【CVPR2020-中科院计算所】多模态GNN:在视觉信息和场景文字上联合推理

即使有可靠的OCR模型,要回答需要在图片中阅读文字的问题,也对现有模型构成了一个挑战。其中最困难的是图片中经常有罕见字,多义字,比如地名,产品名,球队名。
为了克服这个困难,我们的模型利用了图片中多个模态的丰富信息来推测图片中文字的语义,例如酒瓶上显眼位置的字样很可能是酒名。
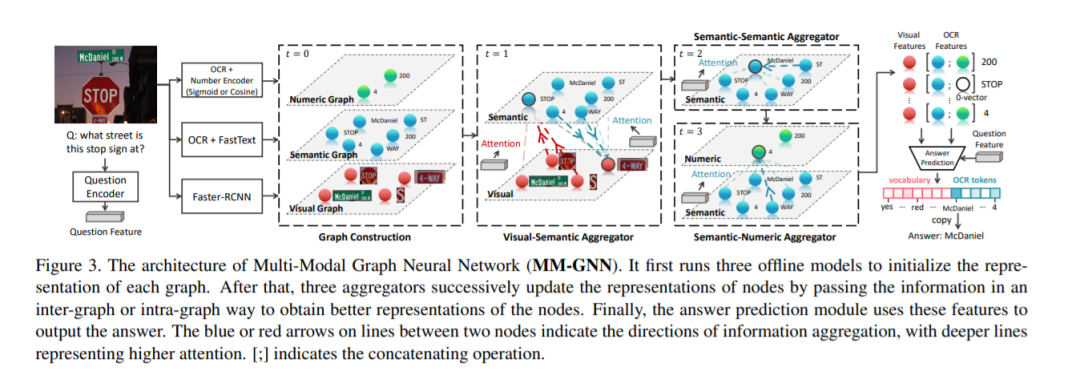
有了这样的直观感受,我们设计了一个新的VQA模型---多模态图神经网络(MM-GNN)。它会首先构建一个具有三个子图的特征节点图,分别描述视觉,文字,和数字模态。此后,我们设计了三个融合子,在子图间或子图内进行信息传递。增强过后的节点特征被证明可以很好地帮助下游任务,我们在ST-VQA和Facebook的Text-VQA上都取得了SOTA的成绩。
https://www.zhuanzhi.ai/paper/f1260471e6f694ec2b3ba74413a5049f
https://arxiv.org/abs/2003.13962
专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“MGNN” 就可以获取《【CVPR2020-中科院计算所】多模态GNN:在视觉信息和场景文字上联合推理》专知下载链接



登录查看更多
相关内容
专知会员服务
54+阅读 · 2020年3月3日
专知会员服务
95+阅读 · 2019年11月8日
Arxiv
23+阅读 · 2019年11月5日
Arxiv
8+阅读 · 2019年3月4日




相关VIP内容
专知会员服务
54+阅读 · 2020年3月3日
专知会员服务
95+阅读 · 2019年11月8日
相关资讯
相关论文
Arxiv
23+阅读 · 2019年11月5日
Arxiv
8+阅读 · 2019年3月4日