浅析图像视频类AI芯片的灵活度
兼容性和灵活度是芯片快速杀入新市场、扩大市场范围、快速适应客户需求,减少开发周期的关键特性。目前深度学习的网络结构已走向了多样化,出现了大量的算法变种、更多的算子和复杂层次结构,这对芯片的支撑灵活度能力提出了挑战。本文通过列举目前图像视频类的典型算法、典型网络结构、典型平台和接口等方面来分析AI芯片的灵活度范围。
目前,DNN加速器会收敛于三类形态,第一类是支持通用运算的DSP或者GPU,它既可以实现神经网络运算,也可以实现其他数学运算或者通用程序,例如图像处理和语音处理,其典型特征是具有通用指令集和支持类C编程,如OpenCL;第二类是适用于通用数学运算的可编程架构,控制流程往往收敛于图计算表达或者数据流图,其特点是可以支持通用数学计算算子,也称作计算原语;第三类是针对若干典型神经网络结构设计的专用处理器或加速器,具有很高的能效,但没有考虑处理其他类型的运算。要了解神经网络的基本算子,可以参考“从NNVM和ONNX看AI芯片的基础运算算子”。第一类和第三类往往具有一个数量级甚至两个数量级的性能差异。而一般做到第二类才能更容易的支持灵活的训练算法(而不仅仅是推理或单一训练算法)。各个类别的典型代表如表所示。
表: 由最灵活到最不灵活的三类加速器
(在此不区分芯片还是IP)

注1: 具体可以参考唐博士的“AI/ML/DL ICs and IPs”列表中“Traditional IP Vendors”部分。
注2: 由GraphCore公开资料推测。
值得注意的是,三者没有明显的界限,厂商产品可能迅速更新,扩充灵活度后,第三类也会扩展成前两类。另外,国内厂商的设计第三类较多,但也有前两类设计出现,此处未列出国内的设计。
由于篇幅受限,本文仅讨论灵活度最低的一个类别,即仅用于神经网络的加速器。另外本文只考虑推理(Inference)而不考虑训练,主要关注视频(图像)类应用。此处,我们将结合现今CNN的各种网络拓扑结构和参数使用情况,提供一个灵活度参考表。
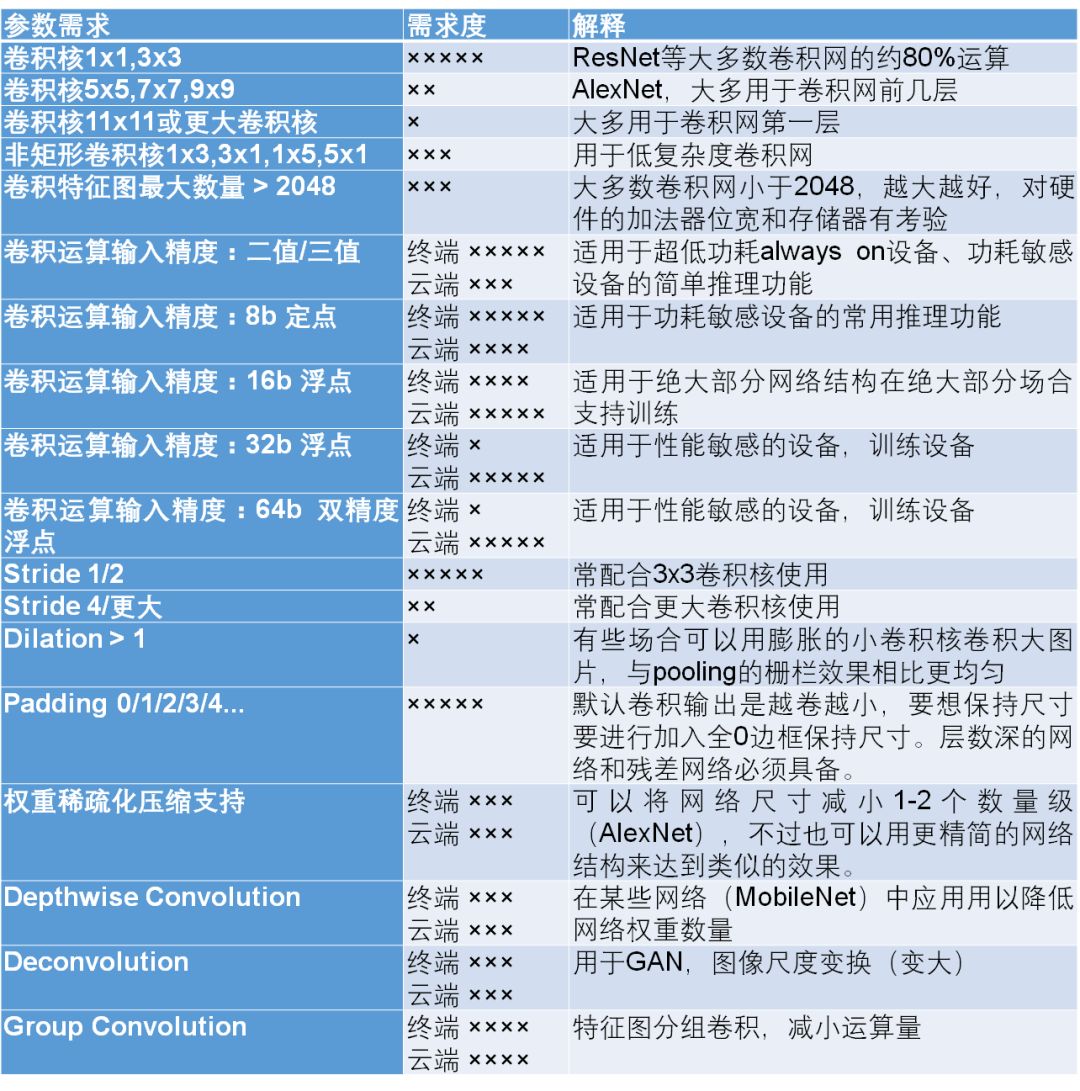
1. 卷积算子的参数覆盖需求
二维卷积操作是深度学习中最重要的操作,具有平移不变性,且相比MLP而言具有很少的参数量而不易训练过拟合。这使得深度学习之所以取得图像处理性能的飞跃提升的关键。卷积网的参数较多,总结起来如下表所示。
转自:StarryHeavensAbove
完整内容请点击“阅读原文”


