与 TensorFlow 功能互补的腾讯 angel 发布 3.0 :高效处理千亿级别模型
近日,紧跟华为宣布新的 AI 框架即将开源的消息,腾讯又带来了全新的全栈机器学习平台 angel3.0。新版本功能特性覆盖了机器学习的各个阶段,包括:特征工程、模型训练、超参数调节和模型服务。自 2017 年 angel1.0 在 Github 上开源以来,angel 共获得星标数超过 4200、fork 数超 1000。腾讯发布了相关文章介绍了 angel3.0 更新细节等内容。
Angel 是一个基于 Parameter Server(PS)理念开发的高性能分布式机器学习平台,PS 架构良好的横向扩展能力让 Angel 能高效处理千亿级别的模型。
Angel 具有专门为处理高维稀疏特征特别优化的数学库,性能可达 breeze 数学库的 10 倍以上。
相比之下,Angel 更擅长于推荐模型和图网络模型相关领域(如图 1 所示),与 Tensorflow 和 PyTouch 的性能形成互补。
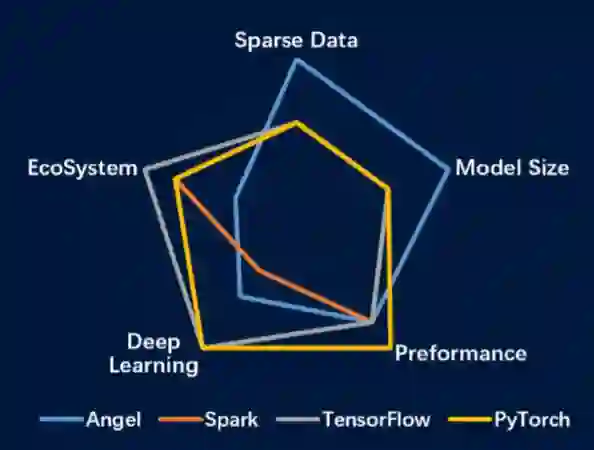
图 1 Angel 与主流平台的性能分布图
Angel PS 则提供参数存储和交换服务。在 3.0 版本中,我们对 Angel PS 功能进行了扩展,使得它可以存储任意类型的对象,例如:在图算法的实现过程中,我们使用 Angel PS 来存储大量复杂的对象。ML core 则是 Angel 自研的一套算法内核,它支持自动求导,可以使用 JSON 配置文件定义和运行算法。
除此之外,Angel 3.0 中还集成了 PyTorch 来作为计算引擎。目前它支持 3 种计算框架:原生的 Angel,Spark On Angel(SONA)和 PyTorch On Angel(PyTONA),这些计算框架可以使得 Spark 和 PyTorch 用户能够灵活切换到 Angel 平台。最上层包括了两个公共组件:AutoML 和模型服务。
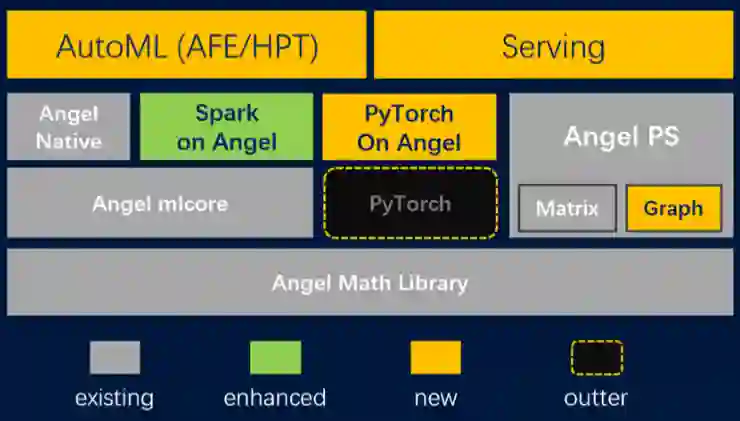
图 2 Angel 3.0 架构
-
自动特征工程:新增特征选择和组合方法,将特征合成、选择和重新索引以 pipeline 的形式呈现,用来迭代生成高阶合成特征; 新的计算引擎:SONA(加强)——特征工程支持索引为 Long 类型的向量;所有的算法被封装成 Spark 风格的 APIs;SONA 上的算法可以作为 Spark 的补充;PyTONA(新)—— PyTONA 作为图学习算法的引擎被引入,目前支持 GCN 和 GraphSage,同时也支持推荐领域的算法;
自动机器学习:Angel3.0 引入了 3 种超参数调节算法,包括:网格搜索、随机搜索和贝叶斯优化;
Angel 模型服务:Angel 提供一个跨平台的模型服务框架,支持 Angel、PyTorch 和 Spark 的模型,性能上与 TensorFlow Serving 相当;
Kubernetes:Angel3.0 支持 Kubernetes,可以在云上运行;
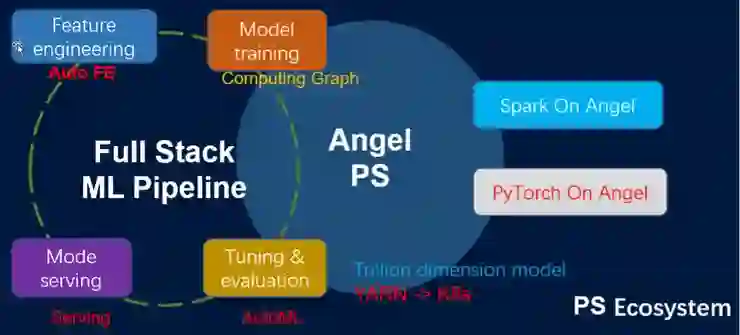
图 3 Angel 3.0 特性概览(红色的表示新增特性,白色的表示已有的但在持续改进的特性)
特征工程,例如:特征交叉和选择,对于工业界的机器学习应用具有重要意义。虽然 Spark 提供了一些特征选择算子,但仍有一些局限性,Angel 则基于 Spark 提供了更多的特征选择算子:
基于统计的运算符,包括 VarianceSelector 和 FtestSelector
基于模型的运算符,包括 LassoSelector 和 RandomForestSelector
大多数在线推荐系统经常选择线性算法,例如逻辑回归作为机器学习模型,但逻辑回归需要复杂的特征工程才能实现较高的精度,这使得自动特征合成至关重要。但是,现有的自动化的高阶特征合成方法带来了维度灾难。
为了解决这个问题,Angel 实现了一种迭代生成高阶合成特征的方法,每次迭代由两个阶段组成,即扩增阶段——任意特征的笛卡尔积;缩约阶段——特征选择和特征重索引;具体迭代步骤为:
首先任意的输入特征之间通过笛卡尔积生成合成特征(该步骤后,特征数量将以二次方式增加);
接下来,从合成特征中选择最重要的特征子集(使用例如 VarianceSelector 和 RandomForestSelector);
然后,重新索引所选择的特征以减少特征空间;
最后,合成特征与原始特征拼接在一起。
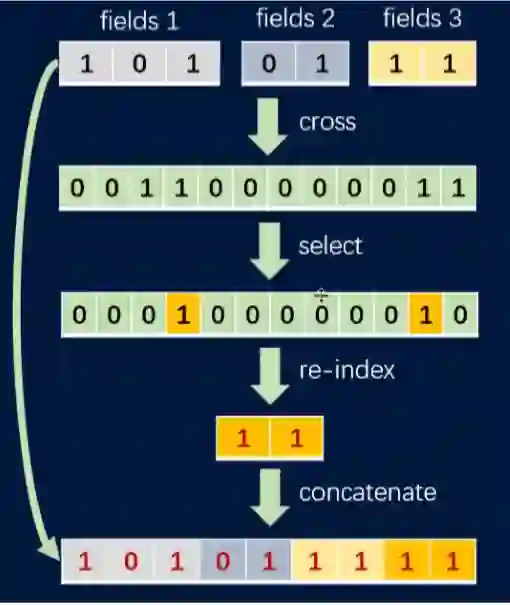
图 4 自动特征工程流程
如图 4 所示,这种特征合成方法线性地增加特征数量,避免了维度灾难。在 Higgs 数据集上的实验表明合成的特征能有效地提高模型精度(如表 1 所示)。

表 1 特征合成结果
Spark On Angel (SONA)
在 Angel 3.0 中,我们对 Spark On Angel 做了大幅度的优化,添加了新的特性:
Spark On Angel 中集成了特征工程。在集成的过程中并不是简单地借用 Spark 的特征工程,我们为所有的运算支持了长整型索引的向量使其能够训练高维稀疏模型;
与自动调参无缝连接;
Spark 用户能够通过 Spark-fashion API 将 Spark 转换成 Angel;
支持两种新的数据格式,即 LibFFM 和 Dummy。
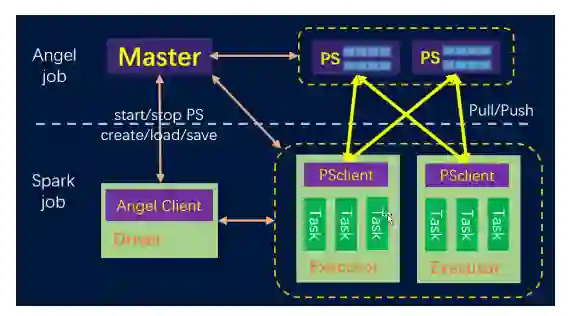
图 5 Spark On Angel 架构
除了这些大的特征,我们也在持续完善 Spark On Angel 的算法库,添加了一些新的算法,例如:Deep & Cross Network(DCN)和 Attention Factorization Machines(AFM)等;同时,对已有的算法做了大量的优化。图 6 提供了一个基于 Spark On Angel 的分布式算法示例,主要包含以下步骤:
图 6 Spark On Angel 算法示例
在程序开始时启动参数服务器,程序结束时关闭参数服务器;
将训练集和测试集以 Spark DataFrame 形式加载;
定义一个 Angel 模型并以 Spark 的参数设置方式为其设置参数。在这个示例中,算法是一个通过 JSON 定义的计算图;
使用「fit」方法来训练模型;
使用「evaluate」方法来评估已训练的模型。
在训练完成后,Spark On Angel 将会展示多种模型指标,如:准确率, ROC 曲线, AUC 等。用户可以保存训练好的模型以便下次使用。
PyTorch On Angel(PyTONA)
PyTorch On Angel 是 Angel 3.0 新增的特性,它主要是为了解决大规模图表示学习和深度学习模型训练问题。在过去几年时间,图卷积神经网络(GNN)快速发展,一系列的研究论文以及相关的算法问世:例如 GCN,GraphSAGE 和 GAT 等,研究和测试结果表明,它们能够比传统图表示学习更好的抽取图特征。
但大规模图的表示学习面临着两个主要的挑战:第一个挑战来自于超大规模图结构的存储以及访问,这要求系统不仅能存得下,还需要提供高效的访问接口;第二个挑战来自于 GNN 计算过程,它需要有高效的自动求导模块。
通过对 Angel 自身状况以及对业界已有系统的分析,我们发现:
TensorFlow 和 PyTorch 拥有高效的自动求导模块,但是它们不擅长处理高维度模型和稀疏数据;
Angel 擅长处理高维度模型和稀疏数据,虽然 Angel 自研的计算图框架(MLcore)也可以自动求导,但是在效率和功能完整性上却不及 TensorFlow 和 PyTorch,无法满足 GNN 的要求。
为了将两者的优势结合起来,我们基于 Angel PS 开发了 PyTorch On Angel 平台,希望通过 Angel PS 来存储大模型,同时使用 Spark 来作为 PyTorch 的分布式调度平台。最终得到 PyTorch On Angel 的架构如图 7 所示:
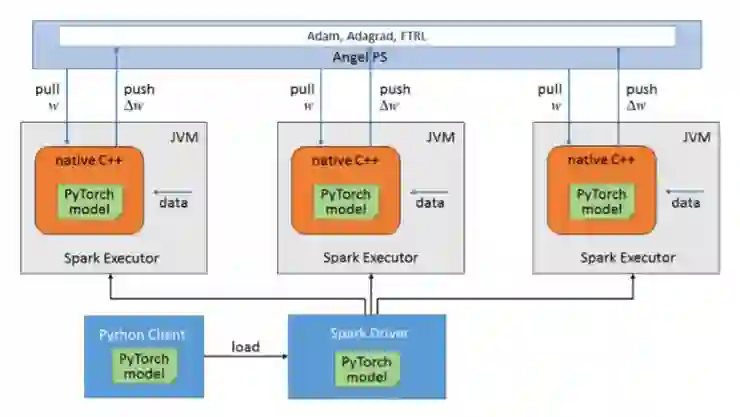
图 7 PyTorch On Angel 系统架构
PyTorch On Angel 具有 3 个主要的组件:
Angel PS:存储模型参数,图结构信息和节点特征等,并且提供模型参数和图相关数据结构的访问接口,例如需要提供两跳邻接访问接口;
Spark Driver:中央控制节点,负责计算任务的调度和一些全局的控制功能,例如发起创建矩阵、初始化模型、保存模型、写 checkpoint 以及恢复模型命令;
Spark Worker:读取计算数据,同时从 PS 上拉取模型参数和网络结构等信息,然后将这些训练数据参数和网络结构传给 PyTorch,PyTorch 负责具体的计算并且返回梯度,最后 Spark Worker 将梯度推送到 PS 更新模型。
这些组件都已封装完备,因此在 PyTorch On Angel 平台上开发新算法,只需关注算法逻辑即可。图 8 展示了一个开发案例,算法开发完成后,将代码保存为 pt 文件,然后将 pt 文件提交给 PyTorch On Angel 平台就可以实现分布式训练了。
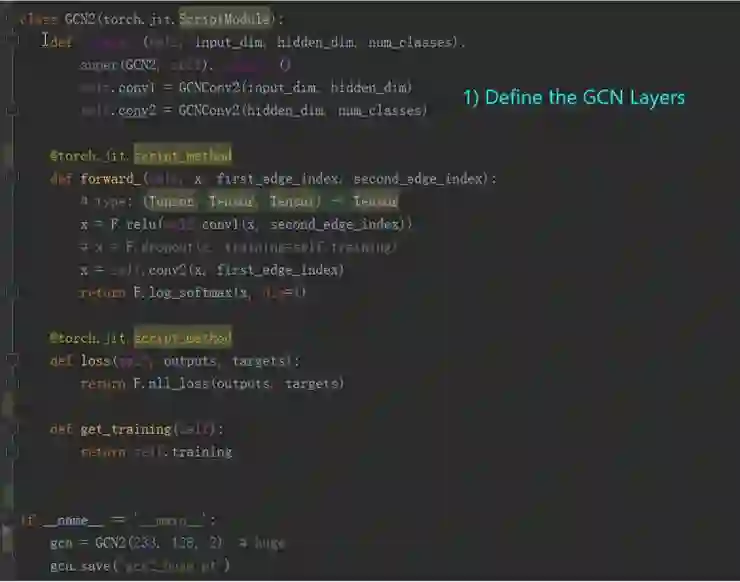
图 8 在 PyTorch On Angel 上实现 GCN 的例子
目前,我们已经在 PyTorch On Angel 上实现了许多算法:包括推荐领域常见的算法(FM,DeepFM,Wide & Deep,xDeepFM,AttentionFM,DCN 和 PNN 等)和 GNN 算法(GCN 和 GraphSAGE)。在未来,我们将进一步丰富 PyTorch On Angel 的算法库。
结合了 PyTorch 和 Angel 的优点,PyTorch On Angel 在算法性能方面有很大的优势:对于推荐领域常见的深度学习算法,性能可以大大超过了 TensorFlow 。下图是在公开的数据集 criteo kaggle2014(4500 万训练样本,100w 特征)上做的对比测试:
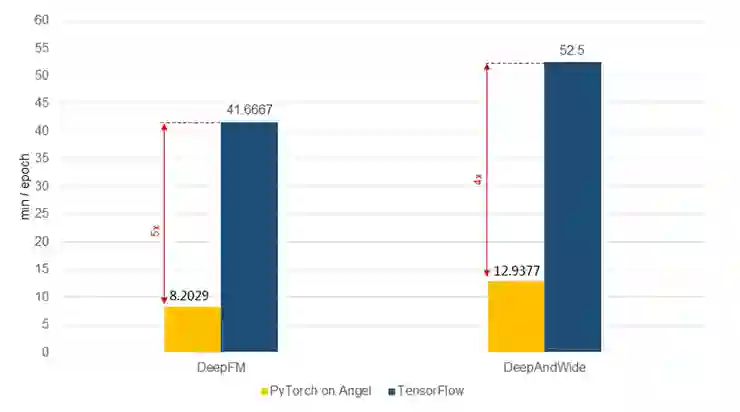
图 9 PyTorch On Angel 和 TensorFlow 性能对比测试
除了性能方面的优势,PyTorch On Angel 易用性也较好。PyTorch 运行在 Spark 的 Executor 中,可以实现 Spark 图数据预处理和 PyTorch 模型训练的无缝对接,在一个程序中完成整个计算过程。
自动超参数调节
传统超参数调节的方式有两种(如图 10 所示):
网格搜索:网格搜索将整个搜索空间切分为网格,假设超参数是同等重要的。这种方式虽然直观,但有两个明显的缺点。第一个是计算代价随参数数量的增长而呈指数增长,其次是超参数的重要程度常常不同,网格搜索可能会花费太多资源来优化不太重要的超参数;
随机搜索:随机采样超参数组合,并评估抽样组合。虽然这种方法可能关注更重要的超参数,但是无法保证找到最佳组合;
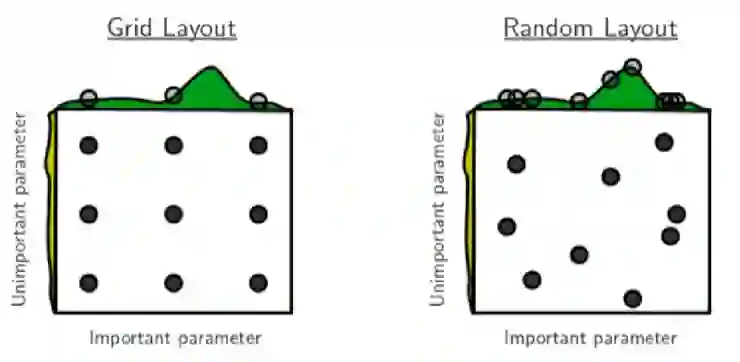
图 10 网格搜索和随机搜索
贝叶斯优化与传统的无模型方法不同,它使用计算成本较低的代理函数(surrogate function)来近似原始目标函数。在贝叶斯优化中,代理函数生成超参数组合的概率均值和方差。然后,效用函数(acquisition function)将评估超参数组合的预期损失或改进。这样的概率解释方法使贝叶斯优化能够使用较少的成本找到目标函数的较优解。
Angel 3.0 包括传统的两种方法和贝叶斯算法优化。对贝叶斯优化,Angel 实现了以下的功能:
代理函数。除了常用的两种模型(高斯过程和随机森林),也实现了 EM + LBFGS 优化高斯过程内核函数中的超参数;
效用函数:实现了 PI(Probability of improvement),EI(Expected Improvement)和 UCB(Upper Confidence Bound)。
由于每次评估目标函数的计算成本可能较大,如果观察到候选超参数组合在开始的若干轮迭代中表现不佳,可以提前停止这些候选超参数组合。Angel 3.0 版本中实现了该策略。表 2 展示了在逻辑回归算法的实验,调节的超参数是学习速度和学习速度衰减率,结果显示贝叶斯优化的性能优于随机搜索和网格搜索,而随机搜索的结果略优于网格搜索。

表 2 不同超参数自动条件方法的效果对比
Angel Serving
为了满足在生产环境中高效地进行模型服务的需求,我们在 Angel 3.0 中实现了 Angel Serving 子系统,它是一个可拓展性强、高性能的机器学习模型服务系统,是全栈式机器学习平台 Angel 的上层服务入口,使 Angel 生态能够形成闭环。图 11 展示了 Angel Serving 的架构设计。
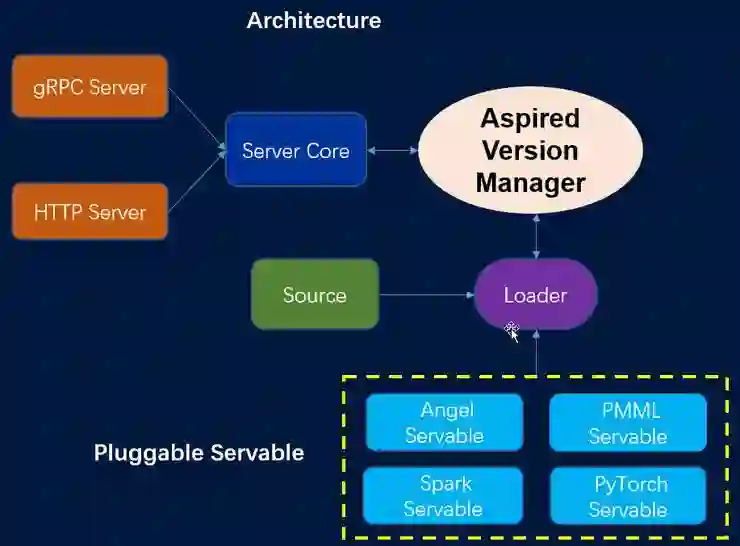
图 11 Angel Serving 架构
Angel Serving 主要特征包括:
支持多种类型的 API 访问服务,包括 gRPC 和 Restful 接口;
Angel Serving 是一个通用的机器学习服务框架。可插拔机制设计使得来自其他第三方机器学习平台的模型可以与 Angel Serving 兼容,目前已经支持三种平台的模型:Angel,PyTorch 和支持 PMML 模型格式的平台(Spark、XGBoost 等);
受 TensorFlow Serving 的启发,Angel Serving 提供细粒度版本控制策略。包括使用模型的最早、最新以及指定版本进行服务;
Angel Serving 还提供丰富的模型服务监控指标,包括:QPS(每秒请求数)、总的请求数以及成功请求总数、请求的响应时间分布以及平均响应时间。
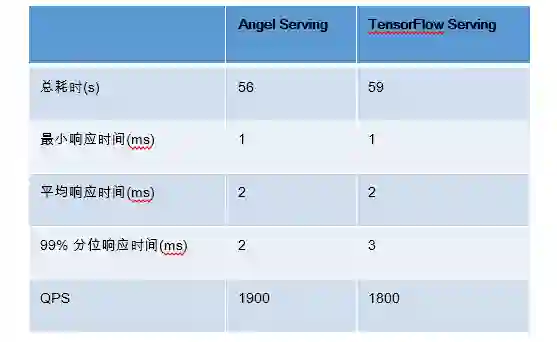
表 3 Angel Serving 和 Tensorflow Serving 性能对比
表 3 展示了 Angel Serving 和 TensorFlow Serving 性能对比结果,我们使用具有 100 万个特征的 DeepFM 模型,向服务发送 100,000 个预测请求。Angel Serving 和 TensorFlow Serving 的总耗时分别为 56 秒和 59 秒。两个服务系统的平均响应时间都为 2 毫秒。Angel Serving 的 QPS 是 1,900,而 TensorFlow Serving 的 QPS 是 1,800。
Angel 开源地址:







