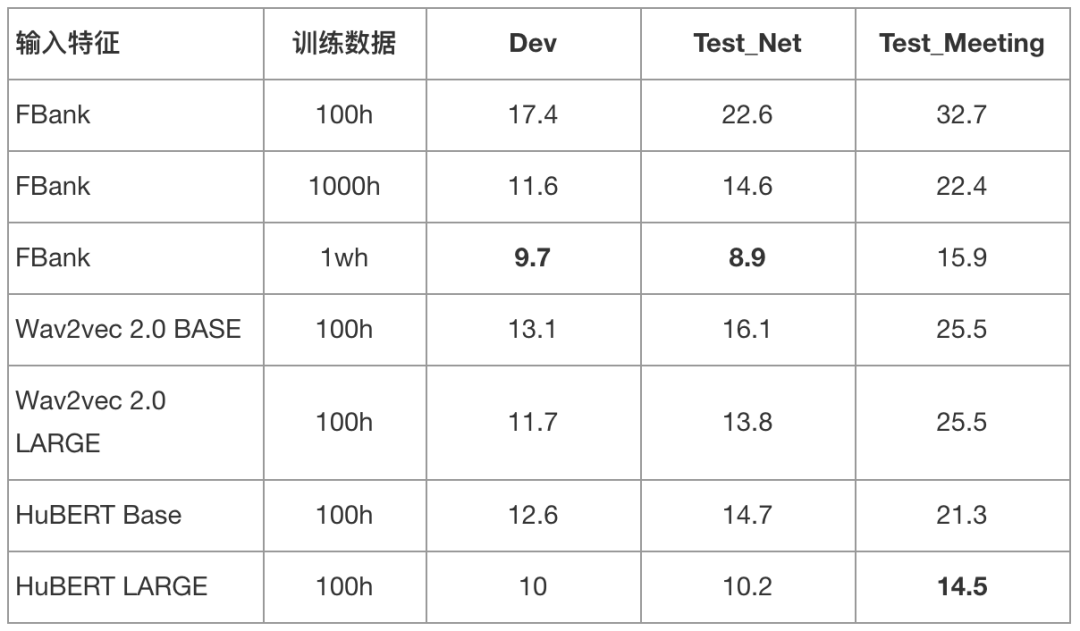
▲ 表2. 不同模型在WenetSpeech测试集上的字错误率(CER%)结果
根据表 2 结果可以看到,通过结合上万小时无监督数据训练的预训练模型,下游 ASR 结果得到了巨大提升。尤其当使用 HuBERT LARGE 作为语音表征提取器时,使用 100 小时有监督数据训练的 ASR 模型要比 1000 小时基于 FBank 特征训练的模型效果要好,甚至接近 1 万小时数据训练的模型。
更多语音下游任务实验结果请关注 GitHub 链接。欢迎大家使用我们提供的中文语音预训练模型开展研究工作,一起探索语音预训练模型在中文和相关众多场景下的应用。

参考文献
[1] Alexei Baevski, Henry Zhou, Abdelrahman Mohamed, and Michael Auli, “Wav2vec 2.0: A framework for self-supervised learning of speech representations,” in Proc. NeurIPS, 2020.
[2] Wei-Ning Hsu, Benjamin Bolte, Yao-Hung Hubert Tsai, Kushal Lakhotia, Ruslan Salakhutdinov, and Abdelrahman Mohamed, "HuBERT: Self-supervised speech representation learning by masked prediction of hidden units," IEEE/ACM Transactions of Audio, Speech, and Language Processing, vol. 29, pp. 3451-3460, 2021
[3] Sanyuan Chen, Chengyi Wang, Zhengyang Chen, Yu Wu, Shujie Liu, Zhuo Chen, Jinyu Li, Naoyuki Kanda, Takuya Yoshioka, Xiong Xiao, Jian Wu, Long Zhou, Shuo Ren, Yanmin Qian, Yao Qian, Jian Wu, Michael Zeng, Xiangzhan Yu, and Furu Wei, “WavLM: Large-scale self-supervised pre-training for full stack speech processing,” arXiv preprint arXiv:2110.13900, 2021
[4] Binbin Zhang, Hang Lv, Pengcheng Guo, Qijie Shao, Chao Yang, Lei Xie, Xin Xu, Hui Bu, Xiaoyu Chen, Chenhen Zeng, Di Wu, and Zhendong Peng, "WenetSpeech: A 10000+ hours multi-domain Mandarin corpus for speech recognition," in Proc. ICASSP, 2021
[5] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser and Illia Polosukhin, "Attention is all you need," in Proc. NeurIPS, 2017
[6] Myle Ott, Sergey Edunov, Alexei Baevski, Angela Fan, Sam Gross, Nathan Ng, David Grangier, and Michael Auli, “fairseq: A fast, extensible toolkit for sequence modeling,” in Proc. NAACL, 2019.
[7] Shinji Watanabe, Takaaki Hori, Shigeki Karita, Tomoki Hayashi, Jiro Nishitoba, Yuya Unno, Nelson Enrique Yalta Soplin, Jahn Heymann, Matthew Wiesner, Nanxin Chen, Adithya Renduchintala, and Tsubasa Ochiai, “ESPnet: End-to-end speech processing toolkit,” in Proc. Interspeech, 2018, pp. 2207–2211
[8] Pengcheng Guo, Florian Boyer, Xuankai Chang, Tomoki Hayashi, Yosuke Higuchi, Hirofumi Inaguma, Naoyuki Kamo, Chenda Li, Daniel Garcia-Romero, Jiatong Shi, Jing Shi, Shinji Watanabe, Kun Wei, Wangyou Zhang and Yuekai Zhang, "Recent development on ESPnet tookit boosted by Conformer," in Proc. ICASSP, 2021
[9] Xuankai Chang, Takashi Maekaku, Pengcheng Guo, Jing Shi, Yen-Ju Lu, Aswin Shanmugam Subramanian, Tianzi Wang, Shu-wen Yang, Yu Tsao, Hung-yi Lee, and Shinji Watanabe, "An exploratino of self-supervised pretrained representations for end-to-end speech recognition," in Proc. ASRU, 2021
[10] Anmol Gulati, James Qin, Chung-Cheng Chiu, Niki Parmar, Yu Zhang, Jiahui Yu, Wei Han, Shibo Wang, Zhengdong Zhang, Yonghui Wu, and Ruoming Pan, “Conformer: Convolution-augmented Transformer for speech recognition,” in Proc. Interspeech, 2020, pp.5036–5040
更多阅读




#投 稿 通 道#
让你的文字被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
📝 稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
📬 投稿通道:
• 投稿邮箱:hr@paperweekly.site
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿

△长按添加PaperWeekly小编
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧




