神经网络模糊测试:将DNN应用于软件安全测试
编者按:软件安全问题一直是开发人员关注的重点,简单高效的漏洞探测方法能够为程序的平稳运行提供强大助力。近日,微软研究人员开发出一种可以用于发现软件安全漏洞的新方法。这个名为微软安全风险检测(Microsoft Security Risk Detection)的工具能够大大简化安全测试流程,让你无须成为安全问题专家也可以消除软件中的漏洞。本文译自 “Neural fuzzing: applying DNN to software security testing ”。
微软研究人员开发出一种用于发现软件安全漏洞的新方法——借助机器学习和深度神经网络,系统可以从既往经验中学习如何更好地发现这些漏洞。这个名为“神经网络模糊测试”的最新研究项目旨在对传统模糊测试技术加以强化,而且早期实验已经显现出良好的效果。
软件安全测试是一项艰巨任务,通常是由安全专家通过昂贵且针对局部的代码评审流程来实现,或者借助针对特定场景设计,专用而复杂的安全工具来检测和评估代码中的漏洞。微软最近发布了一个名为微软安全风险检测(Microsoft Security Risk Detection,缩写为MSRD)的工具,它大大简化了安全测试流程,让你无须成为安全问题专家也可以定位软件中的漏洞。这款基于Azure的工具已向Windows用户开放,并向Linux用户开放了预览版。

模糊测试
驱动这套微软安全风险检测工具(MSRD)的关键技术名为模糊测试(fuzz testing)。这种程序安全测试方法可以查找出导致程序被攻破的输入(如缓冲区溢出、内存访问冲突和无效指针引用取消等)。
模糊测试器(fuzzer)可以分成几个不同类别:
黑箱模糊测试器,也被称为“傻瓜模糊测试器”,完全依靠样本输入文件生成新的输入。
白箱模糊测试器,它对目标程序进行静态或动态分析,以此引导搜索更多新的输入,旨在尽可能多地探查代码路径。
灰箱模糊测试器,与黑箱模糊测试器相似,它对目标程序的结构没有任何了解,但可根据对目标程序既往执行行为的观察,利用反馈回路来指导搜索。
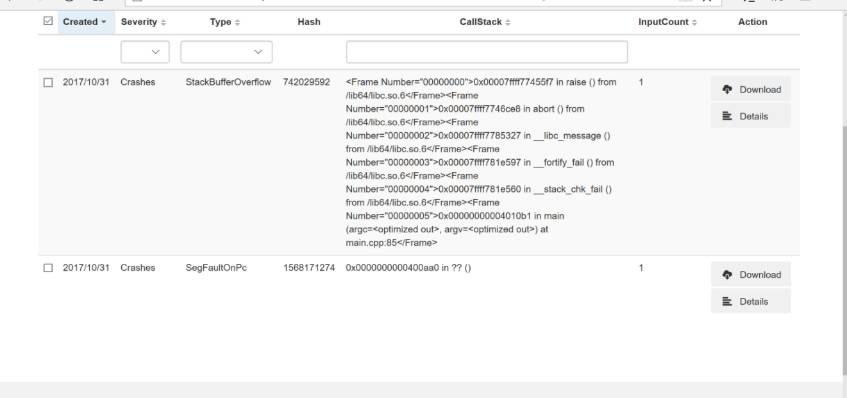
图一:由MSRD中支持的神经网络AFL报告的崩溃
神经网络模糊测试
今年早些时候,微软研究员William Blum、Rishabh Singh和Mohit Rajpal等人启动了一个研究项目,研究如何使用机器学习和深度神经网络来改进模糊测试技术,通过在灰箱模糊测试器的反馈回路中插入一个深度神经网络来研究机器学习模型的学习过程。
在最初的实验中,研究员们考察了系统是否能够随着时间推移,对当前模糊测试器的历史模糊迭代进行观察并从中学习,他们将神经网络模糊测试的方法应用于一种名为American Fuzzy Lop(AFL)的灰箱模糊测试器中,尝试使用四种不同类型的神经网络对四个目标程序进行实验,分别是ELF、PDF、PNG和XML四种不同文件格式的解析程序。
结果非常鼓舞人心——对于上述四种输入格式解析器而言,这种基于神经网络的方法在代码覆盖率、唯一代码的路径和崩溃方面都比传统AFL有了显著进步。
对于ELF和PNG这两种格式的解析器而言,基于长短期记忆(LSTM)神经网络模型的AFL系统在代码覆盖率方面比传统AFL提高了10%。
对于除PDF格式以外所有的解析器,神经网络AFL都能够比传统AFL找到更多的唯一路径。对于PNG解析器而言,在经历过24小时的模糊测试之后,它发现的非重复代码路径比传统AFL多一倍。
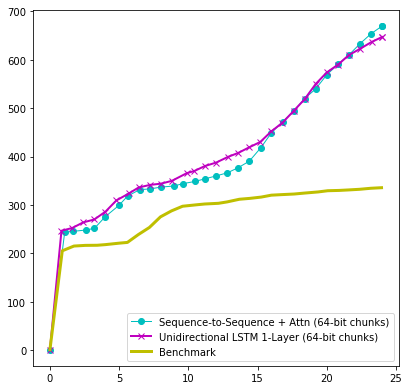
图二:libpng文件解析库中找到漏洞数量随时间变化图示
评估模糊测试器的方法之一是比较报告的崩溃次数。对于ELF文件解析器,神经网络AFL报告了至少20次崩溃,而传统AFL却未能报告任何崩溃。这一结果是令人惊讶的,因为神经网络AFL就是利用AFL自身进行训练的。同时,对于文本型文件格式(如XML),神经网络AFL发现的崩溃次数比传统AFL多38%。对于PDF而言,传统AFL在搜寻新代码路径方面总体上优于神经AFL。但是,这两个系统都没有报告任何崩溃。
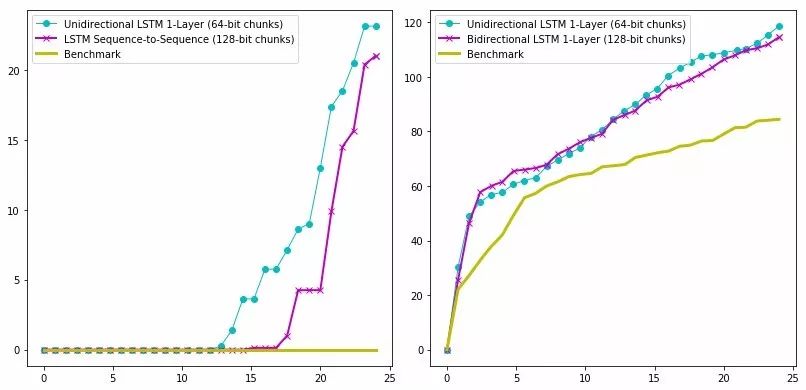
图三:针对readelf(左)和libxml(右)文件解析器报告的崩溃次数
总的来说,除了PDF以外,使用基于神经网络的模糊测试工具在每个实例上的表现都优于传统AFL。而面对PDF,神经网络AFL并没有优势的原因可能是因为在对神经模型进行查询时,PDF文件的较大尺寸会引起显著的资源开销。
总体而言,神经网络模糊测试方法催生了一种简单、高效和通用的灰箱模糊测试新途径。
简单:搜索漏洞并不依靠复杂的手工启发——系统从现有模糊测试器中学习策略。我们只需要向它提供一些字节序列,让它自行找出各种特征,并从中自动推广,进而预测哪种类型的输入比其他类型更重要,以及模糊测试器的注意力应该集中在何处。
高效:在AFL实验中,最初24小时内,神经网络AFL探测的唯一代码路径数量显著高于传统AFL。对于某些文件分析器,神经网络AFL甚至报告了AFL从未报告的崩溃。
通用:虽然这项研究只在AFL模糊测试工具上进行了测试,但这种方法可以应用于任何模糊测试器,其中包括黑箱及随机模糊测试器。
相比于使用深度神经网络进行模糊测试所能发挥的潜力而言,现阶段的神经网络模糊测试研究项目只是触及了皮毛而已。目前,这个模型只能学习模糊测试的代码定位,但接下来它还可以用来学习其它的模糊测试参数,如产生变种的类型或策略等。研究员们也在考虑为这一机器学习模型开发线上版本,让模糊测试器能够从不断进行的模糊迭代中永续学习。
点击文末【阅读原文】,访问微软安全风险检测(Microsoft Security Risk Detection)网站,了解更多详情。
你也许还想看:
● 程序修复程序:78.3%的“Bug修复正确率”是怎么做到的?

感谢你关注“微软研究院AI头条”,我们期待你的留言和投稿,共建交流平台。来稿请寄:msraai@microsoft.com。




