爱尔兰都柏林城市大学博士生Lifeng Han《机器翻译评测研究》综述论文!
![]()
自从 1950 年代开始,机器翻译成为人工智能研究发展的重要任务 之一,经历了几个不同时期和阶段性发展,包括基于规则的方法、统计的方 法、和最近提出的基于神经网络的学习方法。伴随这几个阶段性飞跃的是机器 翻译的评测研究与发展,尤其是评测方法在统计翻译和神经翻译研究上所扮 演的重要角色。机器翻译的评测任务不仅仅在于评价机器翻译质量,还在于及 时的反馈给机器翻译研究人员机器翻译本身存在的问题,如何去改进以及如 何去优化。在一些实际的应用领域,比如在没有参考译文的情况下,机器翻译 的质量估计更是起到重要的指示作用来揭示自动翻译目标译文的可信度。这 份报告主要包括一下内容:机器翻译评测的简史、研究方法分类、以及前沿的 进展,这其中包括人工评测、自动评测、和评测方法的评测(元评测)。人工评 测和自动评测包含基于参考译文的和不需参考译文参与的;自动评测方法包 括传统字符串匹配、应用句法和语义的模型、以及深度学习模型;评测方法的 评测包含估计人工评测的可信度、自动评测的可信度、和测试集的可信度等。前沿的评测方法进展包括基于任务的评测、基于大数据预训练的模型、以及应 用蒸馏技术的轻便优化模型。
https://www.zhuanzhi.ai/paper/1a1dbb2ca0c5430b4de224253237f95d
机器翻译 (machine translation) 的研究始于 1950 年代 [152],隶属于机器智能 框架下的计算语言学 (computational linguistics) 的一个重要分支。机器翻译 经历了基于规则理论模型 (rule-based)、基于实例的方法 (example-based)、基 于概率统计学 (statistical MT, SMT)、和近年来的基于机器学习神经网络的 方法 (neural MT, NMT) [18, 122, 32, 88, 33, 83, 151, 149, 91]。虽然机器翻译 的质量持续改进,自动翻译的目标译文依然没有真正达到人类翻译专家的水平,这个现象在大部分语料对和不同领域的测试集上非常明显,最近的研究包 括反应普遍流行的翻译测试集的狭隘性和文学领域 (literature domain) 机器 翻译的表现很不佳 [95, 108, 77, 79]。因此,一如既往,机器翻译的评测 (MT evaluation, MTE) 扮演着推动机器翻译发展的重要角色 [77, 80]。机器翻译质量的评测本身是一个很有挑战性的研究课题,这源于翻译本身的多样性、语言 的多变性和丰富性、以及语义相似度计算的复杂性。
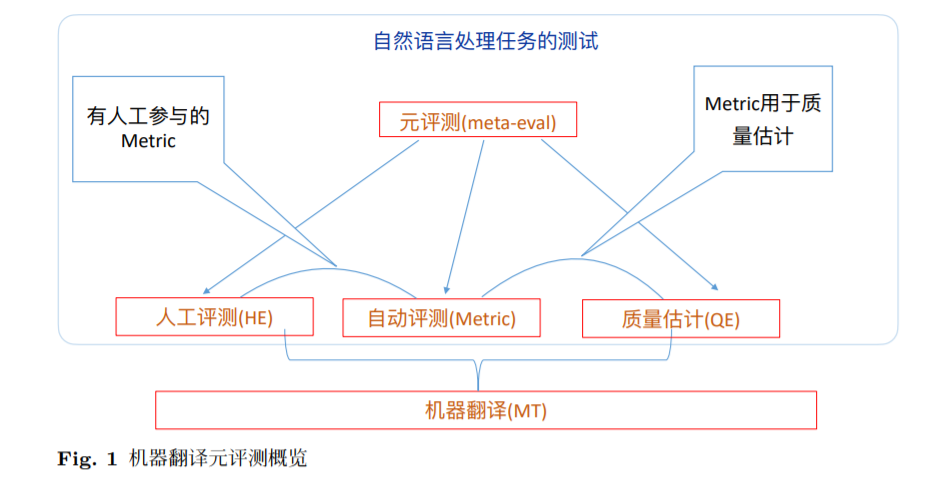
这份报告包括对人工评测、自动评测、和针对评测的评测(元评测)的介 绍、以及该领域一些前沿的研究进展,请参见图1,其中还包括交叉性的研究 比如有人工参与的 Metric、以及 Metric 用于质量估计的研究。图1的上部分 框架还揭示这个元评测的理论图也可应用于大部分的自然语言处理评测任务、 不仅限于机器翻译。
![]()
有关机器翻译评测的国际赛事包括每年一届的统计机器翻译会议(WMT) [89, 21, 23, 24, 25, 26, 27, 12, 13, 14, 15, 16, 17, 8, 9, 10] 所组织的人工评 测、自动评测(Metrics)和质量估计任务(QE),美国国家标椎和技术机构 (NIST)组织的机器翻译比赛 [100] 1,和语音语言技术国际研讨会(IWSLT) [46, 124, 125, 49] 协办的文本翻译赛事;地区性的赛事包括中国机器翻译研讨会(CWMT)。这份报告的大部分方法来自对以上国际和地区性的评测赛事的 总结。
从翻译教学和翻译工业应用的角度,[138] 在 2005 年做了有关机器翻译错误 分类的研究。欧洲机器翻译研究联合项目 EuroMatrix 于 2007 年的一份报 告简介了人工评测和当时流行的自动评测 [48]。美国国防先进研究项目机构 (DARPA)的 GALE 项目助攻机器翻译并在 2009 年的一份汇报中介绍了自 动评测和半自动评测,包含基于任务的和有人工参与的评测方法,其中 HTER 是该项目主要信赖评测指标。该报告还指出评测方法可用来机器翻译参数的 优化 [43]。2013 年欧洲机器翻译会议(EAMT)的一份邀请报告阐述了该作 者所在机构开发的 Asiya 在线机器翻译错误分析平台。同时还提及了机器翻 译评测的简史,包含基于词面相似度的方法和语言学驱动的方法。这份报告区 别于以上工作,在人工评测、自动评测、和元评测上分别加以综合介绍,并且 对近几年的该领域研究进展进行更新讲解。此报告是基于我们近期发表在 “翻 译建模:数字时代的翻译学 (MoTra21) ” 国际研讨会的工作 [80]。
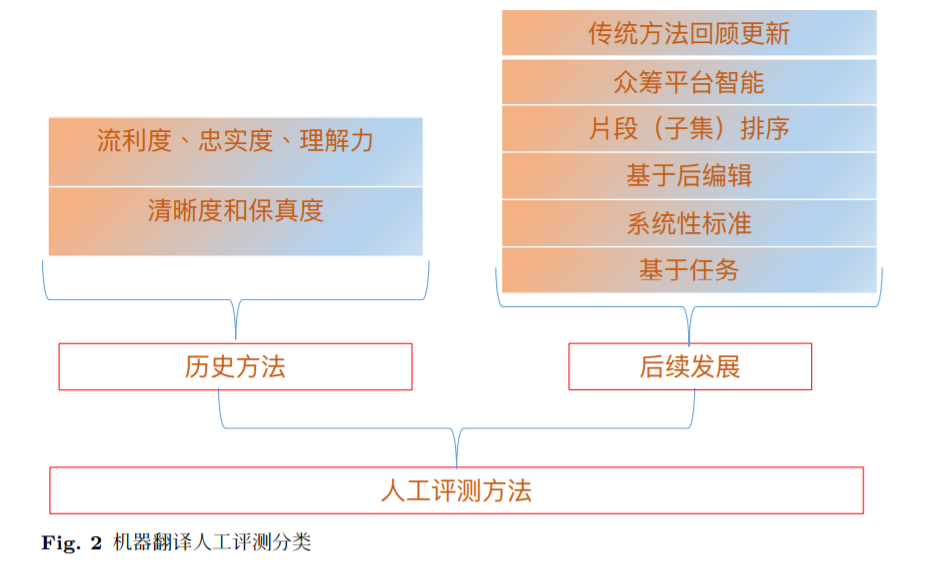
人工评测部分我们分两个小节介绍传统的方法和后续发展的方法,参见图2。
![]()
早期的机器翻译人工评价标准始于美国自动语言处理指导委员会 (ALPAC) [28] 所制定的 “清晰度” 和 “保真度”。清晰度被定义为:尽最大可能地,翻译文本应该读起来像正常的认真写出来的片段,并且容易理解,就像是一开始就 是用目标语言所写的。保真度被定义为:翻译文本应该尽小可能地对源语言 文本进行扭曲、歪曲、或者制造争议。
在 1990 年代,美国先进研究项目机构 (ARPA) 制定新的机器翻译评测标 准,包含流利度、忠实度、和理解力 [34]。这些标准被后续机器翻译竞赛所采 纳 [154]。流利度反应翻译文本的句法和语法正确性和流畅性,流利度的判断 不需要参考原文;忠实度反应对原文的保真性,需要有源语言文本的指导;理 解力反应信息度也就是看一个机器翻译系统能否输出给用户充分有效的和必 要的信息。最初的流利度和忠实度的设计包含五个不同等级;而对于理解力, 则设计了六个不同的问题让专业评判者回答。由于流利度和忠实度的互补性和易用性,机器翻译研究人员对这两个指标 进行了不同程度的应用、修改和整合等。比如以 “准确性” 作为整合的标准,[7] 对准确性加以分类,包括简单字符串、生成字符串、和解析树的准确性。[133] 的工作进行了流利度和所需字数的相关性计算来区分人工翻译和机器翻译。语 言数据集团 (LDC)2采用五个等级的流利度和忠实度来评估 NIST 的机器翻译 比赛。其中对流利度的判断除了语法要求,还包含了对习惯用词(惯用语)的 选择。
[144] 则对忠实度进行了四个等级的划分:非常、一般、较差、和完全不忠 实。非常 (highly): 翻译文本非常信实的传达原文意思;一般 (fairly): 翻译文 本在传达原文意思上一般表现一般,在字序、时态、语气、数字等方面有问题, 或者存在重复、添加或遗漏字词;较差 (poorly): 译文没有足够反应到原文意 思;完全不忠实 (completely not): 译文没有反应原文的任何意思。
后续和近期发展的人工评测归为以下几类:基于任务 (task)、后编辑 (postediting)、新标准、子集排序 (segment-ranking)、众筹平台 (crowd-sourcing)、 和对传统方法的回顾更新。这种分法是为了便捷需要,有的人工评测方法可以 涉及多个子类的交叉,比如基于任务和后编辑的两个子类型。
人工评测一直以来作为评测机器翻译质量的最终标准,但是人工评测也存在 很多缺陷,比如耗时、昂贵、不可重复 (抑或不可重用) 性、以及很多情况下 出现的人工评价人员之间的不一致性(主观性)。因此自动评测方法成为技术 和实践上的双重需求。自动评价的产生伴随着几个不同的类型,包括需要参考 译文的和不基于参考译文的情况。在需要参考译文的模型里又包括使用单个 参考译文和多项参考译文的类型 [103, 66, 80]。基于参考译文的自动翻译评测 模型,多属于计算自动译文输出和参考译文之间的相似度来评价翻译质量。当 然,语言相似度的计算是一个很有争议、也很有挑战性的问题,比如句法上、 语义上、风格上、写作领域和标准上的不同和变化等。不依赖于参考译文的评 价模型大多依赖机器学习的特征模型,从源语言的原句字和目标语言的译文 里提取有效特征来估计译文质量、这些特征可以包括词性、句法、语言模型等。与人工评价相比,自动评价的好处包括廉价、快速、可重复性、和可用来调整 和优化机器翻译的模型参数等。
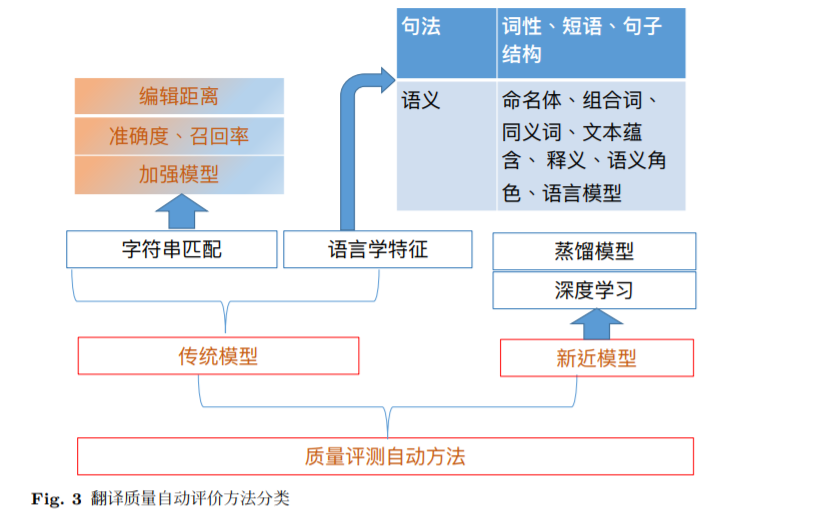
在本节,我们将传统的自动翻译评价模型分为基于字符串匹配的(n-gram) 和应用语言学特征的两类。在字符串匹配的种类里又包括基于编辑距离、准确 度和召回率、以及加强模型的。在语言学特征上我们把基于句法和语义的分两 个子类。其中句法特征包括词性、短语、句子结构等,而语义特征包括命名体、 组合词、同义词、文本蕴含、释义、语义角色、和语言模型等。我们将基于深 度学习和大规模预训练模型的评测方法归为新近模型一类。在这一个领域,最 近又发展了优化大数据和大模型花费的蒸馏模型。总览见图3。当然这些分发 是为了介绍和理解的方便,部分自动评测模型也会涉及到多个子类里面、各个 子类也有时候会交叉,比如我们自己开发的 LEPOR、hLEPOR、和 nLEPOR 方法 [71, 74],将会在下文提到。
在元评测这一节,我们介绍针对评测方法的评测。这包括统计学重要性(也叫 显著性差异, statistical significance),评价一致性 (agreement level),和评测 结果的相关系性数,以及对不同评测指标(metric)的相互比较等。
首先,组合词以及组合词表达 (multiword-expressions, MWEs) 的识别是自然 语言处理的一个重要任务,组合词表达包含很多不同类别的词语组合并且涵 盖比喻、言语、成语等成分,在机器翻译、自然语言处理 (NLP) 和评测任务 扮演着非常重要的角色 [135, 110, 121, 132, 77]。
这反映在历年的国际 MWE 研讨会和近几年该研讨会组织的 MWE 识别任务 [112, 111, 137]。因此,在此 方面与机器翻译领域的两个未来研究方向包括:1)组合词表达的识别模型和 翻译模型的结合;2)组合词表达在机器翻译评测里的应用。
针对 1),目前在深度学习领域已有对 MWE 的可解析性 (decompositionality) 和可侦测性 (identification) 的前沿进展,比如 [64] 用神经网络对名词构 成词的语义结构研究,如何建立综合的神经网络模型 (hybrid neural networks) 将 MWE 构词和解析研究与神经机器翻译两个目前分开的神经学习模型结合 起来,是一个非常可行的研究课题 (讨论见 [78]),并且这种结合的模型训练将 有助于系统的总体优化,比如使用机器学习里现有的先进的神经网络高等参 数优化框架模型 (hyper-parameter optimisation framework, Optuna)[1]。
针对 2),如何改进目前的广泛使用又饱受批评的流行评测方法(如 BLEU),设计 新的评测模型,将语义评测合理囊括进评测系统里,这是一个很有挑战性的课 题。而由于众多 MWE 子类对语义的涉及(比如言语、成语、习语),其在翻 译评测过程扮演了一个很重要的角色。这既可以是障碍(如歧义)、也可以是 助手。因此如何积极利用这一角色,发挥其优势是一个非常可行的研究方向, 这包含相应的多语种对齐语料建设、人工标注、神经网络建模、和模型测试。
其次,篇章级别(context-aware)的机器翻译评测是未来发展趋势之一。目 前的评测方法,大都关注于句子级别的内容。
但是,从语言学角度观察,一个 句子所在的环境(篇章背景)对本句子的理解起到至关重要的作用,尤其是含 有指代词、和歧义词的情况,如何更精确的去翻译和评价翻译的好坏,需要对 句子背后的信息有足够的认知掌握 [77]。这个研究方向在深度学习模型、以及 相应的神经语言模型出现后变得非常可行。比如,目前成熟的深度学习模型可 以不止对句子级别进行词到向量的转化,并且还可以对跨句子和篇章级别的 内容进行向量转化 (sentences/paragraphs to vectors), 这样,对文本和背景知 识的学习可以嵌入到评测系统里,作为模型学习的特征。
再次,基于具体任务 (task-oriented) 的翻译评测在机器翻译的大流行下 变得越来越紧迫需要 [54],比如旅馆预定的机器翻译,由于该领域句子偏短 并且多附有表格填写,会更侧重于命名实体的翻译准确性如地名、机构名、 人名(尤其外语人名的翻译)等;
再比如目前刚开始流行的多模态机器翻译(multi-modal MT) 包括多模态图片标题生成和翻译(image captioning MT) 任务,这样的情况下对多模态 (image+text) 资源的利用变得非常必要。最后,无参考译文的机器翻译质量估计(QE)是研究的一个重点 [145, 67]。由于在某些情境下参考译文的缺失,比如地震灾害等情况下需要对当地语言 进行多语种翻译以提高营救效果,无参考译文的质量估计模型更加的适用于 现实的需求。这在 WMT 的历史机器翻译任务里有出现过。在其他情况,当参 考译文的获得非常昂贵或者不实际时,没有参考译文的翻译质量信心估计也 是一个挑战性的问题,比如现有的在线翻译平台软件,很少有在提供用户自动 翻译译文的同时提供翻译质量估计水平 (confidence estimation)。在未来机器 翻译和评测的发展中,如何将翻译和质量估计同时提供给使用者是一个难题。这涉及到翻译模型和质量估计模型的同步学习训练。
此文主在介绍机器翻译评测的发展,内容覆盖人工评价模型、自动评价模型、 元评测(评价模型的评价)、以及对此方向的未来发展研究展望。在人工评价 和自动评价模型分块分别简要介绍了历史性的方法和前沿的进展,这包含人 工评价里对 crowd-source 的应用以及自动评价里对当前的深度学习和预训练 模型的运用。在元评测部分我们探讨了统计学中显著性差异、可信度等在评 价里的应用、以及不同的相关性系数比较。由于机器翻译属于自然语言处理 (NLP)的一个大的分支,涉及到自然语言理解 (NLU) 和自然语言生成 (NLG) 的其他不同子分支,我们希望这份综合性评测报告也会有利于其他 NLP 相 关研究领域的推进、尤其在评测和质量估计建模方面,比如这包括摘要生 成 (summarization) 的评测、图像标题生成 (image captioning) 的评测、释义 (paraphrase) 和蕴含 (entailment) 的评测、信息提取 (information extraction) 的评测、代码生成 (code generation) 的评测等。
专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
请扫码加入专知人工智能群(长按二维码),或者加专知小助手微信(zhuanzhi02),加入专知主题群(请备注主题类型:AI、NLP、CV、 KG、论文等)交流~
![]()
专知,专业可信的人工智能知识分发
,让认知协作更快更好!欢迎注册登录专知www.zhuanzhi.ai,获取70000+AI主题干货知识资料!
欢迎微信扫一扫加入专知人工智能知识星球群,获取最新AI专业干货知识教程资料和与专家交流咨询!
点击“
阅读原文
”,了解使用
专知
,查看获取70000+AI主题知识资源