非自回归生成研究最新综述,近200篇文献揭示挑战和未来方向

(本文阅读时间:10分钟)
在如机器翻译、对话生成、语音合成等自然语言、语音等生成任务中,自回归(auto-regressive,AR)生成是一种最常采用的生成方法。简单来说,AR 生成指的是用迭代循环的方式来依次生成一句语音或文本。比如,为了生成一句长度为5的句子,AR 生成首先会生成第一个词语,然后基于第一个词语生成第二个词语,再基于前二个词语生成第三个词语,以此类推。由于每次新的词语生成都依赖于之前生成的词语,因此自回归的生成方式能够保证生成的准确度。
但显然,这样循环的生成方式效率非常低,尤其是对生成长句子来说则更为明显。为了加速生成过程,非自回归(non-autoregressive,NAR)生成被提出,通过一次性并行地生成句子中所有词语的方式,NAR 生成方法极大地提升了生成效率。然而,NAR 生成的准确率并没有得到保证,其性能与自回归生成相比仍有一定差距。因此,如何平衡好 AR 生成与 NAR 生成的优劣,是当下生成任务的研究重点。

NAR 生成在神经机器翻译 (neural machine translation,NMT) 中首次被提出,此后 NAR 生成便引起了机器学习和自然语言处理领域的广泛关注。如前文所述,虽然 NAR 生成可以显著提升机器翻译的推理生成速度,但与 AR 生成相比,其加速是在牺牲翻译准确性的代价上实现的。近年来,为了弥补 NAR 生成和 AR 生成之间的准确性差距,许多新的模型和算法陆续被提出。
为了促进 NAR 生成模型的发展,微软亚洲研究院与苏州大学的研究员们共同撰写了综述论文“A Survey on Non-Autoregressive Generation for Neural Machine Translation and Beyond”(点击阅读原文,查看论文详情 )。
在文章中,研究员们给出了一个系统、全面的综述。首先,研究员们从不同方面比较和讨论了各种非自回归翻译(non-autoregressive translation,NAT)模型,具体来说就是对 NAT 的工作进行了几组不同的分类,包括数据操作(data manipulation)、建模方法(modeling methods)、训练准则(training criteria)、解码算法(decoding ways)以及利用预训练模型(benefit from pre-training)。此外,研究员们还简要总结回顾了 NAR 生成在机器翻译之外的其他应用,例如对话生成、文本摘要、语法纠错、语义解析、语音合成和自动语音识别等等。最后,研究员们讨论了 NAR 未来值得继续探索的潜在方向,包括减少对知识蒸馏(knowledge distillation,KD)的依赖性、动态解码长度预测、NAR 生成的预训练,以及更广泛的应用。图1展示了本篇综述论文的整体结构。
研究员们希望该综述文章可以帮助研究人员更好地了解 NAR 生成的最新进展,启发更先进的 NAR 模型和算法的设计,使行业从业者能够根据其所在领域选择合适的解决方案。
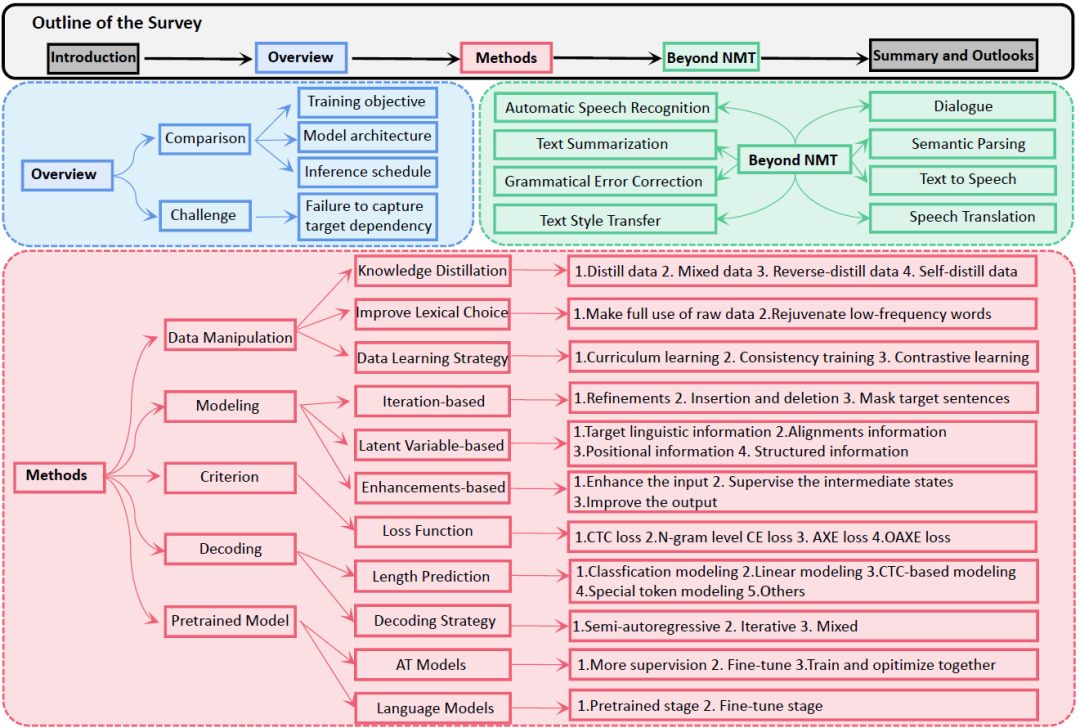
图1:非自回归(NAR)生成研究综述概览架构图
传统的自回归机器翻译(autoregressive translation,AT)模型由编码器和解码器构成,编码器对源语句进行编码后输至解码器,然后解码器根据源语句和上一步预测的目标端语言单词来预测下一个单词,这种逐字的生成方式限制了 AT 模型的解码速度。而为了实现在训练和推理时并行的解码方式, NAT 仅仅依赖源语句信息来生成所有目标单词,摒弃了目标端单词之间的条件依赖。这种方式极大地加速了模型的解码,但也增加了 NAR 模型的训练难度,造成模型“难以建模目标语言单词之间的条件信息”。
针对该挑战,现有的工作提出了多种解决方案。综述文章对现有工作进行了分类,从数据、模型、损失函数、解码算法、利用预训练模型五个角度对相关方法进行了介绍和比较。其中,数据、模型和损失函数是自回归文本生成模型的三个基本组成部分,这方面的工作旨在研究上述三个方面的传统方法在 NAR 模型上的不足,并进行相应的改进;解码算法和利用预训练模型则是非自回归文本生成模型中区别于 AR 生成的特殊模块,包括目标语句长度预测、非自回归预训练等,这方面的工作旨在设计合理、有效的算法来最大化地提升 NAR 生成模型的效果。这几方面的联系如图2所示。
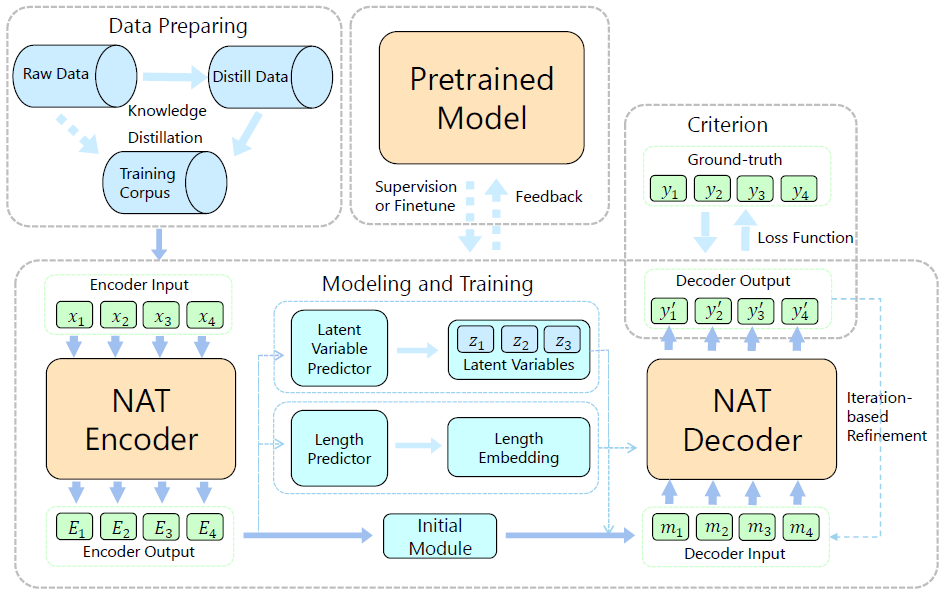
图2:非自回归机器翻译模型的主要框架。其中涉及数据处理、模型改进、训练准则、解码方式、预训练模型的利用等。
具体来说,上述五个方面的改进如下:
1. 数据层面进行的改进,包括利用知识蒸馏来生成数据、设计数据学习算法等。利用预训练 NAR 模型,基于知识蒸馏的方法将训练集中的源语句进行翻译,并将源语句和翻译结果作为 NAR 模型的训练集。这种方式可以减少训练数据的多样性,减轻 NAR 模型的训练难度。请注意数据层面的方法是通用的方法,例如,基于知识蒸馏的方法被广泛应用在文中介绍的大部分 NAR 生成模型中。
2. 模型层面进行的改进,包括设计迭代式模型、基于隐变量的模型以及增强解码器模型结构等。其中,迭代式模型将原始一次解码的 NAR 模型扩展成为多次迭代解码的模型,这样在进行每轮迭代时,上一轮迭代的结果可以作为目标语言端的依赖信息,将一次解码的难度分摊到多次迭代中,从而提升 NAR 模型的效果。与一次解码的 NAR 模型相比,迭代式的模型翻译效果更好,但也牺牲了一部分翻译速度,是属于 AR 模型和 NAR 模型的中间态。
3. 损失函数层面进行的改进,主要针对传统交叉熵损失函数的问题,提出一系列改进方法,包括基于 CTC、n-gram、以及引入顺序信息的损失函数。其中,由于 n-gram 的方法针对传统的交叉熵损失函数只能提供单词级别的监督信息而无法提供全局信息,研究员们提出了优化预测和目标之间 Bag of N-gram 差异的损失函数,以补充交叉熵损失函数中缺失的全局信息,以更好地对 NAR 模型进行优化。
4. 解码算法层面进行的改进,包括对 NAR 模型的长度预测模块进行改进,以及对传统解码算法的改进。由于 NAR 模型无法像 AR 模型一样隐式地在解码过程中决定目标语句的长度,因此需要在解码过程开始前就对目标语句的长度进行显式预测。这个步骤十分重要,因为目标语句的长度是否匹配直接影响模型最终的翻译效果。因此,类似自回归解码中的 Beam Search,有模型提出了提升长度预测准确率的方法,如多个长度并行解码等。这些方法也被广泛应用在 NAR 模型中。
5. 利用预训练模型的方法,包括利用自回归教师翻译模型的方法,和利用单语大规模预训练语言模型的方法。其中,由于 NAR 模型和 AR 模型结构相似,并且 AR 模型的翻译准确度更高,因此很多方法提出利用预训练的 AR 模型来额外监督 NAR 模型的训练,包括在隐变量层面引入额外监督信息,和基于课程学习的迁移学习方法等。
研究员们将文中讨论的相关论文按照类别列在了表1中,供大家查阅。
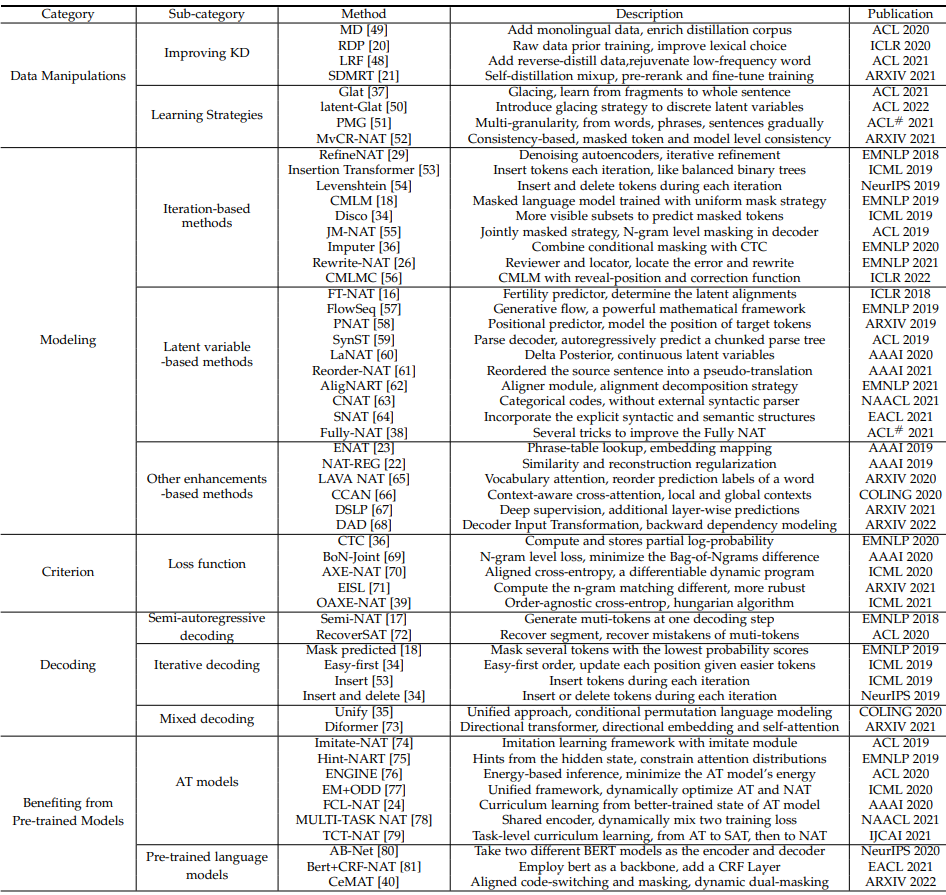
表1:针对 NAT 模型5个方面的研究总结以及具体的相关工作
NAR 除了在 NMT 中的应用之外,还在其它许多的任务中也得到了扩展应用,其中包括文本生成任务,如文本补全、摘要生成、语法纠正、对话、风格变化,语义解析任务,文本语音转化任务,语音翻译任务等等。研究员们在综述文章中给出了一些具体实例的介绍,同时也给出了这些相关工作的实现与资源列表。
为了促进未来 NAR 的发展,研究员们对当前 NAR 产生的问题进行了总结,并对未来可能的方向进行了展望,具体包括:(1)如何能够摆脱当下 NAR 严重依赖 AR 进行知识蒸馏的技术方案;(2)如何能够降低迭代式 NAR 模型的计算复杂度以更好地关注纯 NAR 模型;(3)动态的预测目标端文本的生成长度值得深入探索;(4)如何像 AR 模型一般将 NAR 模型扩展到多语言多任务的环境中是需要进一步关注的;(5)如何对 NAR 模型进行更好的预训练。以上这些都是具有研究前景的研究问题。
希望通过本篇综述,在不同领域进行生成任务研究的学者们能够对 NAR 生成有更全面的认识,并且激发创造更加先进的 NAR 模型,以促进 NAR 未来的发展,影响更广阔的生成场景。
相关链接:
论文:
https://arxiv.org/pdf/2204.09269.pdf
GitHub:
https://github.com/LitterBrother-Xiao/Overview-of-Non-autoregressive-Applications
你也许还想看: