

基于压缩域的端到端通用事件表示学习
End-to-End Compressed Video Representation Learning for Generic Event Boundary Detection**
这篇工作由字节跳动智能创作团队和中国科学院大学、中国科学院软件研究所共同完成。 传统的视频处理算法需要对视频进行解码,在解码后的 RGB 帧上进行训练和推理。然而视频解码本身需要占用比较可观的计算资源,并且视频相邻帧之间包含了大量的冗余信息。
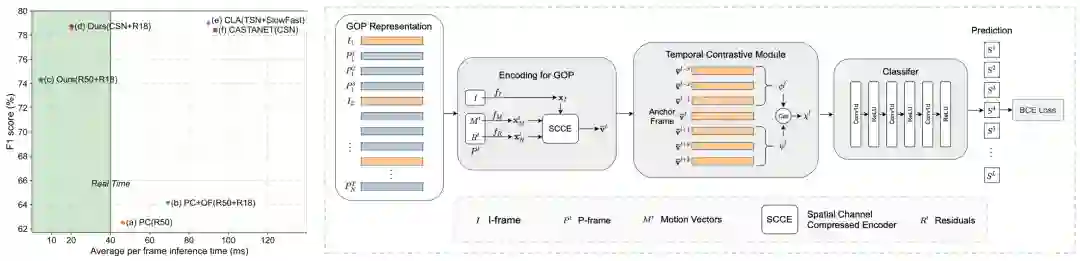
另外在视频编码格式中的运动向量(Motion Vector)和残差(Residual)包含了视频的运动信息,这些信息能够为更好地理解视频提供更多帮助。 基于上述两点考虑,文章提出了一种在视频压缩域(Compressed Domain)上进行端到端通用事件检测(GEBD)的解决方案,希望能够使用视频压缩域上的解码中间信息来对非关键帧进行快速高质量的特征提取。
为此,论文提出了 SCCP(Spatial Channel Compressed Encoder)模块。对于关键帧,在完全解码后使用常规骨干网络提取特征;对于非关键帧,通过使用运动向量和残差以及对应的关键帧特征在轻量级的网络上提取非关键帧的高质量特征;同时利用 Temporal Contrasitive 模块实现端到端的训练和推理。
实验证明在保持和传统完全解码方法精度相同的前提下,我们的方法在模型上的提速 4.5 倍。
成为VIP会员查看完整内容
相关内容

Arxiv
12+阅读 · 2021年5月30日
Arxiv
15+阅读 · 2020年2月28日
Arxiv
15+阅读 · 2018年1月5日
相关VIP内容
相关资讯
相关论文
Arxiv
12+阅读 · 2021年5月30日
Arxiv
15+阅读 · 2020年2月28日
Arxiv
15+阅读 · 2018年1月5日