纪光 物联网报告中心
摘要
图计算是基于图数据的分析技术与关系技术应运而生的,图计算系统是针对处理图结
构数据的系统,图计算也是人工智能中的一个使能技术。基于此背景,本研究报告对图计算
这一课题进行了简单梳理,包括以下内容:
图计算的概念与图计算特征。
对图计算的概念进行阐述,对代表性分布式图计算系统进
行介绍,并列出图计算的特征。
图计算技术。
从图计算面临的挑战出发,介绍图算法,图计算模型主要解决的问题,并
图计算框架进行介绍。同时对技术资源和图计算的高引论文进行相关介绍。
图计算领域专家介绍。
依据
AMiner
数据平台信息,对图计算领域研究学者进行梳理,
重点介绍研究学者的研究方向与代表性文章,旨在为学术界、产业界提供图计算技术及学者
的分析依据。对顶尖学者的全球分布、迁徙概况、学者机构分布、
h-index
分析进行介绍。
图计算产业应用。
从医疗行业、金融行业和互联网行业三个方面介绍领域图计算的技术
构建应用与研究现状。
图计算趋势研究。
对图计算的发展趋势特点进行分析。并基于
AMiner
数据平台,对近
期图计算领域研究热点进行可视化分析,与其他学科进行交叉分析研究,对未来图计算研究
1 概述篇
如今,数据已经渗透到每一个行业和业务职能领域,尤其近年来,全球大数据进入加速
发展时期,数据量呈现爆发式增长,大数据吸引了越来越多的关注,大数据时代已然来临。
图计算简单来讲就是研究在这些大量数据中,如何高效计算、存储并管理图数据等问题
的领域。传统的关系型数据暴露出了建模缺陷、水平伸缩等问题,于是具有更强大表达能力
的图数据受到业界极大的重视。如果把关系数据模型比作火车的话,那么现在的图数据建模
可比作高铁。
1.1 大规模图数据时代下的图计算
图(Graph)是一种重要的数据结构,它由节点V(或称为顶点,即个体),与边 E(即个体之间的联系)构成,我们一般将图表示为 G(V,E)。图数据的典型例子有网页链接关系、社交网络、商品推荐等。对应互联网来说,可以把 web 网页看作顶点,页面之间的超链接关系作为边;对应社交网络来说,可以把用户看作顶点,用户之间建立的关系看作边。比如微信的社交网络,是由节点(个人、公众号)和边(关注、点赞)构成的图;淘宝的交易网络,是由节点(个人、商品)和边(购买、收藏)构成的图。
如此一来,抽象出来的图数据便可作为研究和商用的基础,由此探究出“世界上任意两
个人之间的人脉距离”
、“关键意见领袖”等。将这些应用到商业领域,其底层的运算往往是
图相关的算法。比如图的最短路径算法可以做好友推荐,计算关系紧密程度;对图做
PageRank
可以用于传播影响力分析,找出问题的中心,做搜索引擎的网页排名;最小连通图可以识别洗钱或虚假交易等等。
近年来,图数据规模呈指数级增长,可能达到数十亿的顶点和数万亿的边,且还在不断
增长,单机模式下的图计算已经不适合目前数据的增长,传统的分布式大数据处理平台比如
MapReduce
、
Spark
也出现网络和磁盘读写开销大、运算速度慢、处理效率极低的问题
[1]
。
对于图计算而言,性能成本、容错机制以及可拓展性都是非常重要的。如果性能可以显
著提高,结点显著减少,那么就能极大地缩短运行时间。在此基础上,如果使用更大开销的
容错技术,例如检查点的方式,那么故障产生的概率将更低。
但是,传统的大数据分析平台往往只在性能与可拓展性中选择了一方。比如
MPI
、
OpenMP
等注重性能的平台只支持可读写的数据,容错困难,可扩展性差,自动负载不平衡;
专注于拓展性的大数据分析平台,如
MapReduce
、
Spark
等支持只读数据集,容错机制和扩
展性好,自动负载平衡,但性能较低。以
Spark
为例,其基于
Scala
语言,运行在
JVM
上,
内存表示冗余,占用内存大,垃圾收集对性能影响大。在一些迭代的图算法上,开启
128
个
线程的
Spark
程序性能有时候还不如优化很好的单线程程序,并且需要的内存容量是原始数
据集的
20
倍——对于
10TB
级的数据,往往需要数百
TB
的内存,这在绝大部分生产环境
中是不可能的。以
Sogou
的网页链接数据为例,
Sogou
的网页链接数据量为
137TB
,这是很
难使用
Spark
进行计算的。
此外,早期的图计算方法主要局限于智能社区或社交网络分析,如果图计算方案的性能
和容量限制可以克服,图计算可以应用于更广泛的场景,如资本市场风险管理、生命科学研
究、医疗保健交付、监控和应对道路事故、智能基础设施管理和其他领域。
因此,为应对图计算中对高效处理大规模图数据的巨大挑战,可扩展分布式图计算成为
了当前热点研究问题。
自从
2001
年以来,分布式方法就一直是比较热议的处理大图数据的方法,特别是
2003
年和
2004
年,
Google
公布了
MapReduce
的基本原理和主要设计思想,这一模型的推出给
大数据并行处理带来了巨大的革命性影响。此后提出的图处理系统,比如
2006
年发布的
Apache
Hadoop
、
2009
年诞生于加州大学伯克利分校
AMPLab
的
Spark
等,大多基于
MapReduce
的思想,并采用并行
BSP
模型。但是,这些系统与
MapReduce
一样依赖于磁盘, 仍然存在局限性,执行速度慢,处理大型图数据效率较低。
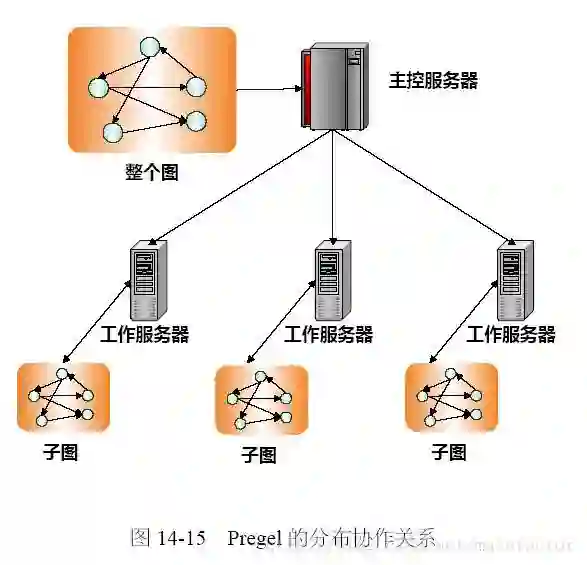
直到
2010
年谷歌推出以顶点为中心的图处理系统
Pregel
,其专为大规模图数据处理而
设计,将图数据保存在主存储器中并采用并行计算的
BSP
模型,因此比
MapReduce
更有效。
此后,对于商用集群和云的图处理系统变得格外受欢迎,并且又出现多个具有不同编程模型
和功能的分布式图处理框架,并被广泛应用以促进大规模图数据的操作,比如
GraphLab
、
Giraph
、
GraphX
、
PowerLyra
、
Gemini
等。这些框架都有自身的优缺点,在技术篇我们将做
详细介绍。
![]()
由于本文着重介绍为应对大规模图数据而提出的分布式图计算,因此对于单机图计算不做过多描述。
对于分布计算的开发和维护需要考虑的情形是复杂多变的。对计算过程中信息的控制、
每个任务的数据获取、对计算结果的合并和对错误计算的回归,在分布式计算的时候都需要
保证正常运行。如果这些任务全部都由开发人员负责,则对程序员的要求是非常高的。分布
式计算框架则能够解决这种瓶颈,通过分布式框架封装计算细节,完成分布式计算程序的开
发。通过使用分布式计算框架,程序员可以很容易享受到分布式计算所带来的高速计算的好
处,而且不必对分布式计算过程中各种问题和计算异常进行控制,这就让程序员的开发效率
成倍地提高。
研究高效处理大规模数据的图计算,能推动社交网络分析、语义
web
分析、生物信息网络分析、自然语言处理等新兴应用领域的发展。
1.1 图计算的特征
初提图计算,很多人会以为这是一种专门进行图像处理的技术。事实上,图计算中的
“图”是针对“图论”而言的,是一种以“图论”为基础的对现实世界的一种“图”结构
的抽象表达,以及在这种数据结构上的计算模式。图数据结构很好的表达了数据之间的关联
性,关联性计算是大数据计算的核心——通过获得数据的关联性,可以从噪音很多的海量数
据中抽取有用的信息。图计算技术解决了传统的计算模式下关联查询的效率低、成本高的问
题,在问题域中对关系进行了完整的刻画,并且具有丰富、高效和敏捷的数据分析能力,其
特征有如下三点。
1) 基于图抽象的数据模型
图计算系统将图结构化数据表示为属性图,它将用户定义的属性与每个顶点和边缘相
关联。属性可以包括元数据
(
例如,用户简档和时间戳
)
和程序状态
(
例如,顶点的
PageRank
或相关的亲和度
)
。源自社交网络和网络图等自然现象的属性图通常具有高度偏斜的幂律度
分布和比顶点更多的边数。
图计算系统中最基础的数据结构由顶点
V
(
或节点
)
、边
E
、权重
D
这三因素组成,即
G=(V
,
E
,
D)
,其中
V
为顶点
(
vertex
),
E
为边
(
edge
),
D
为权重
(
data
)。顶点表示某
一事件中的对象,而边则是对不同对象关系的描述。图计算系统基于顶点和边的方式存储图
数据和计算,能够建构任意复杂的网络和模型,完整且形象地映射分析人员想要研究的问题域。
比如说,对于一个消费者的原始购买行为,有两类节点:用户和产品,边就是购买行为,
权重是边上的一个数据结构,可以是购买次数和最后购买时间。对于许多我们面临的物理世
界的数据问题,都可以利用图结构的来抽象表达:比如社交网络,网页链接关系,用户传播网络,用户网络点击、浏览和购买行为,甚至消费者评论内容,内容分类标签,产品分类标签等。
图计算系统的数据结构很好地表达了数据之间的关联性,关联性计算是大数据计算的核心
——
通过获得数据的关联性,可以从噪音很多的海量数据中抽取有用的信息。比如,通
过为购物者之间的关系建模,就能很快找到口味相似的用户,并为之推荐商品;或者在社交
网络中,通过传播关系发现意见领袖与其操作符
(
例如,连接
)
可以跨越多个集合的数据流
系统相比,图处理系统
(
例如,顶点程序
)
中的操作通常相对于具有预先声明的稀疏结构的
单个属性图来定义。虽然这有助于进行一系列优化,但它也会使可能跨越多个图和子图的分
析任务的表达变得复杂。
2) 图数据模型并行抽象
图的经典算法中,从
PageRank
到潜在因子分析算法都是基于相邻顶点和边的属性迭代
地变换顶点属性,这种迭代局部变换的常见模式形成了图并行抽象的基础。在图并行抽象中, 用户定义的顶点程序同时为每个顶点实现,并通过消息(
例如
Pregel
)或共享状态(例如
PowerGraph
)
与相邻顶点程序交互。每个顶点程序都可以读取和修改其顶点属性,在某些情
况下可以读取和修改相邻的顶点属性。
顶点程序并发运行的程度因系统而异。大多数系统采用批量同步执行模型,其中所有顶
点程序以一系列“超级步”同时运行。但是也有一些系统支持异步执行模型,通过在资源变
得可用时运行顶点程序来减轻落后者的影响。
3) 图模型系统优化
对图数据模型进行抽象和对稀疏图模型结构进行限制,使一系列重要的系统得到了优化。
比如
GraphLab
的
GAS
模型更偏向共享内存风格,允许用户的自定义函数访问当前顶点的
整个邻域,可抽象成
Gather
、
Apply
和
Scatter
三个阶段。
GAS
模式的设计主要是为了适应
点分割的图存储模式,从而避免
Pregel
模型对于邻域很多的顶点、需要处理的消息非常庞大时会发生的假死或崩溃问题。
2技术篇
从上文的概述中我们看到,图计算领域面临大数据环境带来的巨大挑战。随着图数据量
上升速度的加快,图数据库和图计算受关注程度也在不断提高。
1.1 技术挑战
图提供了非常灵活的抽象,用于描述离散对象之间的关系。科学计算、数据分析和其他领域的许多实际问题可以通过图以其基本形式建模,并通过适当的图算法求解。随着图的问
题规模越来越大,复杂性越来越大,它们很容易超过单处理器的计算和内存容量。鉴于并行计算在许多科学计算领域取得了成功,并行处理似乎可以克服图计算中单个处理器资源受
到的限制。
当整体计算问题解决方法得到很好的平衡时,应用程序可以更好地执行和扩展,即,当
需要解决的问题、用于解决问题的算法、用于表达算法的软件以及运行软件的硬件使两者都
能很好地相互匹配。在很大程度上,并行科学计算的成功归功于这些方面,与典型的科学应
用完全匹配。解决科学领域中典型问题
(通常涉及求解偏微分方程系统
)
的常用习语已经发
展并成为科学计算界的标准实践。同样,适用于典型问题的硬件平台和编程模型也变得很普
遍。世界各地的机房包含运行用
MPI
编码的商用集群。
不过,对于开发主流并行科学应用程序而言,效果良好的算法、软件和硬件对于大规模
图问题并不一定有效。图问题具有一些固有的特征,使它们与当前的计算问题解决方法不匹
配。大图计算是大数据计算中的一个子问题,除了满足大数据的基本特性之外,大图计算还
有着自身的计算特性,相应地面临着新的挑战。特别是,图问题的以下属性对高效并行性提
出了重大挑战。
1) 局部性差
图表示着不同实体之间的关系,而在实际的问题当中,这些关系经常是不规则和无结构
的,因此图的计算和访存模式都没有好的局部性,而在现有的计算机体系架构上,程序的性
能获得往往需要利用好局部性。所以,如何对图数据进行布局和划分,并且提出相应的计算
模型来提升数据的局部性,是提高图计算性能的重要方面,也是面临的关键挑战。
2) 数据及图结构驱动的计算
图计算基本上完全是由图中的数据所驱动的。当执行图算法时,算法是依据图中的点和边来进行指导,而不是直接通过程序中的代码展现出来。所以,不同的图结构在相同的算法实现上,将会有着不同的计算性能。因此,如何使得不同图结构在同一个系统上都有较优的处理结果,也是一大难题。
3) 图数据的非结构化特性
图计算中图数据往往是非结构化和不规则的,在利用分布式框架进行图计算时,首先需
要对图进行划分,将负载分配到各个节点上,而图的这种非结构化特性很难实现对图的有效
划分,从而达到存储、通信和计算的负载均衡。一旦划分不合理,节点间不均衡的负载将会
使系统的拓展性受到严重的限制,处理能力也将无法符合系统的计算规模。
4) 高访存/计算比
绝大部分的大图计算规模使得内存中无法存储下所有的数据,计算中磁盘的 I/O 必不可少,而且大部分图算法呈现出迭代的特征,即整个算法需要进行多次迭代,每次迭代需要遍历整个图结构,而且每次迭代时所进行的计算又相对较少。因此,呈现出高的访存/计算比。另外,图计算的局部性差,使得计算在等待I/O 上花费了巨大的开销。
图算法与图计算框架简介
本节将重点介绍图算法与图计算框架,为便于读者理解,接下来先简要介绍一下图数据库。
在众多不同的数据模型里,关系数据模型自
20
世纪
80
年代就处于统治地位,而且出现
了不少巨头,如
Oracle
、
MySQL
,它们也被称为关系数据库管理系统
(
RDBMS
)
。然而,
随着关系数据库使用范围的不断扩大,也暴露出一些它始终无法解决问题,其中最主要的是
数据建模中的一些缺陷和问题,以及在大数据量和多服务器之上进行水平伸缩的限制。
因此,近年来诞生了
Neo4j
,
InfiniteGraph
等专注于图结构化存储与查询的图数据库。
与传统的关系型数据库相比,图数据库善于处理大量的、复杂的、互联的、多变的网状数据,
效率远远高于传统型数据库,性能约有百倍以上的提升,特别适合用于社交网络、实时推荐、
银行交易环路、金融征信系统等领域。
图计算是基于图数据的分析技术与关系技术应运而生的,图计算系统就是针对处理图
结构数据的系统,并对这样的数据进行针对性优化的高效计算。与传统计算模型相比,图计
算模型主要针对解决以下问题:
1)
图计算的频繁迭代带来的读写数据等待和通信开销大的问题;
3)
图数据的复杂结构使得图算法难以实现分布不均匀的分块上并行计算的问题。
为应对以上问题,
Google
基于
BSP
(
Bulk Synchronous Parallel
)推出了新的“计算框架”
——Pregel
。之后,
CMU
提出了开源图计算框架
GraphLab
。虽然二者都是对于复杂机器学习计算的处理框架,用于迭代型(
iteration
)
计算,但是二者的实现方法却采取了不同的路
径:
Pregel
是基于大块的消息传递机制,
GraphLab
是基于内存共享机制。同样的,
Spark
也
提供了专门支持图计算的模块
——GraphX
,可以用于实现复杂的图数据挖掘。
对于图数据,遍历算法是其它算法的基础。典型的图算法有
PageRank
、最短路径、连
通分支、极大独立集、最小代价生成树以及
Bayesian Belief Propagation
等。图的最小生成树
在生活中常代表着最低的成本或最小的代价,常用
Prim
算法和
Kruskal
算法。社区发现, 最短路径,拓扑排序,关键路径也都有对应的算法。下面简单对图算法进行介绍。
l
社区发现
(
Community
Detection
)
社区发现算法是用来发现网络中的社区结构,也可以看做是一种聚类算法。社区发现算
法可以用来发现社交网络中三角形的个数
(
圈子
),
可以分析出哪些圈子更稳固,关系更紧
密,用来衡量社群耦合关系的紧密程度。从一个人的社交圈子里面可以看出,三角形个数越
多,说明他的社交关系越稳固、紧密。在图计算的社交应用当中,像
Facebook
、
Twitter
等
社交网站,常用到的的社交分析算法就是社群发现。
PageRank
是
Sergey Brin
与
Larry Page
于
1998
年提出来的,用来解决链接分析中网页
排名的问题。
PageRank
的计算充分利用了两个如果:数量如果和质量如果。
PageRank
源自
搜索引擎,它是搜索引擎里面非常重要的图算法,可用来对网页做排序。比如我们在网页里
搜索
weibo
,会出来非常多有着
weibo
关键字的网页,可能有上千上万个相关网页,而
PageRank
可以根据这些网页的排序算法将其排序,将一些用户最需要的网页进行优先展示。
最短路径用于计算一个节点到其他所有节点的最短路径。主要特点是以起始点为中心
向外层层扩展,直到扩展到终点为止。最短路径在社交网络里面,有一个六度空间的理论,
表示你和任何一个陌生人之间所间隔的人不会超过五个。最短路径是图算法中的一种,在图
计算应用上很常见。
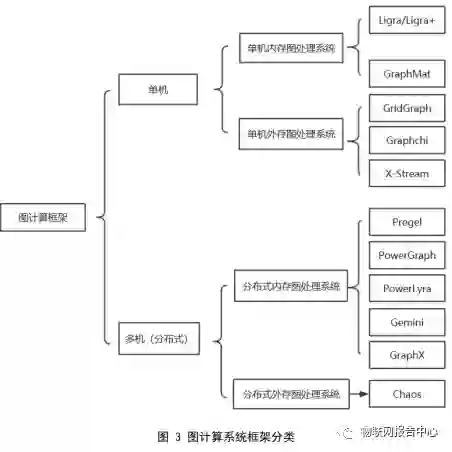
图计算框架
依据大规模图计算系统的使用场景以及计算平台架构的不同,我们将其分为单机内存图计算系统、单机外存图计算系统、分布式内存图计算系统和分布式外存图计算系统。
![]()
单机内存图处理系统就是图处理系统运行在单机环境,并且将图数据全部缓冲到内存
当中。单机外存图处理系统就是图处理系统运行在单机环境,并且通过计算将图数据不断地与内存和磁盘进行交互的高效图算法。分布式内存系统就是图处理系统运行在分布式集群环境,并且所有的图数据加载到内存当中。分布式外存图计算系统将单机外存系统
(
Single- machine out-of-core systems
)
拓展为集群,能够处理边数量级为
trillion
的图。
此类图计算系统单机运行,可直接将图完全加载到内存中进行计算。但是单机的计算能
力和内存空间总是有限,故只能解决较小规模的图计算问题,比较有代表性的系统有
2013
年发布的
Ligra
和
Galois
,以及
2015
年发布的
GraphMat
和
Polymer
。
其中
Ligra
提出了根据图稠密情况自适应的切换计算模式,并提供了一种基于边映射,
顶点映射以及顶点集映射的并行编程算法。
Galois
使用
DSLs
(
domain-specific
languages
)
写
出更复杂的算法完成图分析工作,并发现当输入图是道路网络或者具有较大直径的图时能
获得一个数量级的性能提升,在现有的三种图
DSLs
基础上提供了轻量级的
API
,简化了图算法的实现。
GraphMat
是第一个对多核
CPU
进行优化的以顶点为编程中心的轻量级图计算框架,为用户和开发者提供了友好的接口。
Polymer
则是针对在
NUMA
特性的计算机结构上运行图算法的优化,作者发现无论是
随机或者交错地分配图数据都会重大地束缚数据的本地性和并行性,无论是
intra-node
还是
inter-node
,顺序访存都比随机访存的带宽高的多。
此类图计算系统单机运行,但是将存储层次由
RAM
拓展到外部存储器如
SSD
,
Flash
,
SAS
,
HDD
等,使其所能处理的图规模增大。但受限于单机计算能力和外存存储系统的数据交换的带宽限制也无法在可接受的情形下处理超大规模的图数据。典型的图计算系统有
GraphChi
、
TurboGraph
、
X-Stream
、
PathGraph
、
GridGraph
和
FlashGraph
。
这些系统在最大化磁盘顺序读写、选择调度和同异步计算模式等方面做出了重要探索,
TurboGraph
和
FlashGraph
主要采用分页方式分割图来提高内外存的数据交换性能。
其中
GraphChi
采用了传统的以顶点为中心的编程模型,计算模式为隐式
GAS
。它使用
了名为
shard
的外存数据结构来存储边,而将顶点划分为多个连续的区间,提出了一种基于并行滑动窗口(
PSW
)模型达到对存储在磁盘上的图数据最大的顺序读写性能。但是构建
shard
是需要对边按源顶点排序,这样耗费了大量的预处理时间,
PSW
对计算密集型的算法
更有利。另外在构建子图时出现大量的随机访存现象,通过顺序地更新子图内有共享边顶点
来避免数据争用问题。
X-Stream
则介绍了一种以边为中心的编程模型。在
scatter
阶段以流的形式处理每条边
和产生传播顶点状态更新集,在
gather
阶段它以流的形式处理每一个更新并应用到对应的
顶点上。自然图中顶点集远远大于边集,所以
X-Stream
把顶点存储在高速存储设备
(
Cache
对于
RAM
,
RAM
对于
SSD/Disk
)
中表现为随机读写,把边集和更新集存于低速存储设备
中表现为最大程度的顺序读写。
X-Stream
流式访问图数据,其流划分相比于
GraphChi
无需
对
shard
内的边进行排序大大缩短了预处理时间,并使用
work-stealing
避免
Scatter-Gather
导
致的线程间负载不均衡的问题。但是
X-Stream
在计算过程中,每轮迭代产生的更新集非常
庞大,接近于边的数量级;而且需要对更新集中的边进行
shuffle
操作;缺乏选择调度机制,
产生了大量的无用计算。
GridGraph
将顶点划分为
P
个顶点数量相等的
chunk
,将边放置在以
P*P
的网格中的每
一个
block
中,边源顶点所在的
chunk
决定其在网格中的行,边的顶点所在的
chunk
决定其
在网格中的列。它对
Cache/RAM/Disk
进行了两层级的网格划分,采用了
Stream vertices and edges
的图编程模型。计算过程中的双滑动窗口
(
Dual Sliding Windows
)
大大减少了
I/O
开
销,特别是写开销。以
block
为单位进行选择调度,使用原子操作对保证线程安全的方式更
新顶点,消除了
X-Stream
的更新集和
shuffle
阶段。但是,其折线式的边
block
遍历策略不
能达到最大化的
Cache/Memory
命中率。
此类图计算系统将图数据全部加载到集群中的内存中计算,理论上随着集群规模的增
大其计算性能和内存容量都线性增大,能处理的图数据也按线性扩大。图分割的挑战在分布
式系统愈加明显,再加上集群网络总带宽的限制,所以整体性能和所能处理的图规模也存在
一定的缺陷。这类图计算系统主要包括同步计算模型的
Pregel
及其开源实现
Piccolo
,同时
支持同步和异步的系统
PowerGraph
、
GraphLab
和
GraphX
。
PowerSwitch
和
PowerLyra
则对
PowerGraph
做了改进,
Gemini
则借鉴了单机内存系统的特性提出了以计算为核心的图计算系统。以下对部分分布式内存图处理系统做一介绍。
为了更有效地解决大规模图上的计算问题,学术界与工业界提出了大量专门为图优化
的计算系统。
Pregel
是来自
Google
的图计算领域的开山之作,是首个采用
BSP
计算模型的
分布式内存图计算系统,计算由一系列的“超步”(
super-step
)
组成,在一个超步内并行地
执行用户自定义函数。很多后续的图计算系统均借鉴了其中的核心思想,例如“以顶点为中
心”(
vertex-centric
)
的编程模型,让用户将计算过程抽象为基于顶点的计算和基于边的消
息传递
(
message
passing
)
,以及
BSP
的处理模型,顶点之间并行处理
(
计算和通信
)
,通
过超步
(
super-step
)
之间的路障
Barrier
来同步计算过程。
Giraph
是
Pregel
的一个开源实现,
在
Facebook
内部进行了大规模的部署与应用。
PowerGraph
是面向分布式内存的解决方案,通过使用更多的机器来扩展能够处理的图的规模。
PowerGraph
的一个重要贡献是提出了基于“顶点切割”
(
vertex-cut
)
的图划分思
想,通过在不同机器上创建顶点的多个副本
(
replica
)
,以主
-
从
(
master-mirror
)
副本间的
同步来替代传统的沿着边传递消息的通信模式,有效地减少了通信量以及由度数较高顶点导致的负载不均衡。后续的很多分布式图计算系统比如
GraphX
、
PowerLyra
等均沿用了
PowerGraph
的处理模型。
GraphX
是一个基于
Apache Spark
的嵌入式图计算框架
(
Apache Spark
是一种广泛使用的分布式数据流系统
)。
GraphX
提供了一个熟悉的可组合图抽象,足以表达现有的图
API
,
但只能使用少数基本数据流操作符
(
例如
join
,
map
,
group-by
)来实现。为了实现与专用图
系统的性能平衡,
GraphX
将图特定的优化重新分配为分布式连接优化和材料化视图维护。通过利用分布式数据流框架的进步,
GraphX
为图处理带来了低成本的容错能力。
Gemini
是在单机内存图计算系统的高效性和分布式内存图计算系统的伸缩性之间找到
差异性,从而提出的一个以计算为核心优化目标的分布式图计算系统。其主要关注点为计算
而非通信,一方面尽可能避免分布式带来的开销,另一方面吸纳现有单机系统的技术来实现
高效的计算。
Gemini
针对图结构的稀疏或稠密情况使用与
Ligra
相同的自适应推动
/
拉动
(
push/pull
)
方式的计算,将推动
(
push
)
模式和拉动
(
pull
)
模式的双模式计算引擎从单机
的共享内存扩展到了分布式环境中,从而将分布式系统的通信从计算中剥离出来。此外,除
了
节点间的负载均衡,
G
e
m
i
ni
在节点内也通过细粒度的块式划分结合工作偷取
(
w
o
r
k
s
t
ea
li
ng
)
的
方式,使得多核间的负载尽可能均衡。在性能方面,
Gemini
尽可能地减少了分布式的开销,
使得运行于单机时的效率能够接近甚至超过现有最佳性能的单机系统,比现有已知分布 式图
计算系统的性能也提高了数倍。
此类图计算系统将
Single-machine out-of-core systems
拓展为集群,能够处理边数量级为
trillion
的图,目前有
2015
年发布的
Chaos
。
Chaos
是对
X-Stream
系统的拓展,分别设计了
计算子系统和存储子系统。它的主要贡献表现在:是第一个拓展到多机外存存储结构的图计
算系统;采用简单的图分割方案,即不强调数据的本地性和负载均衡,而是通过存储子系统
达到外存存储的高效顺序读写;使用
work-stealing
机制实现动态负载均衡。但是
Chaos
的信
息量过大,随着集群规模的扩大,网络将会成为瓶颈;简单的拓展未优化的
X-Stream
,其更
新集依然很庞大与边量级相当;计算与存储独立设计增加了系统的复杂性和不可避免的通信开销;存储子系统为了使存储设备时刻忙碌而占用了较多的计算资源。
TuX
2
作为一个全新的分布式图引擎,致力于融合图计算和分布式机器学习系统。
TuX
2
继承了传统图计算系统中的优势:简洁的计算模型,高效的数据排布,均衡的负载分配以及
超过
10
亿条边的规模处理能力;并对于分布式机器学习进行了大幅扩展和优化,以支持异质性、延时同步并行。
TuX
2
上实现了一系列具有代表性的分布式机器学习算法,涵盖了监督学习和非监督学习,具有一个量级上的性能优势。
1.1 技术资源
Open Academic Graph(OAG)是通过链接 Microsoft Academic Grapg(MAG)和AMIner 两个大型学术图表生成的。(https://www.aminer.cn/oag2019 )我们将 OGA2019 的统计数据呈现为下面三个图,包括VenueCollection PaperCollection 和 Author Collection 三部分。
![]()
Pregel: a system for large-scale graph processing Grzegorz Malewicz, Matthew H. Austern, Aart J. C. Bik, James C. Dehnert, Ilan Horn, Naty Leiser, Grzegorz Czajkowski SIGMOD Conference,, pp. 135-146, (2010) |
Distributed GraphLab: a framework for machine learning and data mining in the cloud Yucheng Low, Danny Bickson, Joseph Gonzalez, Carlos Guestrin, Aapo Kyrola, Joseph M. Hellerstein Proceedings of the VLDB Endowment, no. 8 (2012): 716-727 |
PowerGraph: distributed graph-parallel computation on natural graphs Joseph E. Gonzalez, Yucheng Low, Haijie Gu, Danny Bickson, Carlos Guestrin OSDI,, pp. 17-30, (2012) |
GraphLab: A New Framework For Parallel Machine Learning. Yucheng Low, Joseph Gonzalez, Aapo Kyrola, Danny Bickson, Carlos Guestrin, Joseph M. Hellerstein Clinical Orthopaedics and Related Research, (2014) |
GraphChi: large-scale graph computation on just a PC Aapo Kyrola, Guy Blelloch, and Carlos Guestrin. GraphChi: large-scale graph computation on just a PC. OSDI, 2012. |
Graphx: Graph processing in a distributed dataflow framework Joseph E. Gonzalez, Reynold S. Xin, Ankur Dave, Daniel Crankshaw, Michael J. Franklin, Ion Stoica OSDI,, pp. 599-613, (2014) |
X-Stream: edge-centric graph processing using streaming partitions Amitabha Roy, Ivo Mihailovic, Ivo Mihailovic,Willy Zwaenepoel SOSP,, pp. 472-488, (2013) https://static.aminer.org/pdf/20170130/pdfs/sosp/ozz12hqruancqbijue8b6pm7siewytf0.pdf |
Ligra: a lightweight graph processing framework for shared memory Julian Shun, Guy E. Blelloch PPOPP,, pp. 135-146, (2013) https://static.aminer.org/pdf/20170130/pdfs/ppopp/gxrite4sseq1juzxofcanzbnplrhh5kv.pdf |
PowerLyra: differentiated graph computation and partitioning on skewed graphs |
Rong Chen, Jiaxin Shi, Yanzhe Chen, and Haibo Chen. PowerLyra: differentiated graph computation and partitioning on skewed graphs. EuroSys, 2015. |
GridGraph: Large-Scale Graph Processing on a Single Machine Using 2-Level Hierarchical Partitioning Xiaowei Zhu, Wentao Han, Wenguang Chen USENIX Annual Technical Conference,, (2015) |
3 人才篇
在大数据时代,图计算具有表达能力强、可扩展性支持、快速高效的并行计算能力等优
势,能解决大容量的数据分析问题。图计算的研究风潮席卷了全球,无论是
Google
还是
Facebook
,科技企业都在全力以赴地投入图计算领域的研究;在国内,进行相关研究的主要
有清华大学、上海交通大学等高校以及阿里、华为等互联网企业。
图计算相关的重要会议包括:
OSDI
(
Operating Systems Design and Implementation
)
SOSP
(
Symposium on Operating Systems Principles
)
USENIX ATC
(
USENIX Annual Technical Conference
)
VLDB
(
Very Large Data Bases
)
SIGMOD
(
Special Interest Group on Management Of Data
)
EuroSys
(
The European Conferenceon Computer Systems)
PPoPP
(
ACM
SIGPLAN
Annual
Symposium
Principles
and
Practice
of
Parallel
Programming
) 等。
我们对这些会议近
10
年(
2009
年至
2018
年
)
的论文进行挖掘,筛选出其标题、关键
字以及摘要中涉及
graph
、
graph
computing
、
graph
pattern
、
graph
mining
、
graph
processing
等
图计算领域关键词的论文,再对其作者进行挖掘,整理出图计算相关活跃学者
1000
人。
1.1 学者情况概览
本节对这些学者进行了简单的统计分析,包括他们的分布地图、迁徙状况、机构分布、
h-index
水平、性别分布等。
![]()
由
AMiner
绘制的全球图计算领域活跃学者所在地区的分布地图
(
如图
4
所示
)
可以看
出,图计算领域学者在北美洲最为集中,亚洲次之,欧洲西部该领域的人才分布也较多。
分国家来看,美国东部该领域学者较为集中,其次是中国,欧洲主要在德国和英国拥有
该领域较多数量的学者。
图
8
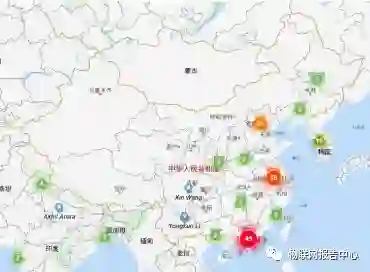
是国内图计算领域活跃学者的分布图,由该图可见,国内学者集中分布在长三角、
珠三角以及京津冀等地区。从全局来看,内陆地区的学者分布数量相对沿海地区要少,沿海地区珠三角是全国学者分布最为集中的地区,内陆地区的学者则主要集中分布在华北及我
国东北三省地区,学者数量呈由南到北逐渐减少的分布状态。
![]()
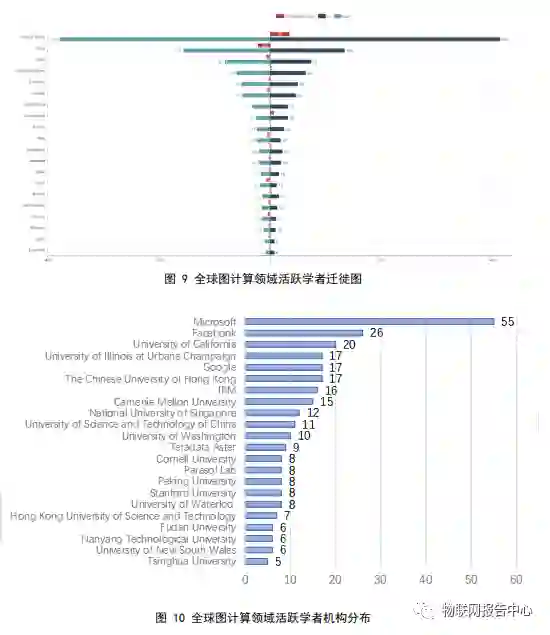
除了地区分布,我们还对图计算领域学者的迁徙路径做了分析。由图
6
可以看出,美国
是图计算领域人才流动大国,人才输入和输出幅度领先于其他国家,且从数据来看人才流入大于人才流出。中国、英国、印度等国人才迁徙流量小于美国,其中中国与印度有轻微的人
才流失现象。除美国和中国外,其余各国图计算学者的流失和引进是相对比较均衡的。
人才的频繁流入流出,使得该领域的学术交流活动增加,带动了人才质量的提升的同时,
也促进了领域理论及技术的更新迭代,至此逐渐形成一种良性循环的过程。
![]()
如图
10
所示,是对全球计算机图计算领域学者所属机构的统计,数据显示多名学者就
职于同一机构的现象较为普遍,机构所拥有的学者数量越多,一定程度上越能反映出该机构
的科研与创新能力,直观地印证其在该领域具备更强的竞争力,因此我们对表现最突出的机
构进行了以上排名。
在图计算领域,
Microsoft
(
微软
)
拥有的影响力学者数量最多,共
55
人,位于榜首,
Facebook
以
26
名位居第二,
University of California
(
加利福尼亚大学
)
共拥有
20
名学者位
居第三。中国拥有
10
位以上学者的机构有香港中文大学和中国科学技术大学,分别拥有
17
名和
11
名学者。中国拥有该领域学者数
10
人以下的机构分别有
Peking University
(北京大学)
、
Hong Kong University of Science and Technology
(
香港科技大学
)
、
Fudan University
(复旦大学)以及
Tsinghua University
(清华大学)。
![]()
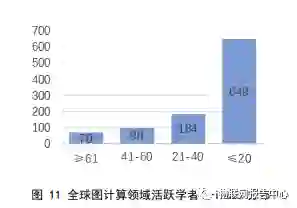
全球图计算领域学者
h-index
的平均数为
21
,其中,
h-index
≥
21
的学者占比
38.03%
;可见,
h-index
低于平均值的学者人数超过了一半,占比
61.97%
。从每个
h-index
分度区间来看,
h-index
在
20
以下区间的学者人数最多,有
649
人,占比
64.84%
;
h-index
≥
60
的人
数最少,有
70
人,占比
6.99%
。
![]()
在性别比例方面,男性(占比
96.31%
)占据多数,比例要远高于该领域女性所占比例
3.2 典型学者简介
综合 h-index 以及领域知名度与活跃度,我们分别选取了国内外(按国籍)两部分图计算领域具有代表性的学者做一介绍,排名不分先后。由于本报告侧重于介绍图计算系统,因此代表性学者均选自该研究领域。此外,限于报告篇幅,我们对所有学者不能逐一罗列,如有疏漏,还请与AMiner 编者联系,或者登录https://www.aminer.cn/获取更多资料。
3.2.1 国外学者简介
![]()
Ion Stoica
,美国加州大学伯克利分校
的
计算机科学
系
教授
,
AMPLab
的共同创始人,
他是一位
罗马尼亚裔美国
计算机科学家,
专门研究
分布式系统
,
云计算
和
计算机网络
。
他于
2000
年获得了
卡耐基梅隆大学
(
CMU
)
Hui
Zhang
(
张辉
)
教授的电气与计算机工程专
业博士学位。其研究主题包括
Chord
(
点对点
)
,核心无状态公平队列
(
CSFQ
)
和
Internet
间接基础设施。
他的博士生导师
Hui Zhang
是
P2P
思想的重要先驱,论文《
End System Multicast
》的应用层覆盖网多播思想的合作提出者之一。
Ion Stoica
在
Hui Zhang
的基础上进一步将
P2P
技
术带到了互联网。其在
SIGCOMM'01
会议上发表的论文《
Chord: A scalable peer-to-peer lookup service for internet applications
》成为结构化
P2P
网络的开山之作。
Ion Stoica
的研究兴趣包括
云计算
、
网络
、
分布式系统
和
大数据
。他在
计算机科学的
各个领域撰写或共同撰写了
100
多篇
同行评审
论文。
他在
2001
年获得了计算机协会博士论文奖;
2002
年获得
PECASE
(
工程师总统早期职业奖)
奖;
2003
年获得斯隆基金会奖学金;
2007
年获得
CoNEXT
(
International Conference on emerging Networking EXperiments and Technologies
)
新星奖;
2011
年获得了
SIGCOMM
(
Special Interest Group on Data Communication
美国计算机协会
ACM
数据通信专业组)时间测试奖。
在加入
加州大学伯克利分校
担任
终身
教授之前,
Ion
Stoica
在
麻省理工学院(
MIT
)
担任
博士后研究
职位。
2006
年,他成为
Conviva
的联合创始人
兼首席技术官
(
CTO
)
,该公司
(
Conviva
)
之前是
CMU
的
End System Multicast
项目。
2013
年,他联合创立了
Databricks
,
担任首席执行官,直到
2016
年
1
月被
Ali Ghodsi
取代后他继而担任执行主席。此外,他也
是
ACM
(
计算机协会
)
Fellow
。
![]()
Willy Zwaenepoel
,
ACM
Fellow
,
IEEE
Fellow
,自
2018
年
6
月
15
日起被任命为悉尼大学工程与信息技术学院院长。
Willy Zwaenepoel
在
1984
年获得斯坦福大学博士学位。他从事过操作和分布式系统的
各个方面的工作,包括微内核、容错、工作站集群上的并行科学计算、
Web
服务集群、移动
计算、数据库复制和虚拟化。他最著名的作品是
Treadmarks
分布式共享内存系统,该系统
的工作促成了
iMimic Networking
公司的创建,
2000
年至
2005
年公司由他领导。
他目前的兴趣包括大规模数据存储和软件测试。他在软件测试方面的工作促成了一家位于洛桑的创业公司 BugBuster 的创建。因为他的研究成果,iMimic 和 BugBuster 已被思科收购。
他于 1998 年当选为 IEEE Fellow,2000 年当选为 ACM Fellow。他还是 1998 年至 2002年 IEEE 并行和分布式系统交易的副主编。他是多个会议的项目主席:1996 年担任OSDI 项目主席,2004 年任Mobisys(The International Conference on Mobile Systems, Applications, and Services)主席,2006 年担任 Eurosys 项目主席。
2002
年
9
月,他加入了
EPFL
(
École
polytechnique f
é
d
é
rale de Lausanne
洛桑联邦理工学院
)
。
2002
年至
2011
年,他担任
EPFL
计算机与通信科学学院院长。在加入
EPFL
之前,
他是莱斯大学
(
Rice University
)
的教师,担任计算机科学与电气和计算机工程系的
Karl
F.
Hasselmann
教授,并在
2000
年获得了莱斯大学研究生协会教学与指导奖。
他分别在
1984
年
SigComm
,
1999
年的
OSDI
、
Usenix 2000
、
Usenix 2006
和
Eurosys 2007
上获得了最佳论文奖。他还获得了
2007
年
IEEE Tsutomu Kanai
奖。
![]()
Keshav K Pingali
,美国计算机科学家,
ACM Fellow
,
IEEE Fellow
,德克萨斯大学奥斯
汀分校
网格和分布式计算的
William Moncrief
主席。
Keshav K Pingali
于
1986
年获得麻省理工学院硕士和博士学位。他曾获得
2013
年
IIT Kanpur
杰出校友奖。
Keshav K Pingali
从事编程语言和编译器技术,用于程序理解,优化和并行化。他目前
的研究兴趣是编程多核处理器的方法和工具,重点关注图,社交网络和数据挖掘等领域的非
常规应用程序。
在成为
德克萨斯大学奥斯汀分校
网格和分布式计算的
William
Moncrief
主席之前,他曾
2003
年
-2006
年任印度
康奈尔大学
计算机科学系主席,并在
印度理工学院
任
N
.
Rama
Rao
教授。他还是
AAAS
(
美国科学促进会
)、
ACM
以及
IEEE Fellow
。
Guy E. Blelloch
![]()
Guy E. Blelloch
,
ACM Fellow
,卡内基梅隆大学计算机科学系教授,以并行编程和并行
算法领域的研究而闻名。
Guy E. Blelloch
在卡内基梅隆大学教授现实世界中的算法、并行算法课程,以及并行和
顺序数据结构和算法课程。
目前,他正在研究的主题主要有:基准并行算法、缓存高效的并行算法、数据结构和算
法。他与合作研究者一直在开发用于计算并行机器上的局部性的高级算法模型,开发在这些模型下有效的算法。此外,他还研究了用于图、索引、网格和集合的紧凑数据结构。由他的
研究兴趣河流图可见,他对算法的研究未曾中断,并行算法在近
10
年成为他的重点研究领域。
![]()
Ca
r
l
os
Gue
s
t
r
in
,机器学习界知名学者,
Tu
r
i
曾用名
G
r
aph
L
ab
和
Da
to
,后更名为
Tur
i
)
创始人,曾被
P
o
pu
l
ar
Sc
i
e
n
c
e
(
大众科学
)
杂志评为
2
0
08
年“
B
r
illi
ant
10
”
(
“辉煌
10
强”
)
。
Carlos Guestrin 拥有斯坦福大学的博士学位,是华盛顿大学Paul G. Allen 计算机科学与工程学院的亚马逊机器学习教授。Carlos Guestrin 还曾任职卡内基梅隆大学Finmeccanica副教授和英特尔伯克利研究实验室的高级研究员。
他还是 Turi(最初是 GraphLab)的联合创始人兼首席执行官。Turi 最初是 2009 年卡耐基梅隆大学的一个开源项目,之后从学校分离成为独立公司。该团队专注于大规模机器学习和图分析,帮助开发者在应用中加入机器学习和人工智能技术,具体使用场景包括推荐引擎、反欺诈、预测用户数变化、情绪分析以及用户分类等,该公司已经被苹果于 2016 年收购。
他的工作得到了多个会议和两个期刊的奖项,分别是: NIPS(Conference and Workshopon Neural Information Processing Systems)2003 和 2007,VLDB 2004,UAI(Conference onUncertainty in Artificial Intelligence)2005,ICML(International Conference on Machine Learning)2005,IPSN(International Conference on Information Processing in Sensor Networks)2005 和2006,KDD(Knowledge Discovery and Data Mining)2007 和 2010,JWRPM 2009,AISTATS(International Conference on Artificial Intelligence and Statistics)2010,JAIR(Journalof Artificial Intelligence Research)2007 和 2012。他还是 ONR 青年研究员奖、NSF(National Science Foundation 美国国家科学基金会)职业奖、Alfred P.Sloan 奖学金,IBM 教师奖学金, Siebel 奖学金和斯坦福百年教学助理奖的获得者。他还获得了 IJCAI(International Joint Conference on Artificial Intelligence)计算机和思想奖以及科学家和PECASE(工程师总统早期职业奖)。
他还是
DAR
P
A
(
De
f
en
s
e
A
d
v
anced
Re
s
ea
r
ch
P
r
o
j
ec
t
s
A
gency
美国国防高级研究计划局
)
信息科学与技术
(
ISAT
)
咨询小组的前成员。
![]()
Christos Faloutsos
,被誉为“数据库大师”。
Christos Faloutsos
是希腊计算机科学家,拥有多伦多大学博士学位,任卡内基梅隆大学
计算机科学系教授。他的研究兴趣包括流和网络的数据挖掘,分形,多媒体和生物信息学数
据库的索引以及性能。
他于
1989
年获得了国家科学基金会颁发的总统青年研究员奖,
22
个最佳论文奖和几个
教学奖。
1994
年以有关在时间序列数据库中快速子序列匹配的论文获得
SIGMOD
最佳论文
奖。
1997
年以他的
R+
树论文获得
VLDB
十年论文奖,此外,他还获得了
ACM
(
Association
for Computing Machinery
)
2010 SIGKDD
创新奖。
![]()
陈文光,
CCF
(
中国计算机学会
)
高级会员,清华大学计算机系教授,主要研究领域为
操作系统、程序设计语言与并行计算。
陈文光于
2000
年获得清华大学计算机系博士学位。
2007
年
-2015
年任清华大学计算机系副主任、现任清华大学计算机系学术委员会副主任,兼任青海大学计算机系主任。
他是
ACM
中国理事会副主席,
ACM
中国操作系统分会
ChinaSys
主任,
CACM
(
Central
American Common Market
中美洲共同市场
)
中文版主办《
Journal of Computer Science and
Technolog
》计算机系统与体系结构
Leading Editor
,《软件学报》责任编委,曾经参与编著
《
JAVA
虚拟机规范》以及《
MPI
与
Open MP
并行程序设计:
C
语言版世界著名计算机教材精选》等书。
他担任
ASPLOS
(
ACM
International
Conference
on
Architectural
Support
for
Programming Languages and Operating
Systems
),
PLDI
(
ACM SIGPLAN conference on Programming Language
Design
and
Implementation
),
PPoPP
,
SC
(
Supercomputing
Conference
全球超级计
算大会
),
CGO
(
International
Symposium
on
Code
Generation
and
Optimization
),
IPDPS
(
International Parallel and Distributed Processing Symposium
),
APSYS
(
ACM Asia-Pacific Workshop on Systems
)等领域内重要会议的程序委员会委员。
他在国内外学术期刊和学术会议上共发表论文多篇,是国家杰出青年基金获得者,获国
家科技进步二等奖一次、部级科技一等奖两次,已授权中国发明专利
1
项,申请美国专利
1
项。他还是中国计算机学会杰出会员和杰出讲者、副秘书长,青年科技论坛荣誉委员。
陈文光长期研究高性能计算编程模型和编译系统,近几年在以图计算系统为代表的新一代大数据处理系统方面取得了进展。
2014
年提出并实现了一种单机图处理引擎
GridGraph
,通过一种基于源和目的节点双层
混洗的图数据结构,能够高效利用外存放置图的边,从而实现在单机上处理十亿结点以上的
图。
GridGraph
性能比国际上同类单机图处理引擎如
X-STREAM
和
GraphChi
性能提高了一
个数量级,论文在
USENIX ATC 15
上发表。
2016
年初,他进一步研制成功了名为“双子座”的分布式图计算系统,通过稀疏
/
稠密
双模式计算引擎、稀疏性敏感的紧凑数据结构以及细粒度动态负载平衡等技术,在典型大数
据分析应用
(
如
PageRank
、
ALS
等
)
上的性能是国际同类图计算系统
PowerGraph
和
PowerLyra
的十倍以上,是目前流行的大数据系统
Spark
性能的
100
倍以上,占用内存仅为
其十分之一,其论文在
OSDI 16
上发表。
![]()
陈海波,现任上海交通大学软件学院教授,
PowerLyra
共同作者,主要研究领域为系统软件,系统结构与系统虚拟化。
他于
2009
年获得复旦大学计算机系统结构专业博士学位。
陈海波曾在麻省理工学院参与众核操作系统研究,并曾在虚拟化公司
VMWare
加州总
部从事可信虚拟化的研究。他曾担任国际学术会议
2011ACM
亚太系统会议
(
APSys
2011
)
的共同主席,并担任多个国际顶级学术会议如
2012
年
U
S
E
N
I
X
技术年会
(
Us
e
n
i
x
A
T
C
20
1
2
),
2013
年国际操作系统原理大会
(
SOSP
2013
),
2013
年欧洲系统大会
(
EuroSys
2013
)
等的
程序委员会委员。其相关研究成果发表在诸多国际顶级会议如国际操作系统原理大会
(
SOSP
),
USENIX
操作系统设计与实现大会
(
OSDI
)
,国际体系结构大会
(
ISCA
),
国
际微处理结构大会
(
MICRO
)
,国际软件工程大会
(
ICSE
),
国际并行处理原理与实践大会(
PPoPP
)
与
IEEE Transactions on Software Engineering
等。
他于
2009
年被评为中国计算机学会上海青年
IT
新锐,
2010
年获得
IBM X10
学院奖学
金,他的博士论文《云计算平台可信性增强技术的研究》获得
2011
年全国优秀博士论文及
2009
年中国计算机学会优秀博士论文奖,他还于
2012
年获得
NetApp
学院奖学金。
![]()
武永卫,清华大学计算机科学与技术系高性能计算研究所副所长,中国国家网格运行管
理中心副主任,
IEEE Cloud Computing
编委。
武永卫于
2002
年获得中科院系统所应用数学博士学位,研究方向为并行与分布式处理,
云计算,存储系统,主要开展分布式计算与处理
(
如网格计算、云计算
)
等方面的研究工作, 研究分布式资源的动态管理和调度机制、应用软件
/
系统的远程部署方法、基于网络的高性
能计算用户使用模式、分布式文件系统和数据管理技术等。具体的研究方向包括运行时环境、
数据存储与管理、虚拟化、资源管理调度、性能分析、分布式协同与一致性、可靠性与容错等。
他提出了基于区间的高性能计算系统的负载预测方法,为改善高性能计算系统的运行效能提供支持。该方法系统分析和聚类各种高性能计算系统的运行
trace
特点,通过自适应
的负载趋势分析,提前更多时间进行预测,并将预测结果应用到作业调度,用于改善高性能计算系统的吞吐能力。他还提出了通过远程动态部署的方法改善和优化网格
/
云计算平台性
能的方法,避免了热点应用引起的热点资源问题。该方法利用虚拟化技术,提供用户按需定
制的物理
/
虚拟运行环境,并完成系统平台和应用软件的自动按需部署。
作为开发组组长,他研制完成的网格中间件系统
CGSP
支持了中国教育科研网格
(
ChinaGrid
),其中的热部署技术被网格中间件系统
GlobusToolkits
采纳。他所在的研究组
研制完成的清华大学云计算平台“
TsinghuaCloud
”被美国的
CloudBook
引用,其中的云存
储平台
Corsair
于
2008
年
11
月开始在清华大学投入实际运行。
武永卫主要获奖经历有:
2008
年获得国家科技进步二等奖;
2009
年
ScalCom
最佳论文奖;
2011
年
IMIS
最佳论文奖和中创软件人才奖;
2014
年获得
FSE ACM SIGSOFT
杰出论文奖;
2015
年获得国家技术发明二等奖:面向社区共享的高可用云存储系统;
2015
年获得
Tsinghua
Science and Technology
最佳论文奖。
![]()
代亚非,现
任北京大学
信息科学技术学院
教授
,从事分布式系统方面的研究工作。她于
1993
年从哈尔滨工业大学计算机系获得
博士学位
。
代亚非
教授
主要的科研领域包括
计算机网络
与
分布式系统
和
P2P
计算。她早期研究
P2P
共享及存储系统,后续开展了云计算,云存储,图计算等研究,所在课题组曾经开发了
P2P
存储系统
Amazingstore
,实际运行多年,在高校内拥有一定规模的用户群。
她曾主持了包括
973
课题、
863
课题、
国家自然科学基金
、国家科技重大专项课题、
国
家信息产业部
等多项科研课题,在国内国际重要的期刊和会议发表相关论文百余篇。她所主持的
北京大学
“计算概论”课程被评为中国“国家级精品课程”,
2011
年被评为北京市教学
名师。她在
2
0
14
年获得教育部科技进步二等奖,
2015
年获得中国电子学会科技进步一等奖。
4 产业应用篇
2016
年
IBM
公司的全球技术展望
(
GTO
)
中提出,信息科技的发展已经从帮助人类完善自动化的工作向智能化迈进,而未来智能化认知计算发展的三大方向之一就是图计算以
及基于图的认知技术,包括图分析、图特征挖掘、图认知推理、以及与机器学习技术的结合。
利用图的强大的关联分析能力和对客观世界还原的优势,未来图计算技术将重点在分布式
部署、大图分析、实时可视化等领域,而与行业应用的结合则是发挥图计算能力的最优选择
图就在我们身边,它们遍布各地,如
Facebook
、谷歌、
Twitter
、电信、生物、医药、营
销和股票市场。同时,它们影响计算机科学的众多领域,包括软件工程、数据库和集成电路
的设计。
目前,图计算已应用于医疗、金融、社交分析、自然科学以及交通等领域,很多互联网公司以及很多年轻的人工智能领域创业公司也都开展了图计算相关的业务。以下我们就图
计算的主要应用场景与公司进行简介。
1.1 医疗行业的应用
图计算的出现使得对病人的智能诊断成为可能。对病人开具处方需要依据病人的病情
特征与以往的健康情况,以及药物的相关情况。过去的医疗大多依赖于医生的个人经验与病人的自我描述,传统的数据处理系统无法一次性调出多个与病人情况、保险情况、药物情况
相关的数据库——挑战在于信息必须由多个在线资源拼凑而成,包括列出疾病和治疗的电
子病历、医疗保险或其他跟踪医疗服务的数据库、描述药物的数据库,在某些情况下,还有
跟踪临床试验的独立数据库。该场景是经典的链接网络,每个节点之间具有相互依赖性。变
量可包括患者年龄和性别、特定药物
(
或药物组合
)
的结果、特定剂量,给药时的疾病阶段
和潜在的药物相互作用。传统的
SQL
数据库实际上不可能计算这样的问题,因为传统的纯软件图无法提供应用所需的深度嵌套的连接,而图分析系统的出现则使得这样的场景成为了可能。
1.2 金融行业的应用
在金融实体模型中,存在着许许多多不同类型的关系,以及数十亿的结点和边。有些是
相对静态的,如企业之间的股权关系、个人客户之间的亲属关系,有些则是不断地在动态变
化,如转账关系、贸易关系等等。这些静态或者动态的关系背后,隐藏着很多以前我们不知
道的信息。之前,我们在对某个金融业务场景进行数据分析和挖掘过程中,通常都是从个体
(
如企业、个人、账户等
)
本身的角度出发,去分析个体与个体之间的差异和不同,很少从
个体之间的关联关系角度去分析,因此会忽略很多原本的客观存在,也就更无法准确达到该
业务场景的数据分析和挖掘目标。而图计算和基于图的认知分析正是在这方面弥补了传统
分析技术的不足,帮助我们从金融的本质角度来看这个问题,从实体和实体之间的经济行为
关系出发来分析问题。
在金融行业中,图计算以及认知技术重点应用的业务领域包括:金融风险的管控、客户
的营销拓展,内部的审计监管、以及投资理财等方面。例如,银行面临的洗钱犯罪风险,目前很多情况下,银行对洗钱伎俩和手段的调查和分析还依赖调查员的手工方式来做,不仅效
率低下,工作量大,而且极易造成漏查的问题。目前洗钱的手段和步骤错综复杂,整个过程
大致可分为以下三个方面,并且交互交叉重叠,反复出现。
1)
存放(
Placement
):
将犯罪得益放进金融体系内。
2)
掩藏
(
Layering
)
:将犯罪得益转换成另一种形式,例如从现金换成支票、贵重金
属、股票、保险储蓄、物业等。
3)
整合(
Integration
):
经过不同的掩饰后,将清洗后的财产如合法财产,融入经济
体系。
面对这样的复杂困难问题,目前金融机构采取的手段都是基于预先设定的规则来分析
每笔交易的背后是否存在洗钱可能,将这些高可能性的交易区分为交易组,交由调查员来进
行审核调查,但是最后的结果通常都发现,利用这种预先定义的规则来识别出来的警告信息,
误报率很高,有的达到
80%
以上,给调查员带来很大无必要的工作量。所以,如何提高高风
险交易识别的准确率是在反洗钱领域急需解决的问题。而利用图计算和图认知技术,从交易
本身出发,探查交易方的交易历史,跟踪交易的轨迹,追溯资金的流向,找出规则方法无法
覆盖的新的洗钱模式,及时地更新现有的探查规则,从而大幅度降低误报率。
再如国内商业银行都面临的信贷风险问题:受国内经济下行的影响,企业客户贷款的不
良率攀升。为了提高银行对企业不良风险传导的预测能力,利用图计算和图认知技术,完整
刻画企业客户之间、企业与自然人之间的社会关系、经济往来关系,构建全方位的风险关联网络,实现风险要素的动态性和完整性呈现。当关联网络内某家企业发生信贷风险时,利用
风险关联网络中风险客户的客户画像,经济行为轨迹等信息进行交叉关联分析,预测风险的
传导路径和扩散范围,帮助银行采取有效措施,阻断风险传染源,进行风险隔离,从而提升
风险管理的可靠性和准确率
[3]
。
1.3 互联网行业的应用
目前大数据在互联网公司主要应用在广告、报表、推荐系统等业务上。在广告业务方面
需要大数据做应用分析、效果分析、定向优化等,在推荐系统方面则需要大数据优化相关排
名、个性化推荐以及热点点击分析等。图计算的出现满足了这些计算量大、效率要求高的应
用场景的需求。
图计算模型在大数据公司,尤其是
IT
公司是非常流行的一大模型,它是很多实际问题
最直接的解决方法。近几年,随着数据的多样化,数据量的大幅度提升和算力的突破性进展, 超大规模图计算在大数据公司发挥着越来越重要的作用,尤其是以深度学习和图计算结合
的大规模图表征为代表的系列算法。
图计算的发展和应用有井喷之势,各大公司也相应推出图计算平台,例如
Google Pregel
、
Facebook Graph
、腾讯星图、华为图引擎服务
GES
等。接下来,本节将简要介绍图计算系统
在互联网行业的应用。
华为图引擎服务
GES
(
Graph
Engine
Service
)
是针对以“关系”为基础的“图”结构数
据,进行查询、分析的服务。广泛应用于社交关系分析、推荐、精准营销、舆情及社会化聆
听、信息传播、防欺诈等具有丰富关系数据的场景。
![]()
百度安全开源的图数据库
HugeGraph
,是百度安全团队基于安全特定场景和实际运营中
的业务需求衍生出的一款面向分析型、支持批量操作的图数据库系统。它能够与大数据平台
无缝集成,解决海量图数据的存储、查询和关联分析需求。它可以存储海量的顶点
(
Vertex
) 和边(
Edge
)
,实现
Apache TinkerPop 3
框架,支持
Gremlin
查询语言。
腾讯星图
(
Star Knowledge Graph
,即
SKG
,也称知识图谱
)
,是一个图数据库和图计
算引擎的一体化平台:融合治理异构异质数据;提供关联查询、可视化图分析、图挖掘、机
器学习和规则引擎;支持万亿关联关系数据的快速检索、查找和浏览;挖掘隐藏关系并模型
化业务经验。其应用场景如图
14
所示。
![]()
阿里关系网络分析软件是基于大数据时空关系网络的可视化分析平台,产品提供关联
网络
(
分析
)
、时空网络
(地图
)
、搜索网络、动态建模等功能,在阿里巴巴、蚂蚁金服就
按内广泛应用于反欺诈、反作弊、反洗钱等风控业务。
费马科技由清华大学计算机系教授及博士创办,是从事图数据分析和存储、提供图计算
解决方案的高新技术企业。其主要产品有图计算平台、图数据库和图计算解决方案。公司致
力于解决图数据的存储和分析难题,同时提供咨询服务,积极推进图计算在各行业的应用,
其产品应用之一为金融行业风控。费马科技自主研发的
LightningGraph
是具有完全自主知识产权的图计算平台,用于大规模复杂关系网络的存储、查询以及计算分析。
Amazon Neptune
是一项完全托管的图数据库服务,可构建和运行适用于高度互连数据集的应用程序。
Amazon Neptune
的核心是专门构建的高性能图数据库引擎,它进行了优化
以存储数十亿个关系并将图查询延迟降低到毫秒级。
Amazon Neptune
支持常见的图模型
Property
Graph
和
W3C RDF
及其关联的查询语言
Apache TinkerPop Gremlin
和
SPARQL
。
Neptune
支持图使用案例,如建议引擎、欺诈检测、知识图谱、药物开发和网络安全。
TigerGraph
总部位于纽约,在上海设有办公室。该公司提供企业级的实时图数据库平台,
发挥图数据结构天然的优势,用来探索、发现和预测数据背后深度
(
3
层以上
)
的关联关系。
需要这些重要特性的企业应用包括:风险控制,反欺诈,供应链物流优化,企业控制图谱,
个性化推荐等等。
TigerGraph
的
NPG
(
Native
Parallel
Graph
)
设计结合了原生图的存储和计
算,支持实时图更新,并提供内置的并行计算。此外,
TigerGraph
的架构是模块化的,并同
时支持分布式多机扩展和单机多核扩展的应用部署模型。
5趋势篇
随着大数据、云计算行业的发展,图计算领域也愈加受到关注,图计算技术的应用也愈
加广泛。为了解该领域发展趋势,
AMiner
基于图计算历史的科研成果数据,对其技术来源、
热度进行了研究。
全局热度
我们对图计算全局热度做了统计,如图 12 所示。图中,每个彩色分支表示一个关键词领域,其宽度表示该关键词的研究热度,各关键词在每一年份(纵轴)的位置是按照这一时间点上所有关键词的热度高低进行排序。
![]()
从全局的角度来看,自
1992
年至今,
data mining
、
computer vision
、
graph matching
、
pattern recognition
等一直都是研究人员研究的重点。
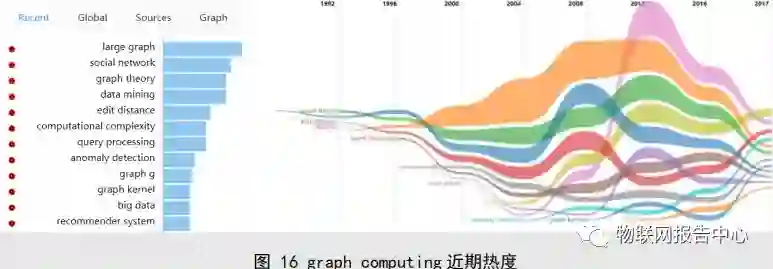
1.1 近期热度
相较于全局热点,
large graph
、
social network
、
graph theory
、
data mining
、
edit distance
![]()
1.1 交叉研究分析
根据全局热点与近期热点的趋势图,我们选取
graph computing & data mining
、
graph computing & machine learning
、
graph computing & social network
等进行笛卡尔交叉分析。通
过对两个领域的知识图谱的计算,再对两领域的细分子领域进行笛卡尔乘积热点挖掘,我们
挖掘了历史数据分析和未来趋势预测两部分。本文主要探讨
2007
年至今的研究状况;趋势
领域交叉热力值由交叉研究的论文的
citation
等数据加权计算得出,热力值越高,表明这两个交叉子领域交叉研究的越深入和广泛。
每个交叉热点中的研究学者,发表论文,中外学者和论文对比等数据均可以获得。用作
展示时,研究学者和论文分别按照交叉领域研究影响度和论文相关度作为默认排序。
学者研究影响度由交叉领域内论文量,
h-index
等计算得出;论文相关度由交叉领域内论文的关联程度和引用数量等计算得出。
对比分析中“中外研究人员对比”和“中外研究论文对比”是专家数量和论文数量的直
接对比;而“中外论文影响对比”是论文引用量
(
citation
)
的对比。
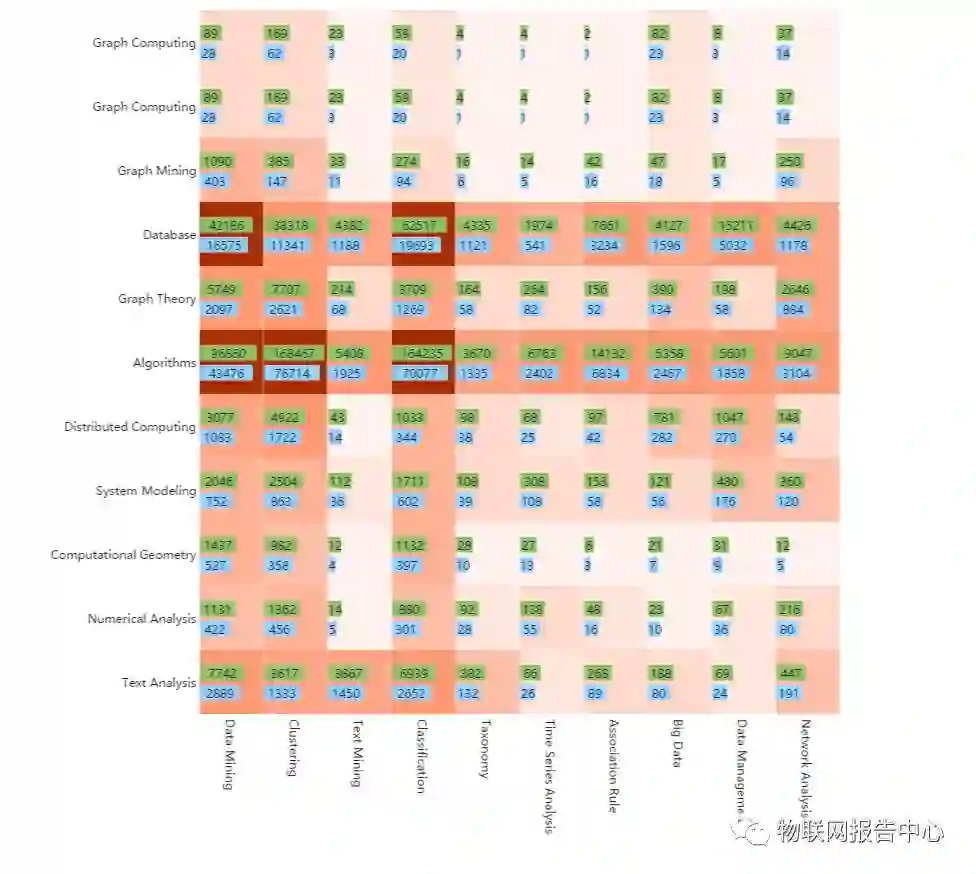
5.3.1 Graph Computing & Data Mining
我们选取
graph computing
的
11
个相关领域作为研究对象,具体包括:
1.
graph
computing
2. data structures
3.
graph mining
4. database
5.
graph theory
6. algorithms
7.
distributed
computing
8. system
modeling
9.
computational
geometry
10. numerical
analysis
我们选取
data mining
领域近期热度、全局热度最高、相关性最强的
10
个相关领域作为研究对象,具体包括:
1.
data
mining
2. clustering
3.
text
mining
4. classification
5.
taxonomy
6. time series
analysis
7.
association
rule
8. big data
9.
data management
10. network analysis
对两个领域的细分子领域进行笛卡尔乘积热点挖掘,得出历史交叉热点图如下所示:
![]() 图 17 2007 至今 graph computing 与 data mining 领域交叉分析
图 17 2007 至今 graph computing 与 data mining 领域交叉分析
2007 年至今,全球共有 492166 位专家投入了 graph computing 和 data mining 领域的交叉研究中,其中华人专家 169220 人,约占 34.38%,共产生交叉研究论 223063 篇。学者 h- index 和 citation分布如下:
表 1 2007 年至今 graph computing 与 data mining 交叉研究学者 h-index 分布
表
2 2007
年至今 graph computing 与 data mining 交叉研究论文 citation 分布
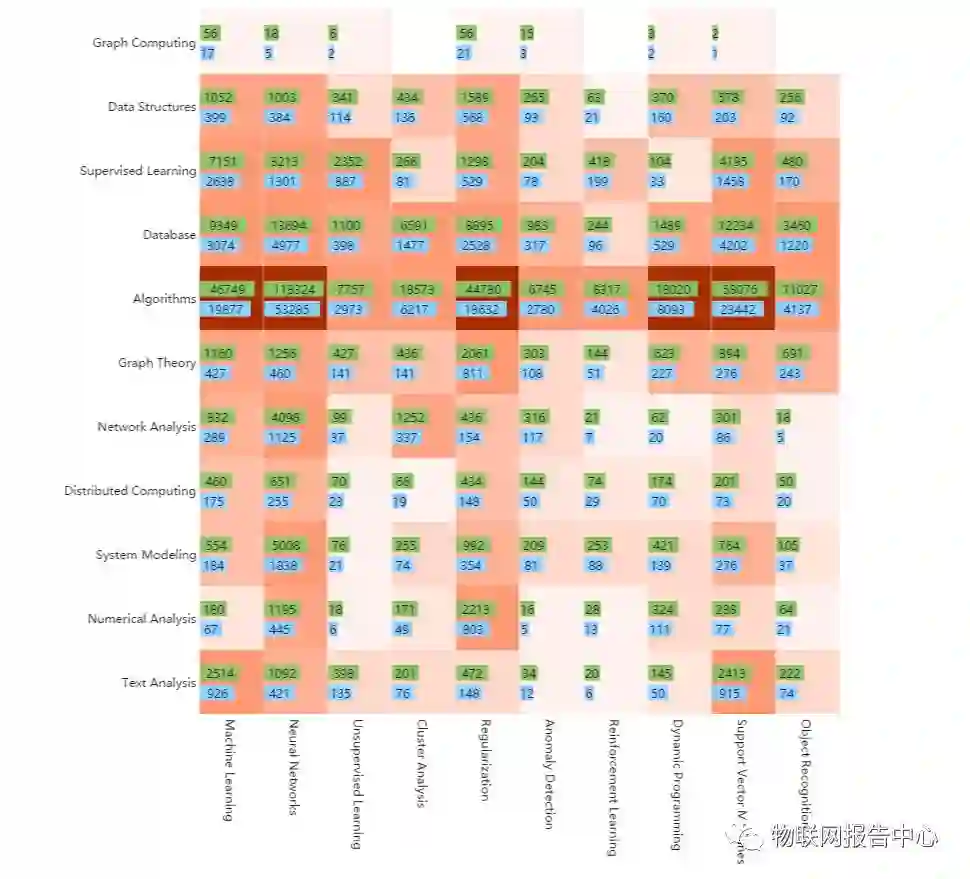
5.3.1 Graph Computing & Machine Learning
我们选取
graph computing
域近期热度,全局热度最高,相关性最强的
11
个相关领域
作为研究对象,具体包括:
1.
graph
computing
2. data structures
3.
supervised
learning
4. database
5.
algorithms
6. graph theory
7.
network
analysis
8. distributed
computing
9.
system
modeling
10. numerical
analysis
我们选取
machine learning
域近期热度,全局热度最高,相关性最强的
10
个相关领域
作为研究对象,具体包括:
1.
machine
learning
2. neural
networks
3.
unsupervised
learning
4. cluster
analysis
5.
regularization
6. anomaly
detection
7.
reinforcement
learning
8. dynamic programming
9. support
vector
machines
10. object
recognition
对两个领域的细分子领域进行笛卡尔乘积热点挖掘,得出历史交叉
热点图如下所示:
![]()
图 18 2007 至今 graph computing 与 machine learning 领域交叉分析
2007
年至今,全球共有
331387
位专家投入了
graph computing
和
machine learning
领域
的交叉研究中,其中华人专家
126793
人,约占
38.26%
,共产生交叉研究论
151511
篇。学
者
h-index
分布和
citation
分布如下:
表 3 2007 年至今 graph computing 与 machine learning 领域交叉研究学者 h-index 分布
h-index |
专家人数 |
分布占比 |
小于 10 |
310161 |
93.59% |
10~20 |
13330 |
4.02% |
20~40 |
5662 |
1.71% |
大于 40 |
1344 |
0.41% |
总计 |
331387 |
100% |
表 4 2007 年至今 graph computing 与 machine learning 领域交叉研究论文 citation 分布
Citation |
专家人数 |
分布占比 |
小于 10 |
65905 |
43.50% |
1~10 |
53162 |
35.09% |
10~100 |
28935 |
19.10% |
100~200 |
2164 |
1.43% |
大于 200 |
1345 |
0.89% |
总计 |
151511 |
100% |
1.1 技术预见
AMiner
根据图计算领域近十年的相关论文可以从图计算的技术层面进行分析,更直观
的展现出图计算相关的关系图和发展趋势图,旨在基于历史的科研成果数据的基础上,对图
计算技术发展趋势进行研究。
选取的热门关键词分别为:
co
m
b
i
na
t
o
r
i
al
a
l
go
r
it
h
m
s
、
a
s
so
c
i
a
ti
on
s
c
he
m
e
、
h
u
ff
m
an
c
od
i
n
g
、
empirical
entropy
、
suffix
tree
、
hypergraphs
、
sub-dominant
、
hypercube
、
dissimilarity
、
paths
and connectivity
problems
、
routing
、
np-completeness
、
computational
complexity
、
shortest
path
、
graph enumeration
。
![]()
Graph Computing 知识图谱(共包含二级节点 15 个,三级节点 93 个):
领域 |
二级分类 |
三级分类 |
图计算graph computing |
data structures 数据结构 |
data type 数据类型 |
abstract data type 抽象数据类型 |
graph representation 图表示 |
formal languages 形式化语言 |
graph grammar 图文法 |
formal specification 形式规约 |
canonical form 规范形式 |
algorithms 算法 |
algorithm design and analysis 算法设计与分析 |
np complete problem np完全问题 |
computational modeling 计算模型 |
polynomial time 多项式时间 |
computational complexity 计算复杂度 |
linear time algorithm 线性时间算法 |
upper bound 上界 |
new algorithm 新型算法 |
lower bound 下界 |
time complexity 时间复杂度 |
efficient algorithm 高效算法 |
approximation algorithms 近似算法 |
randomized algorithm 随机算法 |
string matching 字符串匹配 |
linear programming 线性规划 |
combinatorial optimization 组合优化 |
graph embedding 图嵌入 |
vector space 向量空间 |
feature vector特征向量 |
random walk 随机游走 |
feature extraction 特征提取 |
feature selection 特征选择 |
graph mining 图挖掘 |
graph homomorphism 图同态 |
graph isomorphism 图同构 |
subgraph isomorphism 子图同构 |
graph matching 图匹配 |
pattern matching 模式匹配, |
pattern recognition 模式识别 |
structural pattern recognition 结构化模式识别 |
database 数据库 |
graph database 图数据库 |
relational databases 关系型数据库 |
query processing 查询处理 |
xml database xml数据库 |
materialized views 物化视图 |
query optimization 查询优化 |
natural computing 自然计算 |
dna computing dna计算 |
membrane computing膜计算 |
genetic algorithm 遗传算法 |
ant colony optimization 蚁群算法优化 |
graph theory 图论 |
planar graph 平面图 |
random graph 随机图 |
median graph 中值图 |
directed graph 有向图 |
bipartite graph 二分图 |
connected graph 连通图 |
topological index 拓扑指数 |
feedback vertex set 反馈点集 |
laplacian matrix 拉普拉斯矩阵 |
complete graph 完全图 |
dominating set 支配集 |
bounded-genus graph 有界的图亏格 |
graph minor 图子式 |
claw free graph 无爪图 |
spanning tree 最小生成树 |
shortest path 最短路径 |
graph transformation 图转换 |
graph transformation system 图转换系统 |
graph rewriting 图重写 |
network analysis 网络分析 |
sensor network 传感器网络 |
communication network 通信网络 |
mobile robot 移动机器人 |
mobile agents 移动设备 |
wireless sensor network 无线传感器网络 |
petri net 佩特里网 |
stochastic petri net 随机佩特里网络 |
pagerank 网页排名 |
markov processes 马尔可夫过程 |
markov chain 马尔科夫链 |
hidden markov model隐马尔科夫模型 |
iteration method 迭代式方法 |
distributed computing 分布式计算 |
graph cut 图切割 |
fault tolerant 容错 |
local computation 局部计算 |
message passing 消息传递 |
graph partitioning 图划分 |
distributed system 分布式系统 |
distributed algorithm分布式算法 |
large graph 大图 |
machine learning 机器学习 |
support vector machines 支持向量机 |
decision tree 决策树 |
clustering algorithms 聚类算法 |
cost function 损失函数 |
energy minimization 能量最小化 |
gaussian mixture model 高斯混合模型 |
search space 搜索空间 |
language model 语言模型 |
system modeling 系统建模 |
model transformation 模型变换 |
linear system 线性系统 |
![]()
先进制造业+工业互联网
产业智能官 AI-CPS
加入知识星球“产业智能研究院”:先进制造业OT(自动化+机器人+工艺+精益)和工业互联网IT(云计算+大数据+物联网+区块链+人工智能)产业智能化技术深度融合,在场景中构建“状态感知-实时分析-自主决策-精准执行-学习提升”的产业智能化平台;实现产业转型升级、DT驱动业务、价值创新创造的产业互联生态链。
产业智能化平台作为第四次工业革命的核心驱动力,将进一步释放历次科技革命和产业变革积蓄的巨大能量,并创造新的强大引擎;
重构设计、生产、物流、服务等经济活动各环节,形成从宏观到微观各领域的智能化新需求,催生
新技术、新产品、新产业、新业态和新模式;
引发经济结构重大变革,深刻改变人类生产生活方式和思维模式,实现社会生产力的整体跃升。
产业智能化技术分支用来的今天,制造业者必须了解如何将“智能技术”全面渗入整个公司、产品、业务等商业场景中,
利用工业互联网形成数字化、网络化和智能化力量,实现行业的重新布局、企业的重新构建和焕然新生。
![]()
版权声明:产业智能官(ID:AI-CPS)推荐的文章,除非确实无法确认,我们都会注明作者和来源,涉权烦请联系协商解决,联系、投稿邮箱:erp_vip@hotmail.com。