SFFAI分享 | 杨振:低资源神经机器翻译[附PDF]

关注文章公众号
回复"杨振"获取PDF资料
导读
虽然神经机器翻译模型取得了巨大的性能提升,但是其成功主要依赖于大量的高质量的双语语料。然而,获得大量的高质量的双语语料的成本极高,需要花费大量的人力和物力。在实际应用场景中,有时并没有大量的双语语料可以使用,更加极端情况是没有任何双语语料用来训练翻译模型。因此,想要继续提升神经翻译模型的性能,需要减少模型对高质量双语语料的依赖。对于低资源甚至无资源的翻译场景,我们需要研究能够更加高效使用单语语料的翻译模型和训练方法。
作者简介
杨振,中国科学院自动化研究所博士,研究方向为神经机器翻译,主要研究内容包括模型算法优化,低资源情况下的机器翻译算法研究,首次将对抗网络应用于机器翻译领域并取得了较大的性能提升。在自然语言处理及人工智能领域顶级学术会议ACL, NAACL, COLING等会议和期刊上发表论文十余篇,曾获AI Challenger全球创新挑战赛英中机器同声传译冠军,英中机器文本翻译亚军。目前在人工智能创业公司“紫冬认知”实习。

1. Introduction
本论文针对基于深度学习的神经机器翻译模型算法进行研究并针对实际应用场景对模型进行优化。神经机器翻译是从2013年开始的一个新兴的研究领域,其在很多语种上已经远远超越了传统的统计机器翻译。与传统的基于统计的翻译算法不同,神经机器翻译将翻译任务看成从一个句子序列到另一个句子序列的转化问题,通过一个包含编码器和解码器的深度神经网络完成端到端的翻译任务,从而避免了传统的统计机器翻译中繁杂的中间过程。神经机器翻译因其高度的简洁性和良好的翻译性能而受到越来越多的关注。神经机器翻译模型也经历了从最初的朴素编解码模型,到基于注意力机制的编解码模型(如,RNNSearch),再到完全基于CNN的神经机器翻译模型(如,ConvS2S),最后到完全基于自注意力机制的神经机器翻译模型(如,Transformer)的发展过程。翻译模型每一次的发展进化,都带来了性能的大幅提升。但是其成功主要依赖于大量的高质量的双语语料。为了缓解神经机器翻译模型对双语语料的依赖,使神经机器翻译能够高效的利用单语语料,研究者们提出了基于反翻译,对抗网络,迁移学习,多语言训练,无监督训练等等方法。本文重点介绍我们在将对抗网络应用于机器翻译以及无监督机器翻译上的两个工作。
2. Methods
2.1 对抗网络在机器翻译上的应用
对抗网络已经被广泛使用在计算机视觉领域并取得了巨大的成功,然而,其在NLP领域尤其是在机器翻译上的有效性还未得到足够的研究。图1是我们提出的基于条件的序列生成对抗翻译模型(BR-CSGAN)。该模型主要分为以下三个子模块:
1)生成器。根据源语言句子,生成器G致力于产生难以与人工翻译句子进行区分的目标端句子。
2)判别器。判别器D依赖于源语言端句子,努力对生成的句子和人工翻译的句子进行区分。判别器可以被看成是一个动态的目标函数,因为其会一直根据生成器进行动态更新。
3)BLEU值强化的目标。我们采用句子级别BLEU值Q作为生成器的强化目标,引导生成器生成高BLEU值的句子。Q是一个静态的目标函数,其参数不会被更新。
在训练过程中,D和Q被同时用来评价生成的句子并反馈打分值来引导生成器的学习。整个句子生成过程看成一串根据生成器定义的规则而产生的动作。在本模型中,生成器的优化目标定义为:
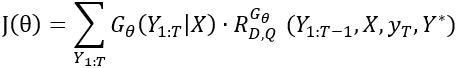
其中表示生成器的参数,
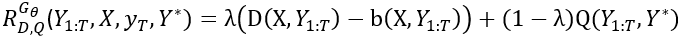
其中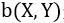
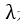
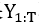
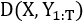
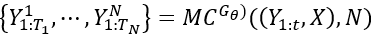
其中,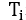
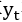
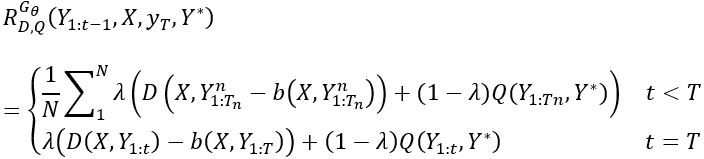
通过动态更新判别器能够进一步提升生成器的性能。一旦我们得到更加真实的生成句子,我们重新用以下公式来训练判别器:
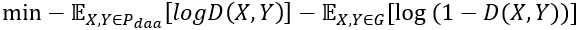
在更新完判别器之后,我们就可以重新训练生成器。目标函数的梯度是
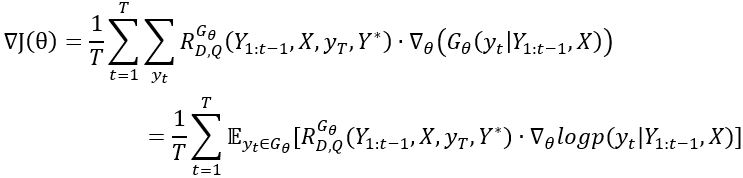
整个模型的训练过程分为以下几个步骤:
首先,用最大似然的方法在双语语料上预训练生成器直到模型性能达到最优;然后,用预训练的生成器对语料进行解码,得到生成样本;
接着,在双语语料和生成语料上预训练判别器;
最后,对生成器和判别器进行对抗训练。在训练过程中,为了缓解训练不稳定的问题,我们采取了teacher forcing的训练方法。
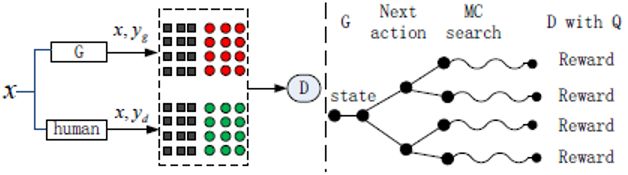
图1:基于条件的序列生成对抗翻译模型(BR-CSGAN)
2.2 基于权重共享的无监督机器翻译模型
机器翻译可以通过有监督和无监督两种方式来研究。在有监督的情况下,有一定数量的双语预料能够用来进行模型训练;在无监督情况下,只能得到彼此独立的源语言和目标语言的单语语料,没有任何双语语料能够用来提供对齐信息。由于缺少对齐信息,无监督机器翻译更具有挑战性。但是,无监督机器翻译是一个很有前景的研究方向,因为在现实场景中,单语语料总是很容易获取的。受最近取得巨大进展的无监督跨语言词向量的研究,无监督机器翻译的研究者们猜想意义相同的两个来自不同语言的句子能够映射到同一个向量空间。基于这个猜想,研究者们使用同一个编码器来编码不同的语言,然后用相同或者独立的解码器来进行解码。虽然这种无监督翻译模型取得了一定的性能,完全共享的编码器对于将不同语言的句子映射到同一个向量空间也很重要,然而,我们在试验中发现,这种完全共享的编码器是无监督机器翻译的一个性能瓶颈。共享的编码器难以保持每种语言自己特有的风格和内部特征,例如语言风格,语法和句子结构等。由于每种语言都有其自己特有的特征,因此,源语言和目标语言应该被独立的编码和学习。
本文提出了一种基于权重共享的无监督机器翻译模型。在提出的模型中,源语言和目标语言都有自己独立的编码器和解码器。对于每一种语言,编码器和解码器构成一个自编码器,在该自编码器中,编码器将加噪后的输入样本编码成隐向量,解码器从这个隐向量中解码得到原来为加噪声的输入样本。为了将相同语义的来自不同语言的句子映射到同一个向量空间,本文令源语言和目标语言的两个自编码器共享部分权重。具体的说,两个编码器共享最后一层向量,两个解码器共享第一层向量。为了强化共享隐向量空间的约束,本文将预训练后的词向量作为编码器的一个强化的编码信息。对于跨语言的训练,本文采用反翻译的方法。另外,本文还分别提出了局部对抗网络和全局对抗网络来提升跨语言翻译的性能。模型结构如图2所示。
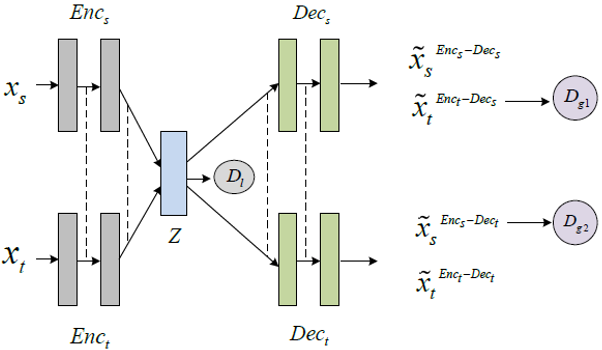
图2:基于权重共享的无监督神经机器翻译模型
我们在英德,英中,英法等翻译任务上测试了我们的模型,实验结果如图3所示。
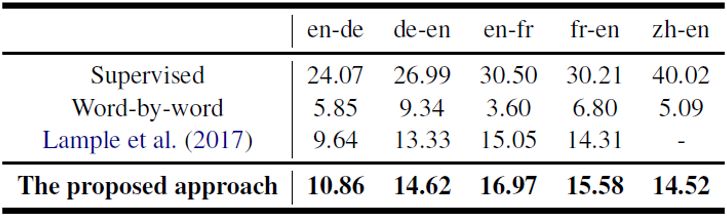
图3:无监督神经机器翻译模型性能测试
3. Take Home Message
3.1. 对抗网络天然具有利用单语语料的能力,在低资源情况下能够发挥更大的作用。
3.2. 无监督机器翻译现在虽然还处于学术前沿研究的状态,但是最近facebook提出的最新无监督翻译模型已经有大幅度的性能提升,我们在其基础上也做出了新的更好的结果。我们相信在更多的研究者的参与下,无监督机器翻译将成为解决低资源、无资源情况下机器翻译的一种主流方法。
4.Reference
[1] Bahdanau, Dzmitry, Kyunghyun Cho, and Yoshua Bengio."Neural machine translation by jointly learning to align andtranslate." arXiv preprint arXiv:1409.0473 (2014).
[2] Firat, Orhan, et al. "Multi-way,multilingual neural machine translation." Computer Speech &Language 45 (2017): 236-252.
[3] Kalchbrenner, Nal, and Phil Blunsom."Recurrent continuous translation models." Proceedings of the2013 Conference on Empirical Methods in Natural Language Processing. 2013.
[4] Johnson, Melvin, et al. "Google'smultilingual neural machine translation system: enabling zero-shottranslation." arXiv preprint arXiv:1611.04558 (2016).
[5] MelvinJohnson, Mike Schuster, Quoc V Le, Maxim Krikun, Yonghui Wu, Zhifeng Chen,Nikhil Thorat, Fernanda Vi_egas, Martin Wattenberg, Greg Corrado, et al. 2016.Google's multilingual neural machine translation system: Enabling zero-shottranslation. arXiv preprintarXiv:1611.04558 .
[6]Shiqi Shen, Yong Cheng, Zhongjun He, Wei He, HuaWu, Maosong Sun, and Yang Liu. 2015. Minimum risk training for neural machinetranslation. arXivpreprintarXiv:1512.02433 .
[7] Arnab Ghosh, Viveka Kulharia, and Vinay Namboodiri.2016. Message passing multi-agent gans .
[8] Ian Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, BingXu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and YoshuaBengio. 2014. Generative adversarial nets. In Advances in neural information processing systems. Pages 2672-2680.
[9] Mart__n Abadi, Ashish Agarwal, Paul Barham, EugeneBrevdo, Zhifeng Chen, Craig Citro, Greg S. Corrado, Andy Davis, Je_rey Dean,Matthieu Devin, San jay Ghemawat, Ian Goodfellow, Andrew Harp, Geo_rey Irving,Michael Isard, Yangqing Jia, Rafal Jozefowicz, Lukasz Kaiser, Manjunath Kudlur,Josh Levenberg, Dan Man_e, Rajat Monga, Sherry Moore, Derek Murray, Chris Olah,Mike Schuster, Jonathon Shlens, Benoit Steiner, Ilya Sutskever, Kunal Talwar,Paul Tucker, Vincent Vanhoucke, Vijay Vasudevan, Fernanda Vi_egas, OriolVinyals, Pete Warden, Martin Wattenberg, Martin Wicke, Yuan Yu, and Xiaoqiang Zheng. 2015. TensorFlow: Large-scale machine learning onheterogeneous systems.
[10] Mikel Artetxe, Gorka Labaka, and Eneko Agirre. 2016.Learning principled bilingual mappings of word embeddings while preservingmonolingual invariance. In Conference on Empirical Methods in Natural LanguageProcessing. pages 2289–2294.
[11] Mikel Artetxe, Gorka Labaka, and Eneko Agirre. 2017a.Learning bilingual word embeddings with
(almost) no bilingual data. In Meeting of the Associationfor Computational Linguistics. pages 451–462.
[12] Mikel Artetxe, Gorka Labaka, Eneko Agirre, and KyunghyunCho. 2017b. Unsupervised neural machine translation.
[13] Yong Cheng, Yang Liu, Qian Yang, Maosong Sun, and WeiXu. 2016. Neural machine translation with pivot languages. arXiv preprintarXiv:1611.04928 .
[14] Yong Cheng, Qian Yang, Yang Liu, Maosong Sun,Wei Xu,Yong Cheng, Qian Yang, Yang Liu, Maosong Sun, and Wei Xu. 2017. Joint trainingfor pivotbased neural machine translation. In Twenty-Sixth International JointConference on Artificial Intelligence. pages 3974–3980.
[15] Jonas Gehring, Michael Auli, David Grangier, Denis Yarats,and Yann N Dauphin. 2017. Convolutional sequence to sequence learning.
[16] Felix Hill, Kyunghyun Cho, and Anna Korhonen. 2016. Learningdistributed representations of sentences from unlabelled data. TACL.
[17] Guillaume Lample, Ludovic Denoyer, and Marc’Aurelio Ranzato.2017. Unsupervised machine
translation using monolingual corpora only.
[18] Tomas Mikolov, Ilya Sutskever, Kai Chen, Greg SCorrado, and Jeff Dean. 2013. Distributed representations of words and phrases andtheir compositionality. In Advances in neural information processing systems.pages 3111–3119.
[19] Amrita Saha, Mitesh M Khapra, Sarath Chandar,Janarthanan Rajendran, and Kyunghyun Cho. 2016. A correlational encoder decoderarchitecture for pivot based sequence generation. arXiv preprint arXiv:
1606.04754.
[20] Rico Sennrich, Barry Haddow, and Alexandra Birch. 2015a.Improving neural machine translation models with monolingual data. arXivpreprint arXiv: 1511.06709.
[21] Rico Sennrich, Barry Haddow, and Alexandra Birch. 2015b.Neural machine translation of rare words
with subword units. Computer Science.
[22] Tao Shen, Tianyi Zhou, Guodong Long, Jing Jiang, ShiruiPan, and Chengqi Zhang. 2017. Disan: Directional self-attention network forrnn/cnn-free language understanding.
[23] Pascal Vincent, Hugo Larochelle, Yoshua Bengio, and Pierre-AntoineManzagol. 2008. Extracting and composing robust features with denoisingautoencoders. In Proceedings of the 25th international
conference on Machine learning. ACM, pages 1096–1103.
[24] Jiacheng Zhang, Yang Liu, Huanbo Luan, Jingfang Xu, andMaosong Sun. 2017a. Prior knowledge integration for neural machine translationusing posterior regularization. In Meeting of the Association for
Computational Linguistics. pages 1514–1523.
[25] Jiajun Zhang and Chengqing Zong. 2016. Exploiting source-sidemonolingual data in neural machine
translation. In Conference on Empirical Methods in NaturalLanguage Processing. pages 1535–1545.
[26] Meng Zhang, Yang Liu, Huanbo Luan, and Maosong Sun.2017b. Adversarial training for unsupervised bilingual lexicon induction. InMeeting of the Association for Computational Linguistics. pages 1959–1970.
SFFAI讲者招募
为了满足人工智能不同领域研究者相互交流、彼此启发的需求,我们发起了SFFAI这个公益活动。SFFAI每周举行一期线下活动,邀请一线科研人员分享、讨论人工智能各个领域的前沿思想和最新成果,使专注于各个细分领域的研究者开拓视野、触类旁通。
SFFAI目前主要关注机器学习、计算机视觉、自然语言处理等各个人工智能垂直领域及交叉领域的前沿进展,将对线下讨论的内容进行线上传播,使后来者少踩坑,也为讲者塑造个人影响力。
SFFAI还将构建人工智能领域的知识树(AI Knowledge Tree),通过汇总各位参与者贡献的领域知识,沉淀线下分享的前沿精华,使AI Knowledge Tree枝繁叶茂,为人工智能社区做出贡献。
这项意义非凡的社区工作正在稳步向前,衷心期待和感谢您的支持与奉献!
有意加入者请与我们联系:wangxl@mustedu.cn

历史文章推荐:


