干货分享 | 云脑科技核心算法工程师详解时间序列(附PPT)
云脑科技机器学习训练营以讲解时间序列收尾,详细解说了时间序列的传统模型、进阶模型、神经网络模型,量子位作为合作媒体为大家带来本期干货整理。
内容简介
主讲人:徐昊(云脑科技核心算法工程师)

云脑科技核心算法工程师,高性能计算专家。在高性能分布式计算、图计算、随机优化领域有着十余年研发经验,发表IEEE/ACM顶级论文20余篇,曾获第八届国际低能耗电子器件会议唯一最佳论文奖,曾任ANSYS软件研发经理、首席工程师。
内容要点:
技术挑战
基本模型
进阶模型
深度神经网络模型
重点讲神经网络模型(RNN 、LSTM等),传统模型简单的提一下。
时间序列的应用

你可以认为世界上发生的每一件事都是一个时间序列的一部分,时间序列的应用可以很广泛,目前时间序列有一些应用:股票预测、自然语言处理模型:因为语言本身就可以看作一个序列,如 can you pleace come here? 说了前四个字,让你预测最后一个字。预测视频:给你一帧,让你预测下一个动作。PPT Slides:提供前一个Slides,预测下一个Slides讲什么?这个预测比较复杂,存在逻辑上的连贯性。大家可以看出时间序列的预测有各种各样的形式,有可能是比较困难的。
时间序列预测
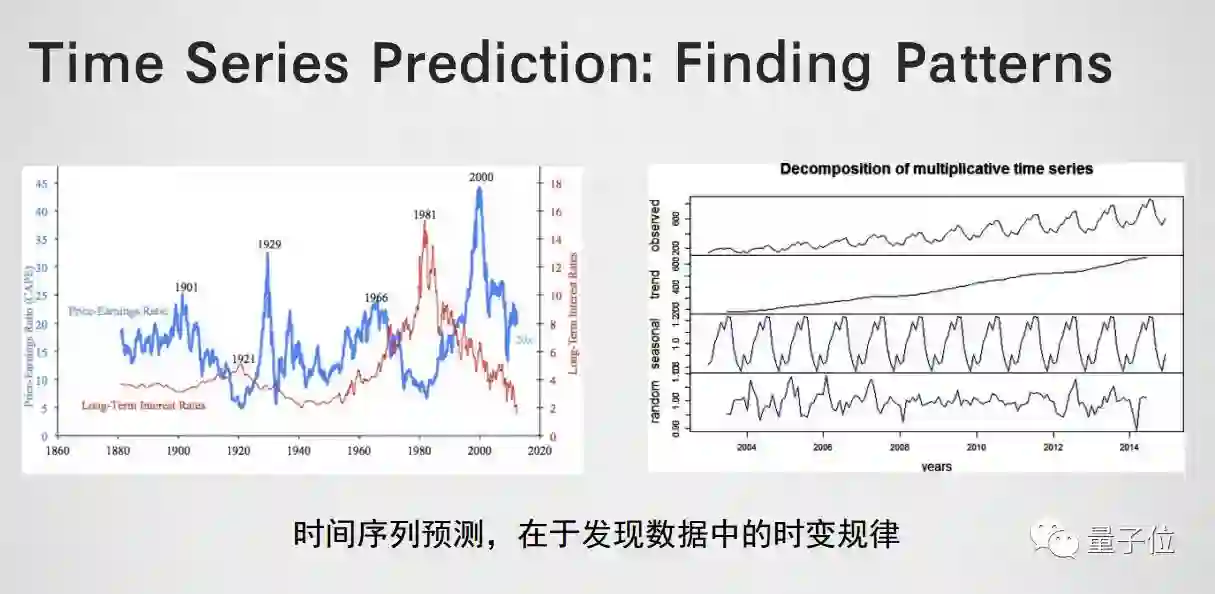
时间序列预测需要做些什么?主要是在数据中发现时变的规律。左图有两个随机性比较强的时间序列,我们如何从中发现规律,可以使用右边的图来演示。第一个是观测,可以把它演变成趋势,它还包括周期性的信号,最后还有一些随机的因素,后面三部分(趋势、周期、随机)合起来构成了最上方的信号。
时间序列预测任务是发现数据的时变规律,在不同的抽象层次。如:钟表有12-hour cycle,hour cycle,还有minute cycle, 他在不同层次上,由时针、分针、秒针的位置产生的时间序列,我们需要学习三个层次的规律。、
技术挑战

举个例子:视频预测中有两帧图,在图像识别中,假设每一帧里面有M个像素,图像识别的任务就是从M的像素中找到规律。如果要预测,从第一帧(M个)到第二帧(M个),学习空间就维度有MM个。如果要更准确一点,用前面N帧来预测下一帧,就有(MN)M 大的空间。如果之前每一帧都有一个输入X,那么这个学习空间将十分大(M(N+X)*M)。大家可以看到M个像素的图像识别任务,放到时间序列中将十分复杂,很难去学。所以时间序列学习的挑战还是比较多的:
非线性
高维度导致十分大
寻找的规律是有层次的
模型分析
传统模型的一个代表是ARIMA模型,它的用途十分广泛,尤其是社会现象的应用,如库存量预测,销售量预测。ARIMA分为三个部分:AR:Auto regressive 、MA:Moving Average、 I:Integration filter。
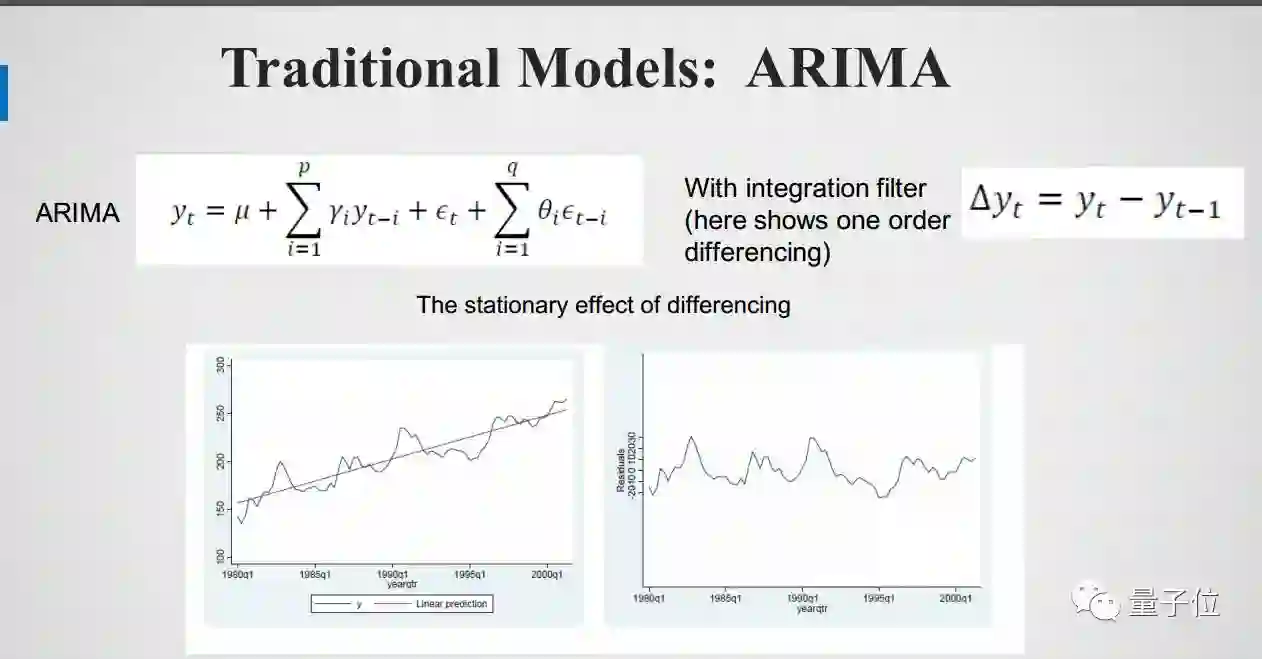
Auto regressive 数学公式中第一项是常量,最后一项是随机噪声,中间一项是说当前yt由之前t-1个y乘系数γ所决定的,找到前面i个时间点的值,乘以系数再相加。不同的γ可以产生不同的时间序列。
Moving Average 也是由常量均值、随机量以及用过去i个点残差值学一个模型。将这两部分合起来就得到一个复杂一些的模型,这个复杂的模型就能产生更复杂一点的时间序列,换句话讲就可以用这个模型学习一个更复杂的时间序列。
Integration filter 核心是将ARMA模型中的y换成 Δy,也就是difference的项。这个的好处是:一个时间序要学趋势、学周期再去学随机量就比较复杂,怎么简化这个过程呢?只要做个一阶的difference ,去学 Δy , 实际上是去掉了趋势因素。所以大家可以注意,处理时间序列经常用的方法的是:不去预测y,去预测 Δy。 从术语上说,把序列做了一个stationary。
Hidden Markov Model
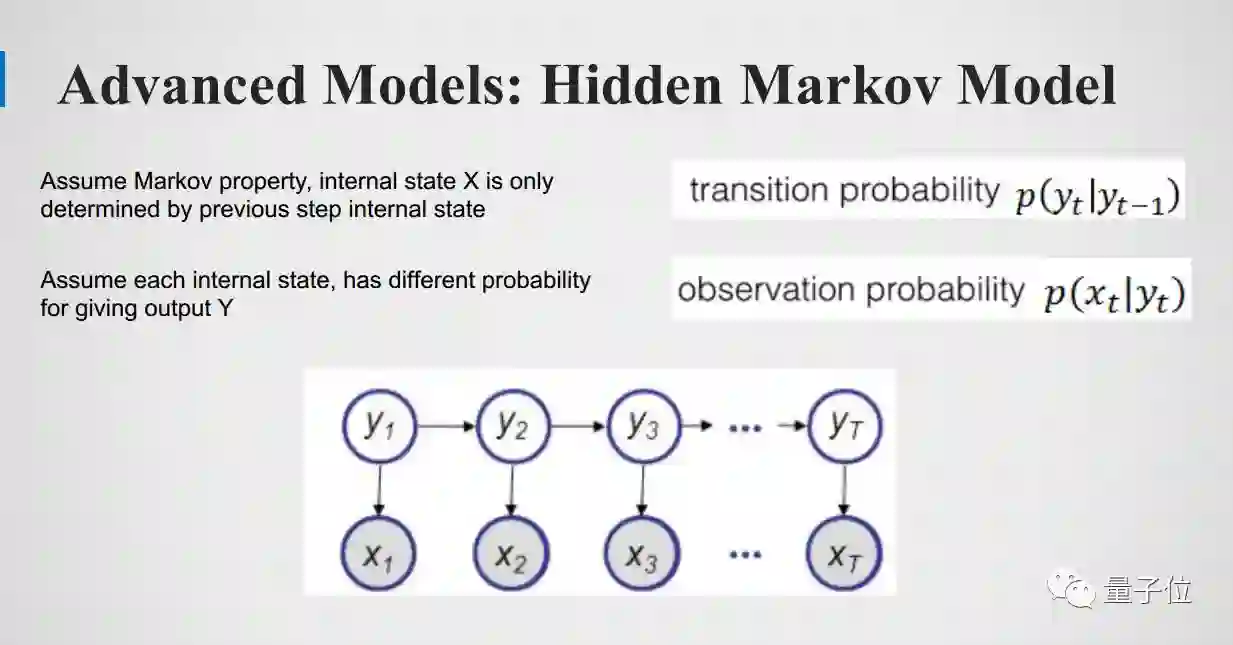
在神经网络之前,语音识别用的都是Hidden Markov Model(HMM)。观测到X1到Xt,y1到yt是隐藏的内部状态。模型有两个假设:第一个假设 Markov property:internal state 只由前一个状态决定,所以只走一步。
第二个假设是当前的观测值只由当前的隐藏状态决定。它其实把时间序列的预测分为很多小部分,也是约束性很强的一个模型。模型虽然很简单,但是十分有效,因为自然界很多事物都遵循马尔科夫假设。
stationary是指系统经过一系列的变化又回到了原点。如果有趋势项,很可能就回不到原点,做了difference 之后就去掉趋势因素。
Chain Conditional Random Field
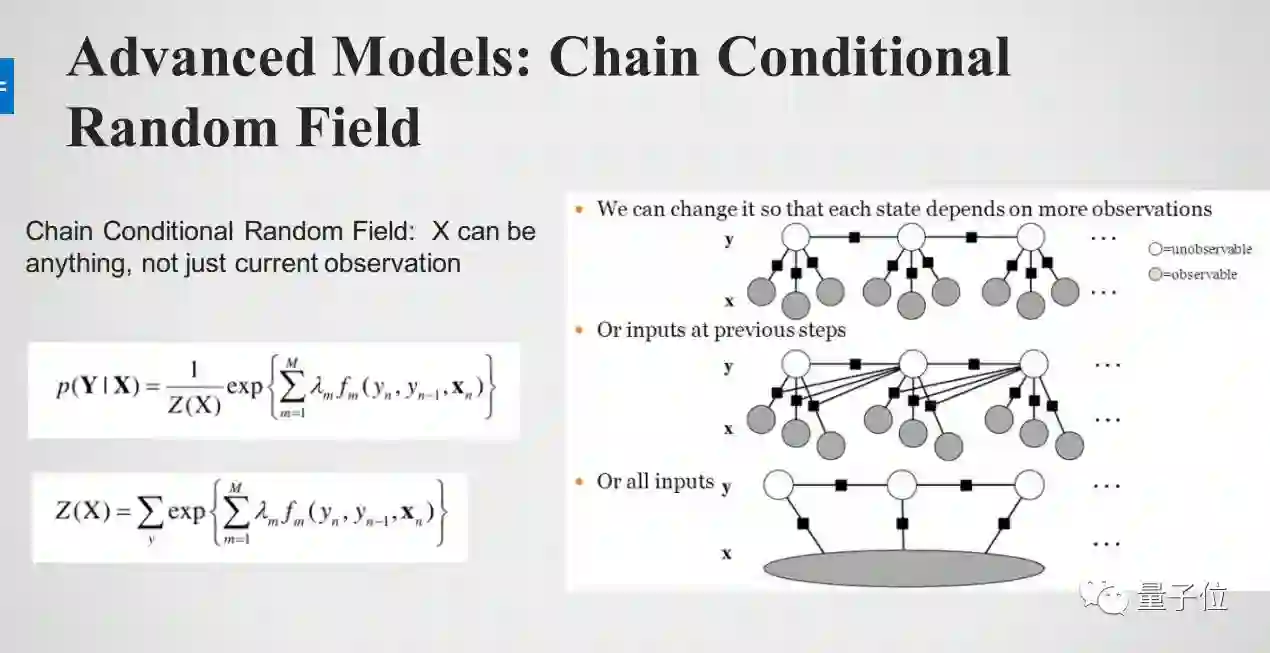
CRF的主要改进是,当前的internal state,不仅仅与当前的观测值有关,也与之前的观测值有关。所以这个网络的假设没有那么强。下面三个都是CRF网络,只是假设强度不一样。
例如中间的网络,每个时间点的internal state,与当前,与前一个时间点的观测值都相关,这个网络就更复杂了。最下面一种是与所有的观测量都有关系,假设更弱了,所以它的表达能力是最强的,但是也是很难学的。
CRF模型实际上是约束最少的,有的假设在HM模型中是不成立的就需要用到CRF,而且很多网络的最后一层是用CRF来做的。
神经网络

先举两个例子,看一下神经网络做时间序列预测是怎么搭的。第一个是一个语言模型,它的核心的神经网络是LSTM——长短记忆网络。如给定一句话:to be or not ,要做的是给你一个词,预测下一个词。这个网络分为三层:Embeding layer 、LSTM Lyaer、Output Layer。
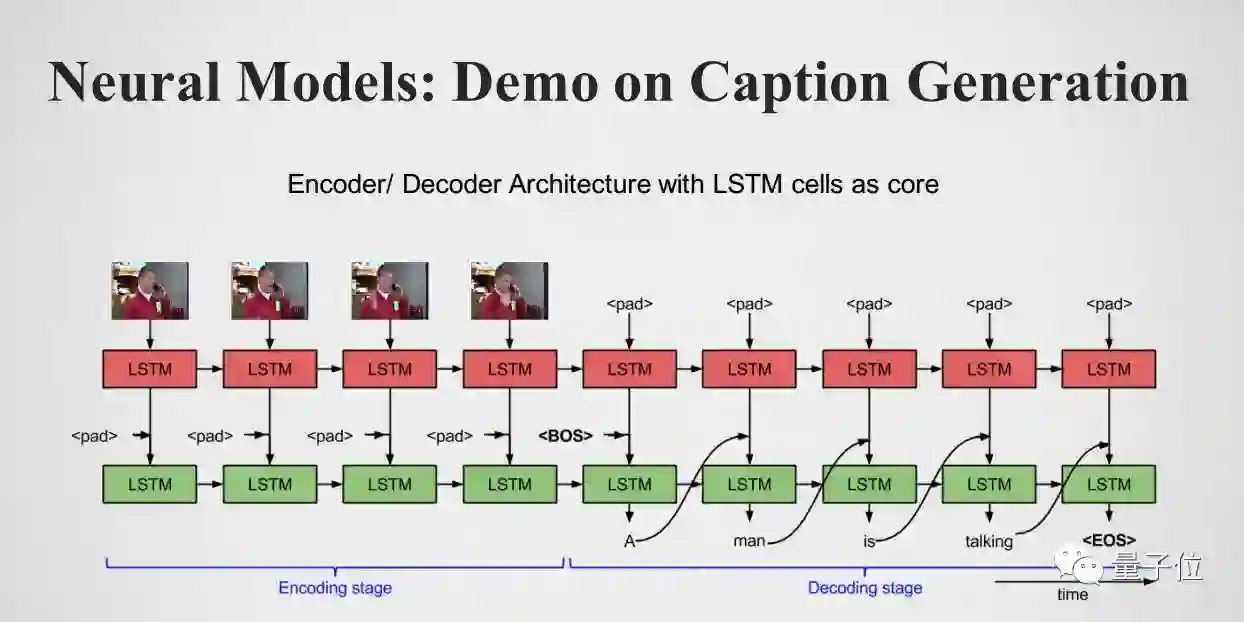
再看一个神经网络的应用,给你一个视频,然后产生字幕、或者描述视频中的人物在做什么,基本的结构叫做Encoder /Decoder Architec。下图中左边是Encoder,Encoder去看你的视频,用LSTM串起来,流到右边是 Decoder,Decoder出来的标签是:A man is talking。
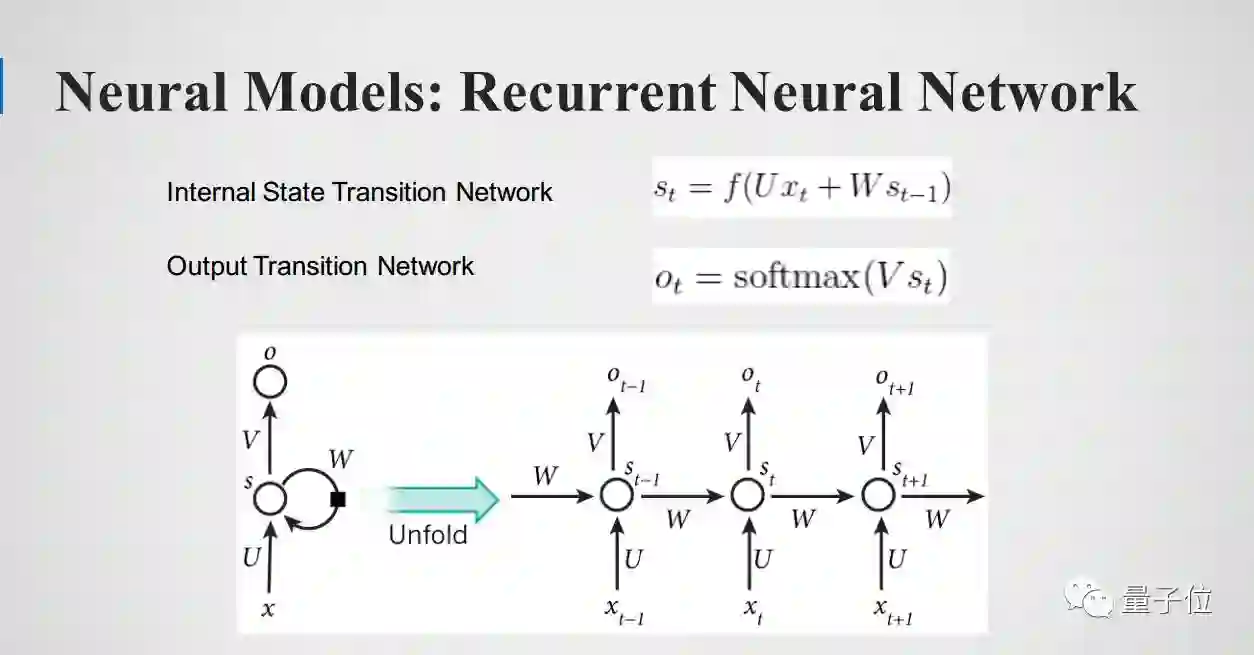
下面看一下神经网络的结构,最基本的 Recurrent Neural Network 。它分为两个部分:1. Intertnal State Transition 2.Output Transition Network 。 Intertnal State Transition 假设他有个内部状态,内部状态是指它自身有一个状态变化的规则,内部状态在某一个状态的时候会产生一个输出,这个输出是由softmax来实现,完全相对于与HMM,HMM是两个Transition matrix , RNN是两个神经网络。
看一下RNN的一个变种——长短记忆网络(LSTM),它把RNN的每一个cell的结构做的更加复杂。RNN内部状态从左边流到右边只有一根线,也就是说只有一个\一组状态会被传到下一步,LSTM实际上是有两根线在传,最上面的一根叫做长期记忆,这条线没有加很多非线性的东西,之前在神经网络上学到的东西在这一步很容易被传到下一步去,这就是长期记忆的一个概念:以前学的东西很容易被记住。有了长期记忆之后会做一个Gate,去控制长期记忆的强度。
另一部分,除了控制长期记忆之外,跟短期记忆有个相加的过程,此外对短期记忆有个非线性的变化,然后与长期记忆相加。即一部分是长期记忆,还有一部分是短期记忆,然后将两部分相结合,结合是根据神经网络里的weight去学的。
这样的结构,给他一个输入,一旦给定一个标签,那么在长期记忆下更重要还是短期记忆更重要,学的过程中会自己去分配。传下去的记忆等于长期记忆乘以遗忘系数,加上新的记忆乘新的记忆scaling factor。最后会有一些Output layer,它也做了非线性的变化。理论上说他分成了两部分,长期记忆和短期记忆。神经网络的实现,就是以上讲的具体的一些公式。
下面我们看一下LSTM。
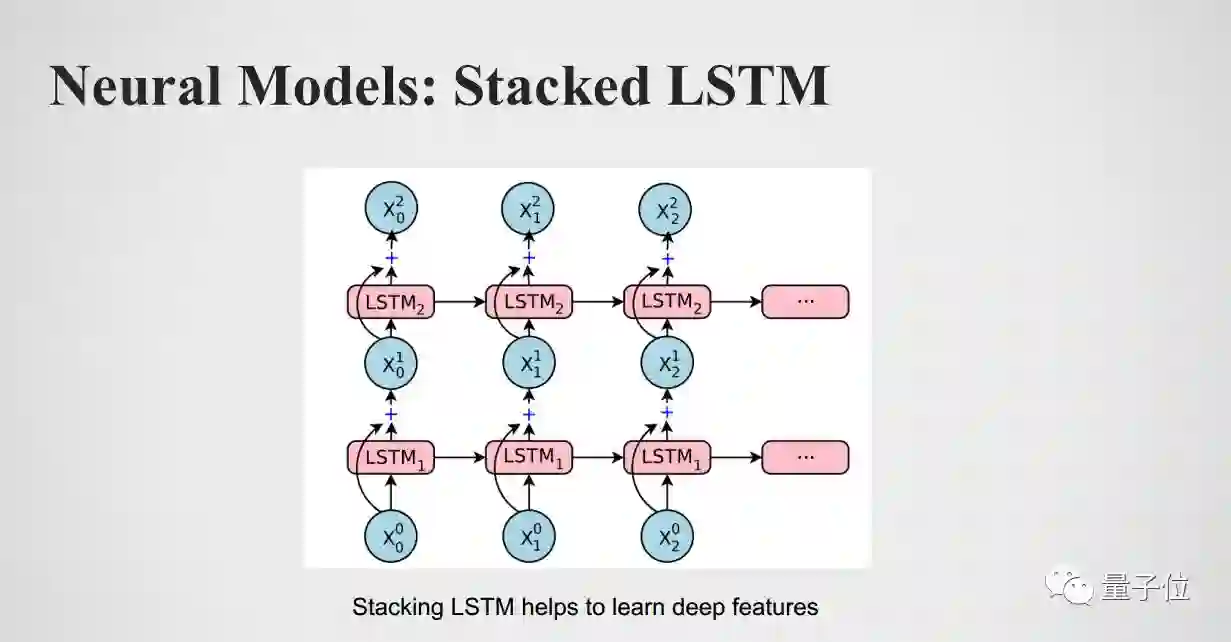
刚才我们看到的是把LSTM 串起来,实际上也可以把它叠加起来。有很多层LSTM,当前层的LSTM 的输出可以做下一层的输入,最后可以做成很大的LSTM 的网络,网络更大就可以学更deep 的feature。
Gated Convolutional Network (GCN)

接下来提一下现在比较流行的模型:Gated Convolutional Network (GCN),也是用在时间序列的学习上。比如说现在有一段文章,sliding window 是10,把十个单词拿出来,然后做embedding,将十个单词的embdding的拼起来,然后在拼起来的sequence上做CNN,图像做出来之后再去做预测。实际上把序列学习的问题转化成CNN可以做的问题。
神经网络模型相对于LSTM还有更多的模型:Gated Recurrent Network,GRN是LSTM 的一个变种。 还有大家可能听说过的Attention Network, 也是LSTM 的一个变种。 Bidirectional LSTM 也就是说在做LSTM时不仅可以从左往右传还可以从右往左传,然后两边传的结果做concate,再来做预测。这样对某些应用还是比较好的,比如说给你一句话:Stacking LSTM helps to learn deep features,把‘helps’去掉让你去填空,如果单一的从左往右是不够的,需要结合两边的信息,从左往右从右往左传都有。
刚才我们介绍了传统模型,进阶模型,神经网络模型。时间序列预测还有很多模型:Support Vector Regression , Gaussian Process ,Tree and Boosting ,Graphical Models。具体用哪一个模型要看具体的应用,要看哪一个模型的假设正好和模型match上。
相关学习资源
以上就是此次课程的相关内容,在量子位微信公众号对话界面回复“171217”,可获得完整版PPT。
— 完 —
活动报名
加入社群
量子位AI社群12群开始招募啦,欢迎对AI感兴趣的同学,加小助手微信qbitbot4入群;
此外,量子位专业细分群(自动驾驶、CV、NLP、机器学习等)正在招募,面向正在从事相关领域的工程师及研究人员。
进群请加小助手微信号qbitbot4,并务必备注相应群的关键词~通过审核后我们将邀请进群。(专业群审核较严,敬请谅解)
诚挚招聘
量子位正在招募编辑/记者,工作地点在北京中关村。期待有才气、有热情的同学加入我们!相关细节,请在量子位公众号(QbitAI)对话界面,回复“招聘”两个字。

量子位 QbitAI · 头条号签约作者
վ'ᴗ' ի 追踪AI技术和产品新动态


