千亿参数!阿里清华联合推理业界最大中文多模态预训练器M6!实现跨模态生成
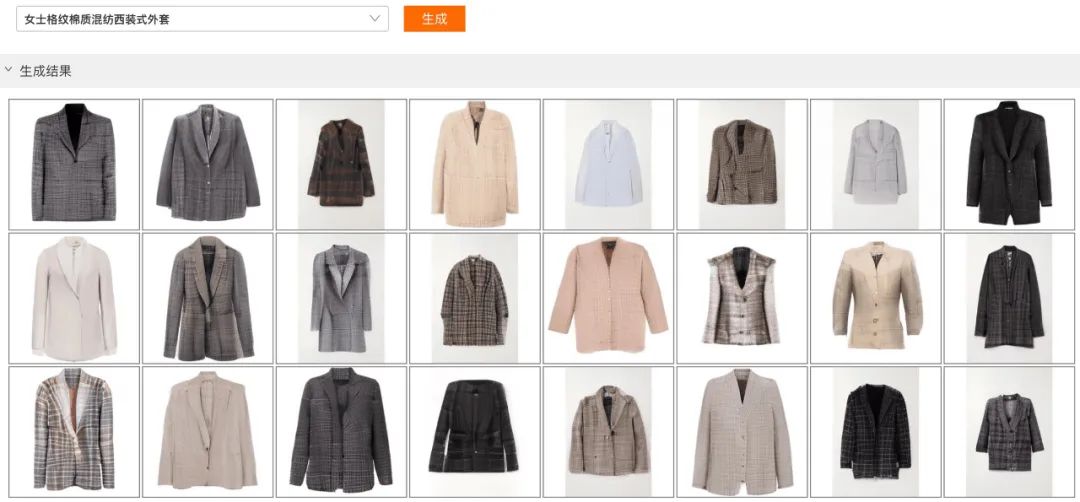
3月2日,阿里巴巴与清华大学联合发布业界最大的中文多模态预训练AI模型M6,该模型参数规模超千亿,同时具备文本、图像的理解和生成能力,图像设计效率超越人类,可应用于产品设计、信息检索、机器人对话、文学创作等领域。
预训练语言模型是让AI具备认知能力的关键技术,它突破了传统深度学习方法的瓶颈,是一种新型AI训练思路,即首先自动学习大量语言文字和图像数据,记忆和理解人类丰富的先验知识,再进一步学习专业领域信息,从而让AI同时掌握常识和专业知识。目前,谷歌、微软和 Facebook等企业已投入该技术的研发。
此次发布的M6模型参数规模达到1000亿,是多模态预训练领域史上最大的模型,其理解和生成能力超越传统AI。以图像生成为例,模型可设计包括服饰、鞋类、家具、首饰、书籍等在内的30多个物品类别的图像,最短一分钟即可完成作品的创作,效率超越普通设计师。

M6的突破源自多项底层技术创新。阿里巴巴研究团队基于自研Whale分布式框架,将参数规模扩展到千亿的同时,利用大规模数据并行和模型并行,训练速度提升10倍以上,仅需1-2天即可完成上亿数据的预训练。此外,M6模型首次将多模态预训练模型应用到基于文本的图像生成任务,结合向量量化生成对抗网络学习文本与图像编码共同建模的任务,能够生成清晰度高且细节丰富的图像。
阿里巴巴达摩院智能计算实验室资深算法专家杨红霞表示:“多模态预训练是下一代人工智能的基础,M6模型实现了训练效率和生成精度等多项突破,是当前众多中文多模态下游任务最优模型。”
作为国内最早投入认知智能研究的科技公司之一,阿里巴巴已有30多项认知智能领域研究成果被国际顶级会议收录;研究团队还将研发更高规模的万亿参数多模态预训练模型,进一步突破算力及预训练模型的极限,最终实现通用领域的高质量泛内容生成。
论文内容
M6: A Chinese Multimodal Pretrainer
Authors: Junyang Lin, Rui Men, An Yang, Chang Zhou, Ming Ding, Yichang Zhang, Peng Wang, Ang Wang, Le Jiang, Xianyan Jia, Jie Zhang, Jianwei Zhang, Xu Zou, Zhikang Li, Xiaodong Deng, Jie Liu, Jinbao Xue, Huiling Zhou, Jianxin Ma, Jin Yu, Yong Li, Wei Lin, Jingren Zhou, Jie Tang, Hongxia Yang

摘要:
在这项工作中,我们构建了最大的中文多模态预训练数据集,包含超过1.9TB的图像和292GB的文本,涵盖了广泛的领域。
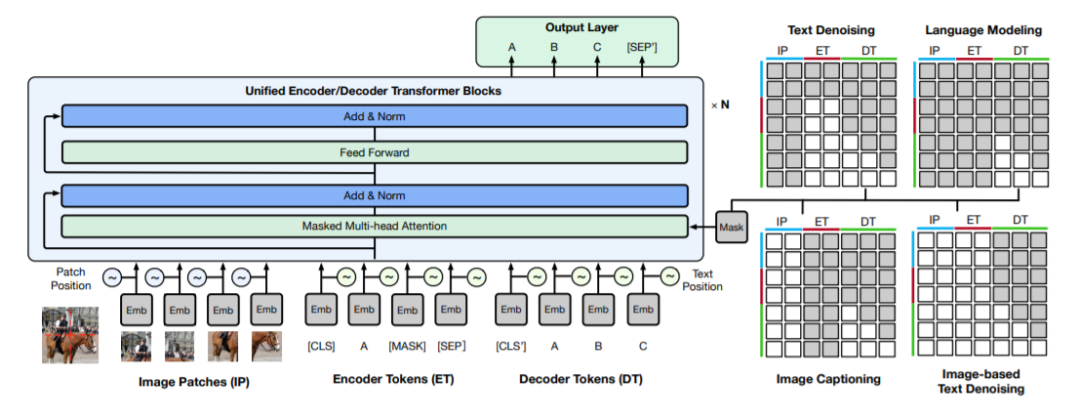
我们提出了一种跨模态预训练方法,称为M6,Multi-Modality to MultiModality Multitask Mega-transformer,对单模态和多模态数据进行统一的预训练。
我们将模型规模扩大到100亿和1000亿参数,并建立了最大的中文预训练模型。我们将该模型应用于一系列下游应用,并与强基线进行了比较,展示了其出色的性能。
在此基础上,我们专门设计了下游的文本引导图像生成任务,结果表明,经过微调的M6可以生成高分辨率、细节丰富的高质量图像。
地址:
https://www.zhuanzhi.ai/paper/2e6d7f64497d03f8aa3d6eb3aa2a1f42
引言
预训练已经成为自然语言处理(natural language processing, NLP)研究的一个热点[1,2,7,15,17,18,25,29,35,42,47]。最近的GPT-3具有超过175B的参数,这表明利用大数据训练的大模型具有非常大的容量,在下游任务中,特别是在零样本的情况下,它的性能超过了最先进的水平。同时,预训练在自然语言处理中的迅速发展也促进了跨模态预训练的发展。许多研究[4,10,16,20,22,23,26,27,36,49]为各种跨模态下游任务创造了最新的性能。
我们收集并构建了业界最大的中文多模态预训练数据,包括300GB文本和2TB图像。
我们提出用M6进行中文的多模态预训练,我们将模型规模扩大到100亿和1000亿参数。M6-10B和M6-100B都是最近最大的多模态预训练模型。
M6是通用的,在VQA中超过11.8%,在图像-文本匹配中超过10.3%。此外,M6能够生成高质量的图像。
通过精心设计的大规模分布式训练优化,M6在训练速度上具有明显优势,大大降低了训练成本,为多模态预训练的更广泛应用创造了可能。
https://mp.weixin.qq.com/s/kZi8u3a1JPA25a_xltxwmA
专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“M6” 就可以获取《千亿参数!阿里清华联合推理史上最大中文多模态预训练器M6!论文》专知下载链接





