实现大规模图计算的算法思路


分享嘉宾:徐潇然 Hulu 研究员
编辑整理:莫高鼎
出品平台:DataFunTalk
导读:2017年我以深度学习研究员的身份加入Hulu,研究领域包括了图神经网络及NLP中的知识图谱推理,其中我们在大规模图神经网络计算方向的工作发表在ICLR2020主会上,题目是——Dynamically Pruned Message Passing Networks for Large-Scale Knowledge Graph Reasoning。本次分享的话题会沿着这个方向,重点和大家探讨一下并列出一些可以降低大规模图计算复杂度的思路。
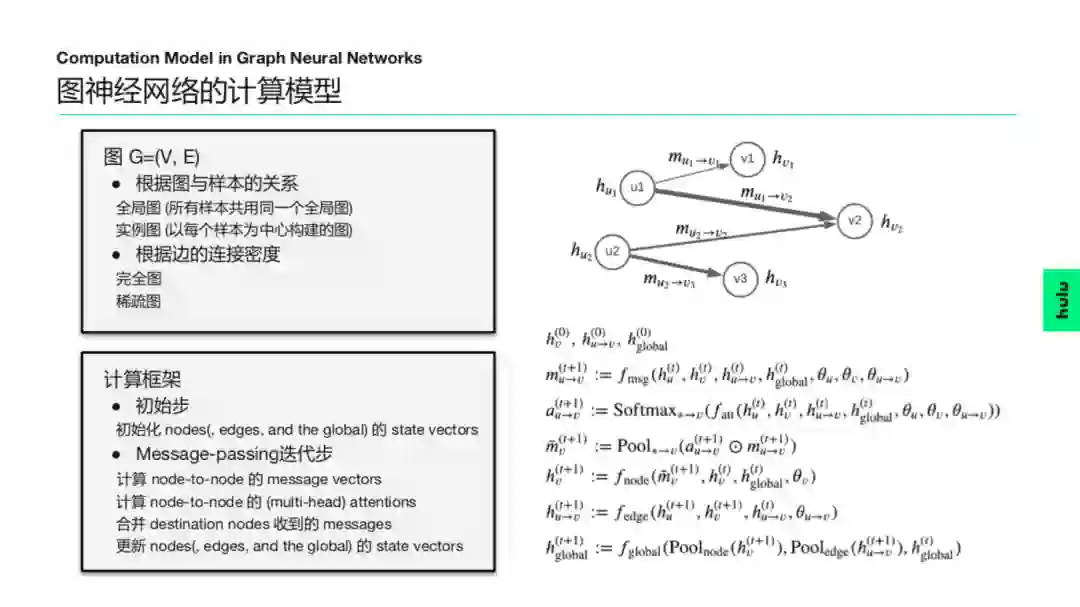
1. 图神经网络使用的图
图神经网络这几年特别火爆,无论学术界还是业界,大家都在考虑用图神经网络。正因为图神经网络的应用面很广,所用的图各种各样都有,简单分类如下:
① 根据图与样本的关系
全局图:所有样本共用一个大图
比如有一个大而全的知识图谱,所做任务的每一个样本都共用这个知识图谱,使用来自这个知识图谱的一部分信息。
实例图:以每个样本为中心构建的图
每个输入的样本自带一个图,比如要考虑一张图片中所有物体之间的关系,这可以构成一个物体间关系图。换一张图片后,就是另一张关系图。
② 根据边的连接密度
完全图
稀疏图
2. 图神经网络与传统神经网络的联系
神经网络原本就是图,我们大多只是提到“权重”和“层”,再细粒度一点,会讲到“单元”(即units)。但是,有图就有节点和边的概念,就看你怎么定义这个节点。在BERT网络结构中,输入是一个文本序列, 预处理成一串代表word或sub-word的tokens,我们可以把这些tokens看成是图中的nodes,这样BERT变成了一个完全图上的图神经网络,而且BERT网络结构的每层可以对应到图神经网络的一次message passing迭代。
3. 图神经网络与传统神经网络的区别
传统神经网络有多个层的概念,每一层用的都是不同的参数;图神经网络只有一个图,图中计算通过多步迭代完成节点间的消息传递和节点状态更新。这种迭代式的计算,有点类似神经网络的多个层,但是迭代中使用的是同一套权重参数,这点又像单层的RNN。当然,如果不嫌复杂,你可以堆叠多个图,下层图向上层图提供输入,让图神经网络有“层”的概念。
另外,图神经网络中的nodes与传统神经网络中的units不同。图神经网络中的nodes是有状态的(stateful),不像传统神经网络中的units,当一层计算完输出给下一层后,这层units的生命就结束了。Nodes的状态表示为一个向量,在下次迭代时会更新。此外,你也可以考虑为edges和global定义它们的状态。
4. 图神经网络的计算框架
① 初始步
初始化每个节点的状态向量(可以包括各条边和全局的状态)
② 消息传递(message-passing)迭代步:
计算节点到节点的消息向量
计算节点到节点的(多头)注意力分布
对节点收到的消息进行汇总计算
更新每个节点的状态向量(可以包括各条边和全局的状态)
5. 图神经网络的计算复杂度

计算复杂度主要分为空间复杂度和时间复杂度。我们使用PyTorch或者TensorFlow进行神经网络训练或预测时,会遇到各种具体的复杂度,比如会有模型参数规模的复杂度,还有计算中产生中间tensors大小的复杂度,以及一次前向计算中需保存tensors个数的复杂度。我们训练神经网络时,它做前向计算的过程中,由于梯度反向传播的需要,前面层计算出的中间tensors要保留。但在预测阶段,不需要梯度反向传播,可以不保留中间产生的tensors,这会大大降低空间上的开销。物理层面,我们现在用的GPU,一张卡的显存顶到天也就24G,这个尺寸还是有限的,但是实际中遇到的很多图都非常之大。另外,就是时间复杂度了。下面,我们用T表示一次图计算中的迭代个数,B表示输入样本的批大小(batch size),|V|表示节点个数,|E|表示边个数,D,D1,D2表示表征向量的维数。
空间复杂度
模型参数规模
计算中间产生tensors规模(此时有B>=1, T=1)
计算中间保留tensors规模(此时有B>=1, T>=1)
时间复杂度
计算所需浮点数规模(此时考虑D1, D2)
总结复杂度的计算公式,不外乎如下的形式:
思路一:避开|E|
通常情况下,图中边的个数远大于节点的数量。极端情况下,当边的密度很高直至完全图时,图的复杂度可以达到|V|(|V|-1)/2。如果考虑两个节点间双向的边,以及节点到自身的特殊边,那么这个复杂度就是|V|2。为了降低计算的复杂度,一个思路就是尽量避开围绕边的计算。具体来说,为了让计算复杂度从|E|级别降低为|V|级别,在计算消息向量(message vectors)时,我们仅计算 destination-independent messages。也就是说,从节点u发出的所有消息使用同一个向量,这样复杂度从边数级别降为了节点数级别。值得注意的是,这里会存在一个问题,消息向量里不区分不同的destination节点。那么,能否把不同的destination节点考虑进来呢?当然可以,不过需要引入multi-head attention机制。下面针对这种情况来介绍一下优化方案。
适合情形
当|E|>>|V|时,即边密度高的图,尤其是完全图
优化方案

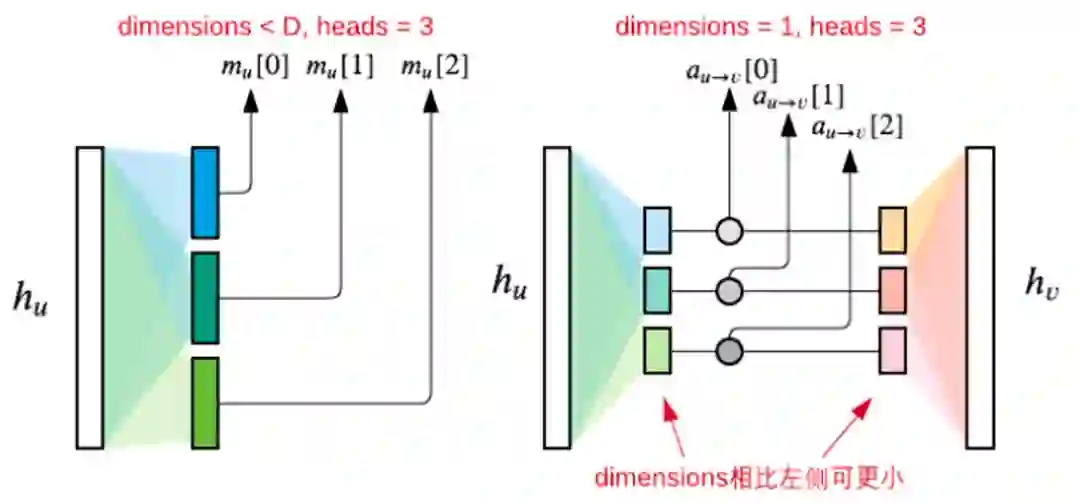
思路二:减少D
顺着思路一,我们在计算attention时,每个attention分数都是一个标量。我们可以减小计算attention所用的向量维数,因为输出是一个标量,信息被压缩到一维空间,所以计算时没必要使用大向量来提高capacity。如果需要multi-head的话,可以把每个计算channel的向量维数变小,让它们加起来还等于原来的总维数。这个思路很像BERT,BERT虽然不是GNN,但是这种机制可以运用到GNN中。还有一篇论文,提出了Graph Attention Networks,也用到了类似的思路。
适合情形
引入attention mechanism的multi-head channels设计
优化方案
每个head channel 的消息计算使用较小的hidden dimensions, 通过增加head的数量来保证模型的capacity,而每个head的attention 分数在一个节点上仅仅是一个标量。
思路三:部分迭代更新(选择性减少T)
前面的思路是减少边数量以及计算维度数,我们还可以减少迭代次数T,这样中间需保留tensors的规模就会变小,适合非常大的网络,尤其当网络节点刻画的时间跨度很大,或者异构网络的不同节点需要不同频次或不同阶段下的更新。有些节点不需要迭代更新那么多次,迭代两、三次就够了,有些节点要更新好多次才行。下图的右侧部分,每步迭代节点都更新;左侧部分,节点只更新一次,即使这样,它的计算依赖链条还是有四层。至于更新策略,可以人为设定,比如说,采取随机抽样方式,或者通过学习得到哪些节点需更新的更新策略。更新策略的数学实现,可以采取hard gate的方式(注意不是soft),也可以采取sparse attention即选择top-K节点的方式。有paper基于损失函数设计criteria去选择更新的节点,如果某个节点的当前输出对最终损失函数的贡献已经很好了,就不再更新。需要注意的是,在hard gate和sparse attention的代码实现中,不能简单地把要略过的节点的权重置零,虽然数学上等价,但是CPU或GPU还是要计算的,所以代码中需要实现稀疏性计算,来减少每次更新所载入的tensor规模。更新的粒度可以是逐点的,也可以是逐块的。
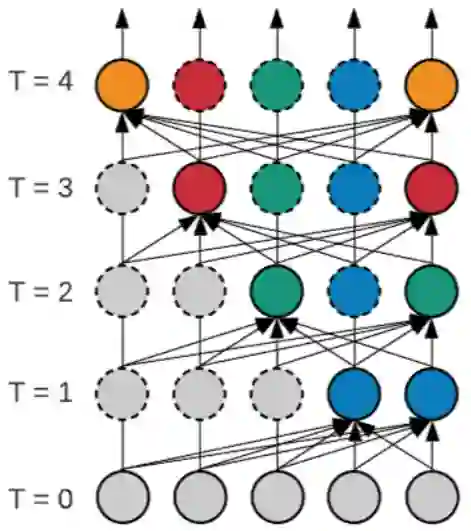
适合情形
具有大时间跨度或异构的网络,其节点需不同频次或不同阶段下的更新
优化方案
更新策略一:预先设定每步更新节点
更新策略二:随机抽样每步更新节点
更新策略三:每步每节点通过hard gate的开关决定是否更新
更新策略四:每步通过sparse attention机制选择top-K节点进行更新
更新策略五:根据设定的criteria选择更新节点(如:非shortcut支路上梯度趋零)
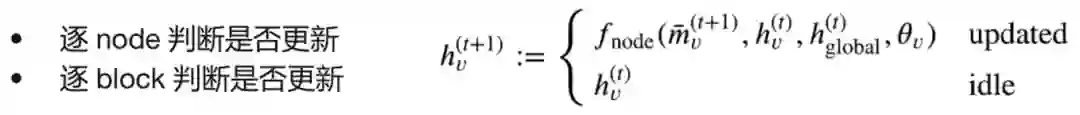
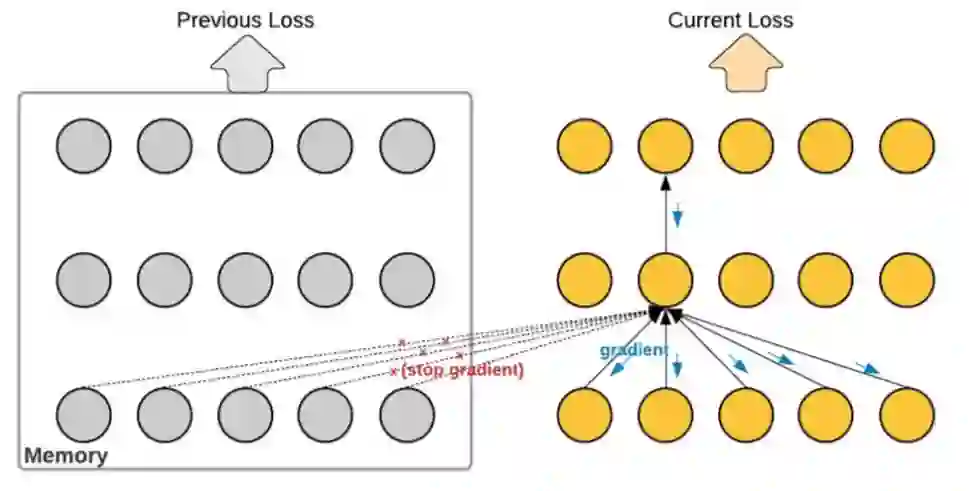
思路四:Baking(“烘焙”,即使用临时memory存放某些计算结果)
Baking这个名字,是我引用计算机3D游戏设计中的一个名词,来对深度学习中一种常见的技巧起的名字。当某些数据的计算复杂度很高时,我们可以提前算好它,后面需要时就直接拿来。这些数据通常需要一个临时的记忆模块来存储。大时间跨度的早期计算节点,或者异构网络的一些非重要节点,我们假定它们对当前计算的作用只是参考性的、非决定性的,并设计它们只参与前向计算,不参与梯度的反向传播,此时我们可以使用记忆模块保存这些算好的数据。记忆模块的设计,最简单的就是一组向量,每个向量为一个记忆槽(slot),访问过程可以是严格的索引匹配,或者采用soft attention机制。
适合情形
大时间跨度的早期计算节点或者异构网络的一些非重要节点(只参与前向计算,不参与梯度的反向传播)。
优化方案
维护一个记忆缓存,保存历史计算的某些节点状态向量,对缓存的访问可以是严格索引匹配,也可以使用soft attention机制。
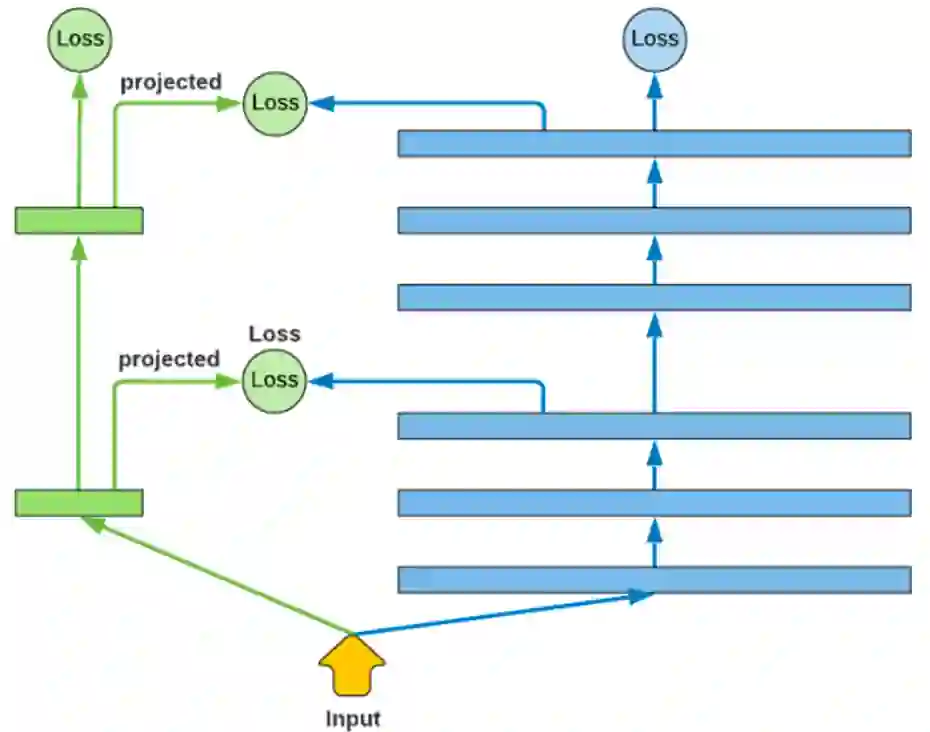
思路五:Distillation(蒸馏技术)
蒸馏技术的应用非常普遍。蒸馏的思想就是用层数更小的网络来代替较重的大型网络。实际上,所有神经网络的蒸馏思路都类似,只不过在图神经网络里,要考虑如何把一个重型网络压缩成小网络的具体细节,包括要增加什么样的loss来训练。这里,要明白蒸馏的目的不是仅仅为了学习到一个小网络,而是要让学习出的小网络可以很好地反映所给的重型网络。小网络相当于重型网络在低维空间的一个投影。实际上,用一个小的参数空间去锚定重型网络的中间层features,基于hidden层或者attention层做对齐,尽量让小网络在某些中间层上产生与重型网络相对接近的features。
适合情形
对已训练好的重型网络进行维度压缩、层压缩或稀疏性压缩,让中间层的feature space表达更紧凑。
优化方案
Distillation Loss的设计方案:
Hidden-based loss
Attention-based loss
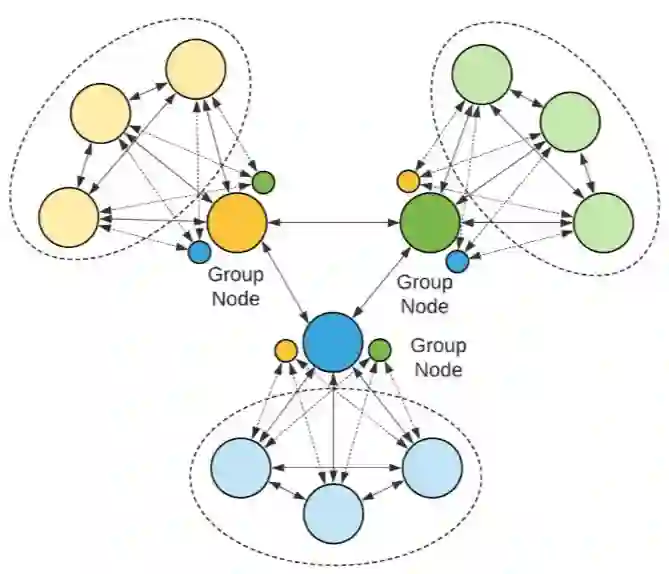
思路六:Partition (or clustering)
如果图非常非常大,那该怎么办?只能采取图分割(graph partition)的方法了。我们可以借用传统的图分割或节点聚类算法,但是这些算法大多很耗时,故不能采取过于复杂的图分割或节点聚类算法。分割过程要注意执行分割算法所用的节点数据,最好不要直接在节点hidden features上做分割或聚类计算,这是因为只有hidden features相似的nodes才会聚到一起,可能存在某些相关但hidden features不接近的节点需要放在一个组里。我们可以将hidden features做非线性转换到某个分割语义下的空间,这个非线性转换是带参的,需要训练,即分割或聚类过程是学习得到的。每个分割后的组,组内直接进行节点到节点的消息传递,组间消息传递时先对一组节点做池化(pooling)计算,得到一个反映整个组的状态向量,再通过这个向量与其他组的节点做消息传递。另外的关键一点是如何通过最终的损失函数来训练分割或聚类计算中的可训参数。我们可以把节点对组的成员关系(membership)引入到计算流程中,使得反向传播时可以获得相应的梯度信息。当然,如果不想这么复杂,你可以提前对图做分割, 然后进行消息传递。
适合情形
针对非常大的图(尤其是完全图)
优化方案
对图做快速分割处理,划分节点成组,然后在组内进行节点到节点的消息传递,在组间进行组到节点、或组到组的消息传递。
① Transformation step
Project hidden features onto the partition-oriented space
② Partitioning step
③ Group-pooling step
Compute group node states
④ Message-passing step
Compute messages from within-group neighbors
Compute messages from the current group node
Compute messages from other group nodes
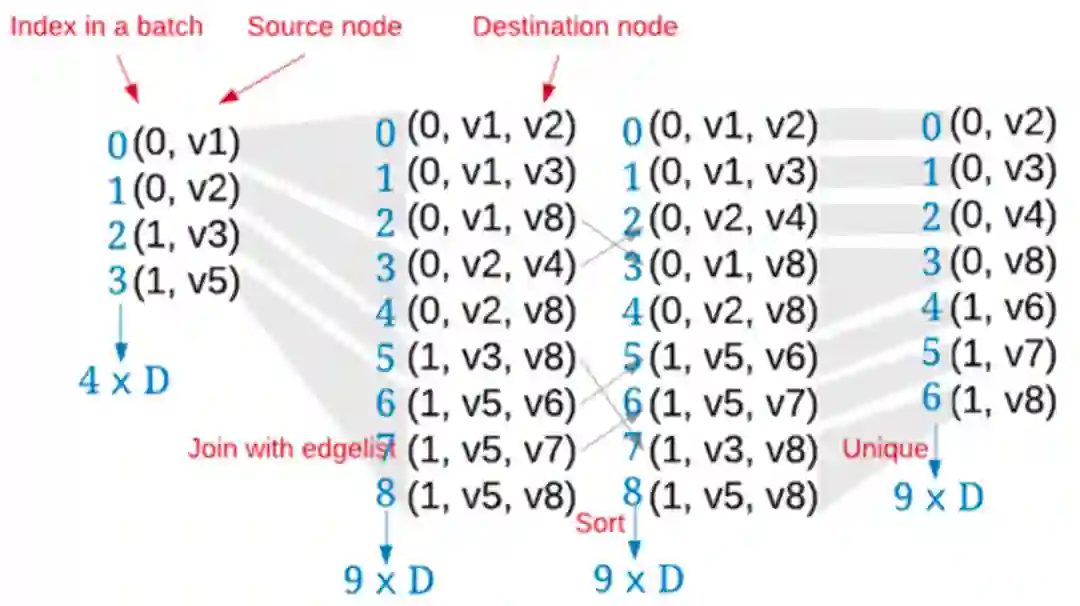
思路七:稀疏图计算
如何利用好稀疏图把复杂度降下来?你不能把稀疏图当作dense矩阵来处理,并用Tensorflow或PyTorch做普通tensors间的计算,这是没有效果的。你必须维护一个索引列表,而且这个索引列表支持快速的sort、unique、join等操作。举个例子,你需要维护一份索引列表如下图,第一列代表batch中每个sample的index,第二列代表source node的id。当用节点状态向量计算消息向量时, 需要此索引列表与边列表edgelist做join,把destination node的id引进来,完成节点状态向量到边向量的转换,然后你可以在边向量上做一些计算,如经过一两层的小神经网络,得到边上的消息向量。得到消息向量后,对destination node做sort和unique操作。联想稀疏矩阵的乘法计算,类似上述的过程,可以分成两步,第一步是在非零元素上进行element-wise乘操作,第二步是在列上做加操作。
适合情形
当|E|<<|v|*|v|时
优化方案
稀疏计算的关键在于维护一个索引列表,能快速进行sort、unique、join操作并调用如下深度学习库函数:
TensorFlow:
- gather, gather_ndm
- scatter_nd, segment_sum,
- segment_max, unsored_segment_sum|max
Pytorch:
思路八:稀疏routing
稀疏routing与partition不同,partition需要将整个图都考虑进来,而稀疏routing只需考虑大图中所用到的局部子图。单个样本每次计算时,只需要用到大图的一个局部子图,刚开始的子图可能仅是一个节点或几个节点,即聚焦在一个很小的区域,计算过程中聚焦区域逐渐扩大。这种routing的方式也是一种attention机制,与传统的attention机制有所不同。传统的attention用于汇总各方来的消息向量,采用加权平均的方式,让incoming消息的权重相加等于1;对于routing的话,刚好相反,让outgoing的边权重和为1,这个有点类似PageRank算法。这样做的好处,可以在计算过程中通过选取top-K的outgoing边来构建一个动态剪枝的子图。
适合情形
全图虽大,但每次仅用到局部子图
优化方案
Attention机制是“拉”的模式,routing机制是“推”的模式。
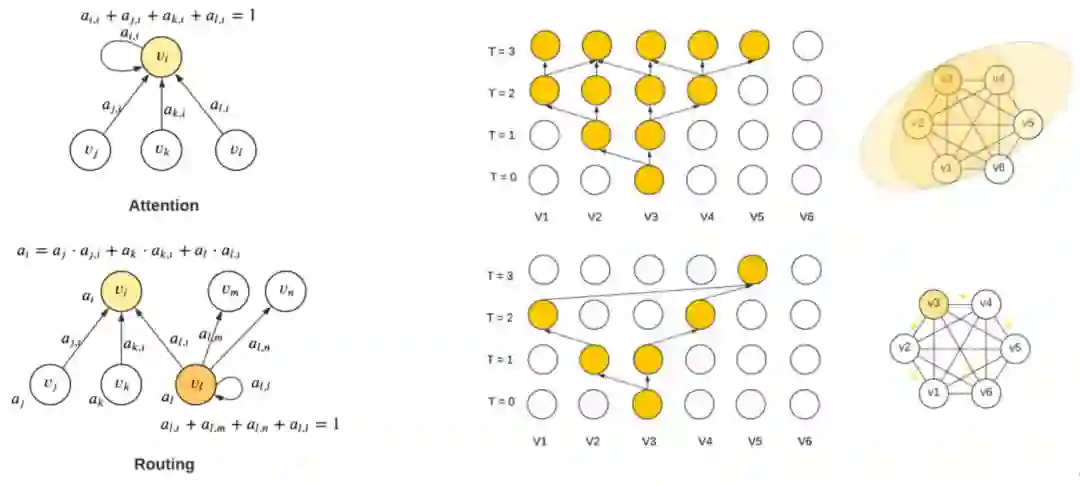
思路九:跨样本共享的图特征
当你计算的图特征(如节点向量)不依赖具体样本时,这些特征可以作为输入喂给每个样本,但是它们的大小不随batch size的大小而增加。我们称这些是input-agnostic features,由于跨样本共享,它们相当于batch size为1的输入。
适合情形
提供input-agnostic features
优化方案
跨样本共享,相当于batch size为1。
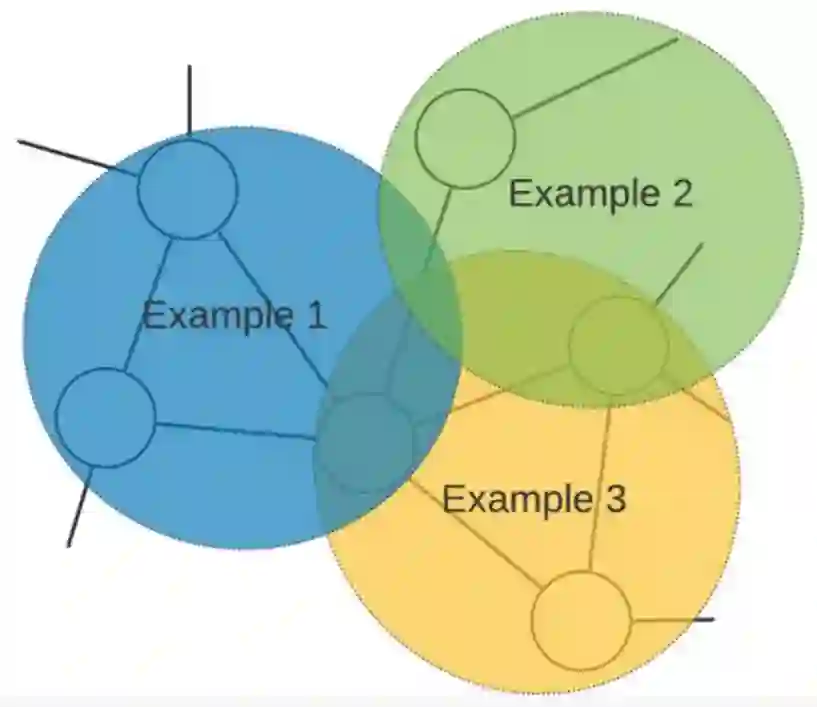
思路十:组合使用以上九种方法
组合使用以上九种方法,根据自己的实际情况设计适当的算法。
今天的分享就到这里,谢谢大家。
在文末分享、点赞、在看,给个3连击呗~

徐潇然
Hulu | 研究员
专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“TAST” 可以获取《【ICLR2021】对未标记数据进行深度网络自训练的理论分析》专知下载链接索引







