谷歌最强NLP模型BERT官方代码来了!GitHub一天3000星
作者:Google Research 来源:GitHub,新智元

BERT的官方代码终于来了!
昨天,谷歌在GitHub上发布了备受关注的“最强NLP模型”BERT的TensorFlow代码和预训练模型,不到一天时间,已经获得3000多星!
地址:
https://github.com/google-research/bert
BERT,全称是Bidirectional Encoder Representations from Transformers,是一种预训练语言表示的新方法。
新智元近期对BERT模型作了详细的报道和专家解读:
NLP历史突破!谷歌BERT模型狂破11项纪录,全面超越人类!
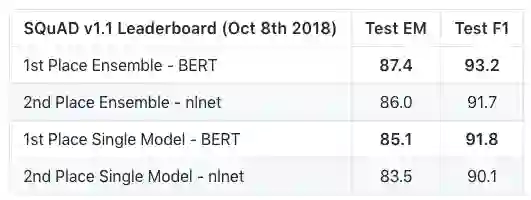
BERT有多强大呢?它在机器阅读理解顶级水平测试SQuAD1.1中表现出惊人的成绩:全部两个衡量指标上全面超越人类!并且还在11种不同NLP测试中创出最佳成绩,包括将GLUE基准推至80.4%(绝对改进7.6%),MultiNLI准确度达到86.7% (绝对改进率5.6%)等。
以下是BERT模型在SQuAD v1.1问题回答任务的结果:
在几个自然语言推理任务的结果:
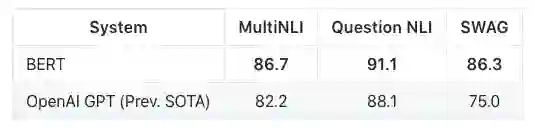
以及更多其他任务。
而且,这些结果都是在几乎没有task-specific的神经网络架构设计的情况下获得的。
如果你已经知道BERT是什么,只想马上开始使用,可以下载预训练过的模型,几分钟就可以很好地完成调优。
预训练模型下载:
https://github.com/google-research/bert#pre-trained-models
BERT是一种预训练语言表示(language representations)的方法,意思是我们在一个大型文本语料库(比如维基百科)上训练一个通用的“语言理解”模型,然后将这个模型用于我们关心的下游NLP任务(比如问题回答)。BERT优于以前的方法,因为它是第一个用于预训练NLP的无监督、深度双向的系统(unsupervised, deeply bidirectional system)。
无监督意味着BERT只使用纯文本语料库进行训练,这很重要,因为网络上有大量的公开的纯文本数据,而且是多语言的。
预训练的表示可以是上下文无关(context-free)的,也可以是上下文相关(contextual)的,并且上下文相关表示还可以是单向的或双向的。上下文无关的模型,比如word2vec或GloVe,会为词汇表中的每个单词生成单个“word embedding”表示,因此bank在bank deposit(银行存款)和river bank(河岸)中具有相同的表示。上下文模型则会根据句子中的其他单词生成每个单词的表示。
BERT建立在最近的预训练contextual representations的基础上——包括半监督序列学习、生成性预训练、ELMo和ULMFit——但这些模型都是单向的或浅双向的。这意味着每个单词只能使用其左边(或右边)的单词来预测上下文。例如,在I made a bank deposit 这个句子中, bank的单向表示仅仅基于I made a,而不是deposit。以前的一些工作结合了来自单独的left-context和right-context 模型的表示,但只是一种“浅层”的方式。BERT同时使用左侧和右侧上下文来表示“bank”—— I made a ... deposit——从深神经网络的最底层开始,所以它是深度双向的。
BERT使用一种简单的方法:将输入中15%的单词屏蔽(mask)起来,通过一个深度双向Transformer编码器运行整个序列,然后仅预测被屏蔽的单词。例如:
Input: the man went to the [MASK1] . he bought a [MASK2] of milk.
Labels: [MASK1] = store; [MASK2] = gallon为了学习句子之间的关系,我们还训练了一个可以从任何单语语料库生成的简单任务:给定两个句子A和B, 让模型判断B是A的下一个句子,还是语料库中的一个随机句子?
Sentence A: the man went to the store .
Sentence B: he bought a gallon of milk .
Label: IsNextSentence
Sentence A: the man went to the store .
Sentence B: penguins are flightless .
Label: NotNextSentence然后,我们在大型语料库(Wikipedia + BookCorpus)上训练了一个大型模型(12-layer 到 24-layer的Transformer),花了很长时间(100万次更新步骤),这就是BERT。
使用BERT分为两个阶段:预训练(Pre-training)和微调(Fine-tuning)。
预训练(Pre-training)的成本是相当昂贵的(需要4到16个Cloud TPU训练4天),但是对于每种语言来说都只需训练一次(目前的模型仅限英语的,我们打算很快发布多语言模型)。大多数NLP研究人员根本不需要从头开始训练自己的模型。
微调(Fine-tuning)的成本不高。从完全相同的预训练模型开始,论文中的所有结果在单个Cloud TPU上最多1小时就能复制,或者在GPU上几小时就能复制。例如,对于SQUAD任务,在单个Cloud TPU上训练大约30分钟,就能获得91.0%的Dev F1分数,这是目前单系统最先进的。
BERT的另一个重要方面是,它可以很容易地适应许多类型的NLP任务。在论文中,我们展示了句子级(例如SST-2)、句子对级别(例如MultiNLI)、单词级别(例如NER)以及段落级别(例如SQuAD)等任务上最先进的结果,并且,几乎没有针对特定任务进行修改。
GitHub库中包含哪些内容?
BERT模型架构的TensorFlow代码(主体是一个标准Transformer架构)。
BERT-Base和BERT-Large的lowercase和cased版本的预训练检查点。
用于复制论文中最重要的微调实验的TensorFlow代码,包括SQuAD,MultiNLI和MRPC。
这个项目库中所有代码都可以在CPU、GPU和Cloud TPU上使用。
我们发布了论文中的BERT-Base和BERT-Large模型。
Uncased表示在WordPiece tokenization之前文本已经变成小写了,例如,John Smith becomes john smith。Uncased模型也去掉了所有重音标志。
Cased表示保留了真实的大小写和重音标记。通常,除非你已经知道大小写信息对你的任务来说很重要(例如,命名实体识别或词性标记),否则Uncased模型会更好。
这些模型都在与源代码相同的许可(Apache 2.0)下发布。
请在GitHub的链接里下载模型:
BERT-Base, Uncased: 12-layer, 768-hidden, 12-heads, 110M parameters
BERT-Large, Uncased: 24-layer, 1024-hidden, 16-heads, 340M parameters
BERT-Base, Cased: 12-layer, 768-hidden, 12-heads , 110M parameters
BERT-Large, Cased: 24-layer, 1024-hidden, 16-heads, 340M parameters (暂时未发布).
每个.zip文件包含三个项目:
一个包含预训练权重的TensorFlow checkpoint (bert_model.ckpt),(实际上是3个文件)。
一个vocab文件(vocab.txt),用于将WordPiece映射到word id。
一个配置文件(bert_config.json),用于指定模型的超参数。
重要提示:论文里的所有结果都在单个Cloud TPU上进行了微调,Cloud TPU具有64GB的RAM。目前无法使用具有12GB-16GB RAM的GPU复现论文里BERT-Large的大多数结果,因为内存可以适用的最大 batch size太小。我们正在努力添加代码,以允许在GPU上实现更大的有效batch size。有关更多详细信息,请参阅out-of memory issues的部分。
使用BERT-Base的fine-tuning示例应该能够使用给定的超参数在具有至少12GB RAM的GPU上运行。
我们发布了在任意文本语料库上做“masked LM”和“下一句预测”的代码。请注意,这不是论文的确切代码(原始代码是用C ++编写的,并且有一些额外的复杂性),但是此代码确实生成了论文中描述的预训练数据。
以下是运行数据生成的方法。输入是纯文本文件,每行一个句子。(在“下一句预测”任务中,这些需要是实际的句子)。文件用空行分隔。输出是一组序列化为TFRecord文件格式的tf.train.Examples。
你可以使用现成的NLP工具包(如spaCy)来执行句子分割。create_pretraining_data.py脚本将连接 segments,直到达到最大序列长度,以最大限度地减少填充造成的计算浪费。但是,你可能需要在输入数据中有意添加少量噪声(例如,随机截断2%的输入segments),以使其在微调期间对非句子输入更加鲁棒。
此脚本将整个输入文件的所有示例存储在内存中,因此对于大型数据文件,你应该对输入文件进行切分,并多次调用脚本。(可以将文件glob传递给run_pretraining.py,例如,tf_examples.tf_record *。)
max_predictions_per_seq是每个序列的masked LM预测的最大数量。你应该将其设置为max_seq_length * masked_lm_prob(脚本不会自动执行此操作,因为需要将确切的值传递给两个脚本)。
python create_pretraining_data.py \
--input_file=./sample_text.txt \
--output_file=/tmp/tf_examples.tfrecord \
--vocab_file=$BERT_BASE_DIR/vocab.txt \
--do_lower_case=True \
--max_seq_length=128 \
--max_predictions_per_seq=20 \
--masked_lm_prob=0.15 \
--random_seed=12345 \
--dupe_factor=5
以下是如何进行预训练。
如果你从头开始进行预训练,请不要包含init_checkpoint。模型配置(包括词汇大小)在bert_config_file中指定。此演示代码仅预训练少量steps(20),但实际上你可能希望将num_train_steps设置为10000步或更多。传递给run_pretraining.py的max_seq_lengthand max_predictions_per_seq参数必须与create_pretraining_data.py相同。
python run_pretraining.py \
--input_file=/tmp/tf_examples.tfrecord \
--output_dir=/tmp/pretraining_output \
--do_train=True \
--do_eval=True \
--bert_config_file=$BERT_BASE_DIR/bert_config.json \
--init_checkpoint=$BERT_BASE_DIR/bert_model.ckpt \
--train_batch_size=32 \
--max_seq_length=128 \
--max_predictions_per_seq=20 \
--num_train_steps=20 \
--num_warmup_steps=10 \
--learning_rate=2e-5
这将产生如下输出:
***** Eval results *****
global_step = 20
loss = 0.0979674
masked_lm_accuracy = 0.985479
masked_lm_loss = 0.0979328
next_sentence_accuracy = 1.0
next_sentence_loss = 3.45724e-05问:这次公开的代码是否与Cloud TPU兼容?GPU呢?
答:是的,这个存储库中的所有代码都可以与CPU,GPU和Cloud TPU兼容。但是,GPU训练仅适用于单GPU。
问:提示内存不足,这是什么问题?
答:请参阅out-of-memory issues这部分的内容。
问:有PyTorch版本吗?
答:目前还没有正式的PyTorch实现。如果有人创建了一个逐行PyTorch实现,可以让我们的预训练checkpoints直接转换,那么我们很乐意在这里链接到PyTorch版本。
问:是否会发布其他语言的模型?
答:是的,我们计划很快发布多语言BERT模型。我们不能保证将包含哪些语言,但它很可能是一个单一的模型,其中包括大多数维基百科上预料规模较大的语言。
问:是否会发布比BERT-Large更大的模型?
答:到目前为止,我们还没有尝试过比BERT-Large更大的训练。如果我们能够获得重大改进,可能会发布更大的模型。
问:这个库的许可证是什么?
答:所有代码和模型都在Apache 2.0许可下发布。
地址:
https://github.com/google-research/bert





