CNN真的需要下采样(上采样)吗?
加入极市专业CV交流群,与6000+来自腾讯,华为,百度,北大,清华,中科院等名企名校视觉开发者互动交流!更有机会与 李开复老师 等大牛群内互动! 同时提供每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流。关注 极市平台 公众号 ,回复 加群,立刻申请入群~
来源: https://zhuanlan.zhihu.com/p/94477174 作者: akkaze-郑安坤
本文来自知乎专栏,仅供学习参考使用,著作权归作者所有。如有侵权,请私信删除。
背景介绍
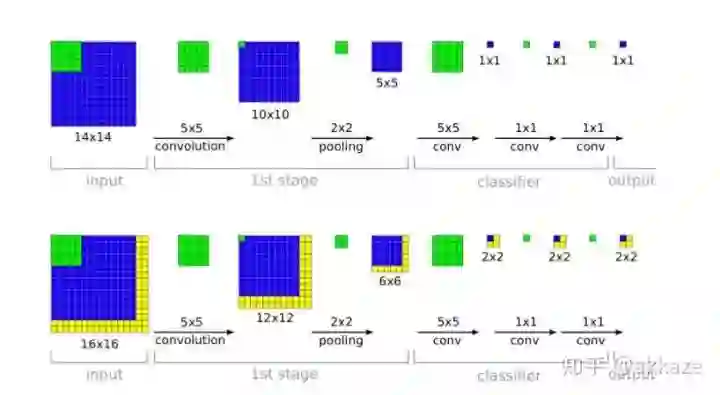
输入侧在左面(下面是有padding的,上面是无padding的),可以看到网络中用到了很多2x2的pooling
同样,在做语义分割或者目标检测的时候,我们用到了相当多的上采样,或者转置卷积
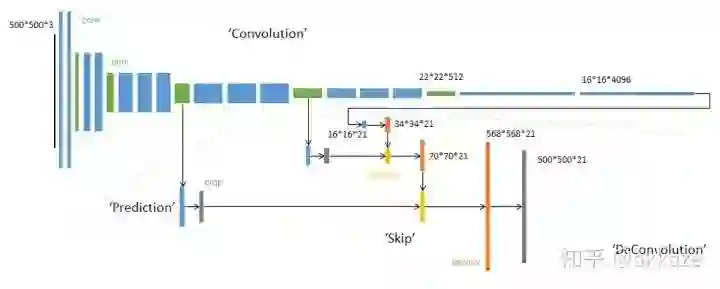
典型的fcn结构,注意红色区分的decovolution
以前,我们在分类网络的最后几层使用fc,后来fc被证明参数量太大泛化性能不好,被global average pooling替代掉了,最早出现在network in network中,
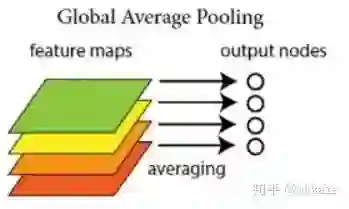
GAP直接把每个通道对应空间特征聚合成一个标量
Input-->Conv-->DownSample_x_2-->Conv-->DownSample_x_2-->Conv-->DownSample_x_2-->GAP-->Conv1x1-->Softmax-->Output
Input-->Conv-->DownSample_x_2-->Conv-->DownSample_x_2-->Conv-->DownSample_x_2-->Deconv_x_2-->Deconv_x_2-->Deconv_x_2-->Softmax-->Output
可是,我们不得不去想,下采样,上采样真的是必须的吗?可不可能去掉呢?
空洞卷积和大卷积核的尝试
一个很自然的想法,下采样只是为了减小计算量和增大感受野,如果没有下采样,要成倍增大感受野,只有两个选择,空洞卷积和大卷积核。所以,第一步,在cifar10的分类上,我尝试去掉了下采样,将卷积改为空洞卷积,并且膨胀率分别递增,模型结构如下所示,

这个网络的卷积结构,注意最后用一个空间范围的全局平均直接拉平为特征向量,最后再跟一个10维的全连接层
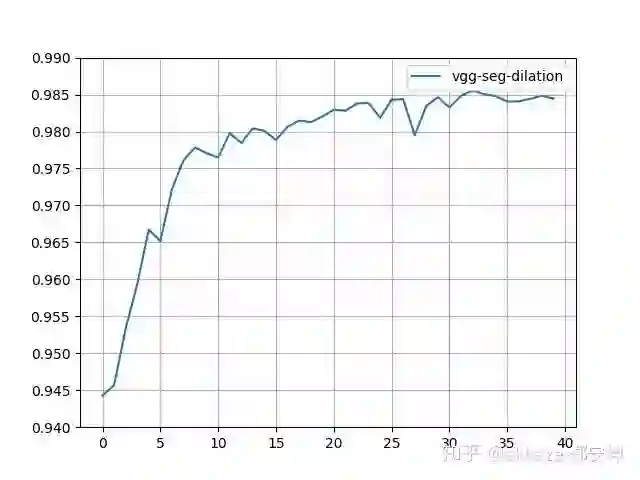
这是一个典型的四层的VGG结构,每层卷积的dilation_rate分别为1,2,4,8。在训练了80个epoch后,测试集准确率曲线如下所示 ,
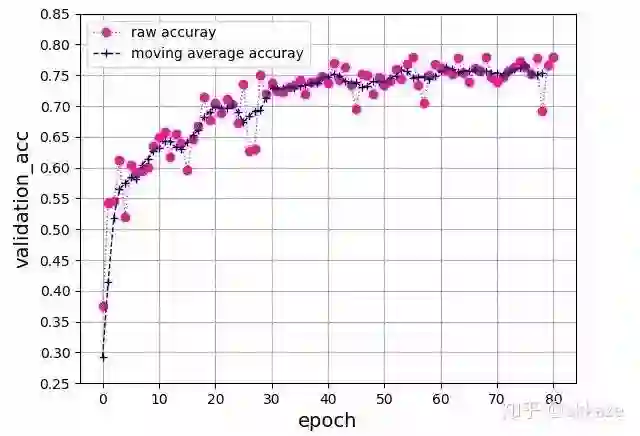
四层VGG网络,卷积的dilation_rate分别是1,2,4,8,可训练参数量25474
最终的准确率达到了76%,相同参数的vgg结构的卷积网络能够达到的准确率基本就在这附近。
从另一种思路出发,为了扩大卷积的感受野,也可以直接增加卷积的kernel_size,与上面对比,保持dilationrate为1不变,同时逐层增大卷积的kernel_size,分别为3,5,7,9,训练80个epoch后得到如下准确率曲线,
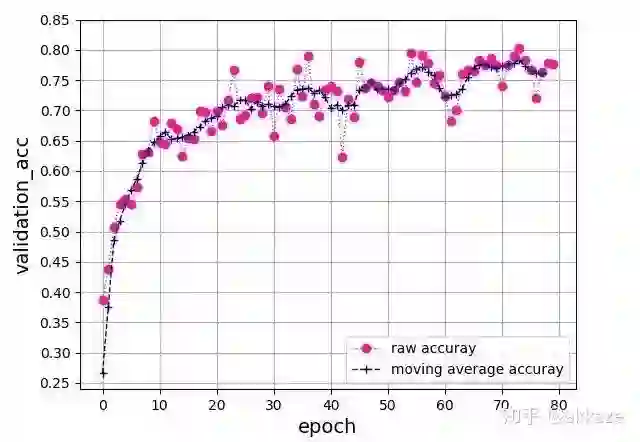
四层VGG网络,卷积的kernel_size分别是3,5,7,9,可训练参数量为172930
和之前改变dilation_rate的方式比较,收敛过程很一致,略微震荡一点,但是最终的结果很一致,都在76%上下,这说明影响最终精度的因素只有感受野和每层的通道数。
为了说明下采样在性能方面没有提升,用有下采样的网络对对比。即在不修改其他任何参数的情况下,对原本使用dilation的卷积层使用下采样,stride都设置为2,同样训练80个epoch,收敛结果如下,
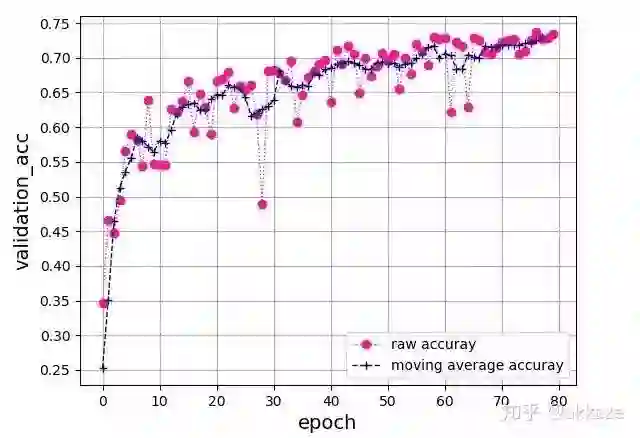
四层VGG网络,每层使用stride为2的卷积进行下采样,可训练参数量25474
最终收敛到了73%上下,比上面两个实验低了大约3个点,这说明下采样的信息损失确实不利于CNN的学习。
把三种参数的结果放在一起对比,更能够说明问题,
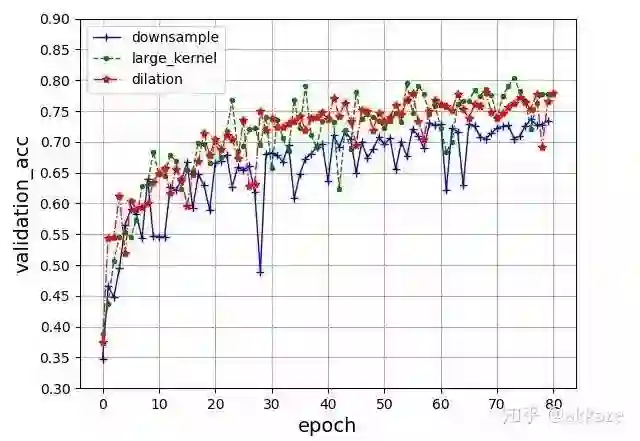
四层VGG网络的对比结果,除了卷积层参数不同,其他参数均相同
为了验证这种想法的通用性,使用resnet18结构的网络,并在原本需要下采样的卷积层使用dilation_rate不断增大的空洞卷积替代。训练80个epoch后,最终得到的准确率曲线如下 所示,
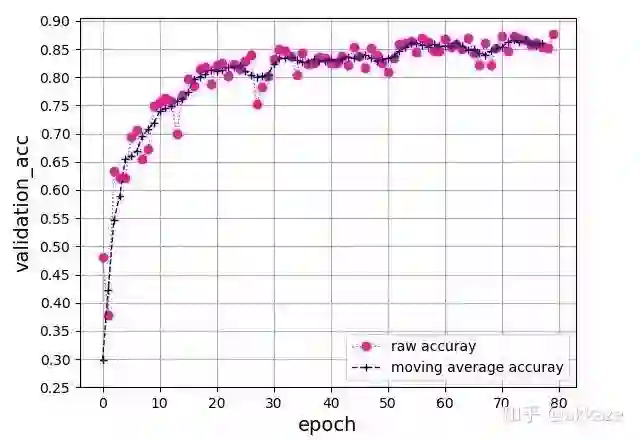
resnet18上的准确率曲线,网络通过改变卷积层dilation_rate得到
在没有其他任何调参的情况下,最后收敛到了87%的准确率。
小卷积核的尝试
我们知道,大卷积核的感受野通常可以通过叠加多个小卷积核得到,vggnet首先发现5x5卷积可以用两个3x3卷积代替,极大减少了参数量。
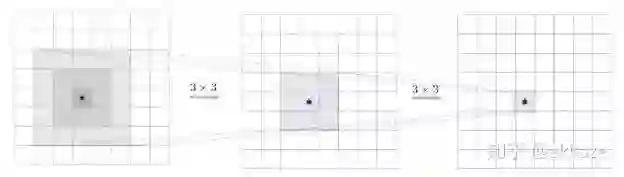
两个3x3卷积的感受野和一个5x5卷积相同,但是参数少一半
同样的7x7卷积可以用三个3x3卷积级联,9x9可以用四个3x3卷积级联。
为了获得和上面四层卷积网络相同的感受野,我设计了一个十层的只有3x3卷积的网络,每层之间依然有非线性。因为层数多了很多,为了确定中间层的通道数,我做了几组实验。同时,为了不极大增加参数量,我又在卷积中间插入depthwise卷积,这样保持对应感受野上的通道数不变,而参数量不至于增加很多。训练结果,
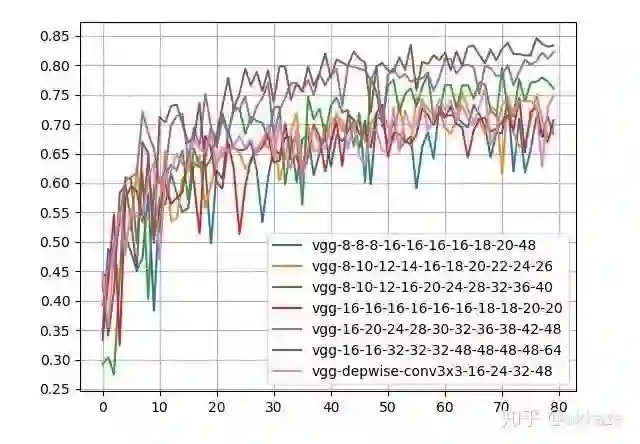
实验结果,后面的数字表示每层对于的通道数
可以看到,只有三个网络结构在精度上优于之前的设计,而这三个网络的参数量都是之前的数倍。使用depthwise卷积的网络参数量并没有增加太多,但是精度还是略低于之前的设计。
为了说明问题,增加每层的通道数,比如之前16-32-48-64的设计,改为64-128-256-512的设计,基本上对于这个深度的网络来说,容量已经接近上界了,结果如下,
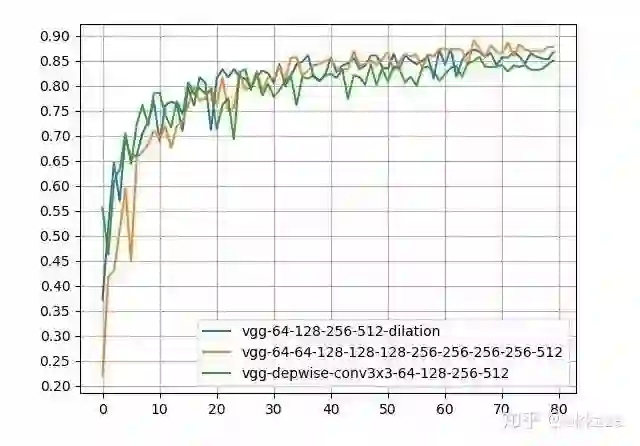
增加通道数的结果
可以看到,空洞卷积网络依然以较小的参数领先于depthwise卷积和3x3卷积混合网络,并以数倍更少的参数优势,在精度上略低于3x3级联网络。
这个实验表明,对于CNN而言,深度之外,感受野以及该感受野上的通道数,真正决定了网络的性能。
这和语音中的wavenet是相似的,
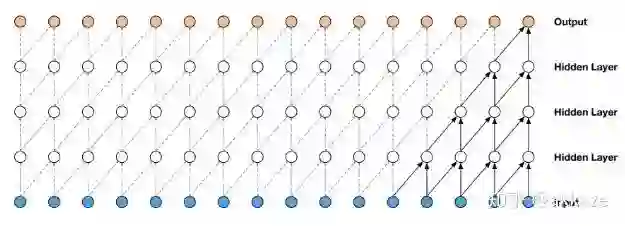
通用wavenet
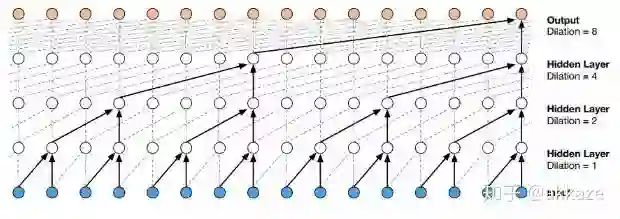
空洞wavenet
wavenet使用空洞因果卷积来降低计算量,原始wavenet的性能并没有问题,但是计算量和参数量指数增长。
稀疏化方面的思考
小卷积核叠加和大卷积核的方法为了获得和空洞卷积相同的性能,付出了参数上的巨大代价,而空洞卷积本身是稀疏的(大多数元素都是0),这促使我们思考,是否可以用稀疏化解决参数巨大的问题。
CNN的稀疏化最近研究很多,一般的卷积稀疏化见下图,并注意到每层卷积的卷积参数都是四维的,即输入通道数,输出通道数,x方向的卷积尺寸,y方向的卷积尺寸。
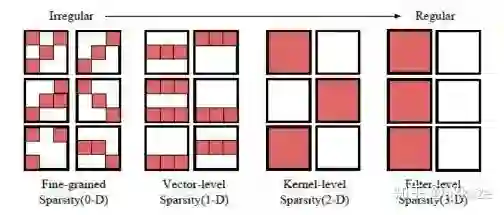
四种不同的稀疏卷积,因为卷积核权重四维的,最左边稀疏性是最不规则的,越向右规则的维度则越多,越有利于硬件加速
我们常见的其实是通道维度的稀疏化,这相当于减少通道数,也最容易加速,但是更有意义的稀疏化,我认为是卷积核内部的稀疏化,如下图所示,
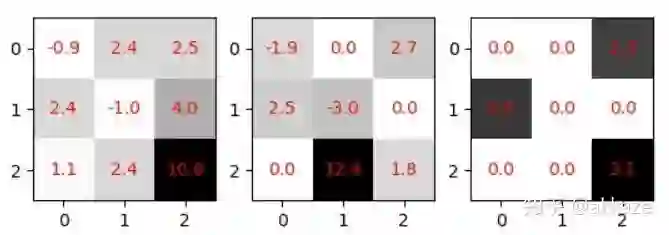
最左侧没有稀疏化,中间有零值(也就是稀疏化),最右侧有1x2的块状稀疏化
这种稀疏化能减少参数量(因为零值是没有意义的),但是因为不利于工程实现,所以目前没有明显的加速效果。
近期的研究表明,CNN里大多数卷积核都是稀疏的,大约有50%以上都是稀疏的,也就是说有50%以上参数都是冗余的。如果能去掉冗余参数,那么大卷积核和多层小卷积核也能证明在感受野和特定感受野上的通道数对CNN性能的决定性影响,在不增加额外模型参数的前提下。
尽管很容易预测,但是接下来,我们还会证明这两种方法的参数冗余。
10层3x3级联网络的可训练参数量是86404,4层空洞卷积网络参数量是25474,4层大卷积核网络参数量是172930。使用tensorfllow内置的稀疏化功能,其官方github地址为model_optimization,原理即在训练过程中,按一定的准则将卷积核的一些元素置为零,然后finetune。对于10层3x3级联网络,选择稀疏率为25%,这样稀疏化后的参数量为21601,对于大卷积核网络,选择常数稀疏率为15%,稀疏化的参数量为25940,这样稀疏化后它们的参数都比空洞卷积网络更少。为保证网络不会继续收敛了,训练1000个epoch,稀疏化从第200个epoch开始,稀疏化后的训练结果如下所示,
可以明显的看到稀疏化后的3x3级联网络的性能是最好的,同时它的参数也是最少的,同时大卷积核的性能次之,这个时候空洞卷积的性能反而略低。
保持同样的参数和稀疏度,在cifar100上训练的结果如下所示,
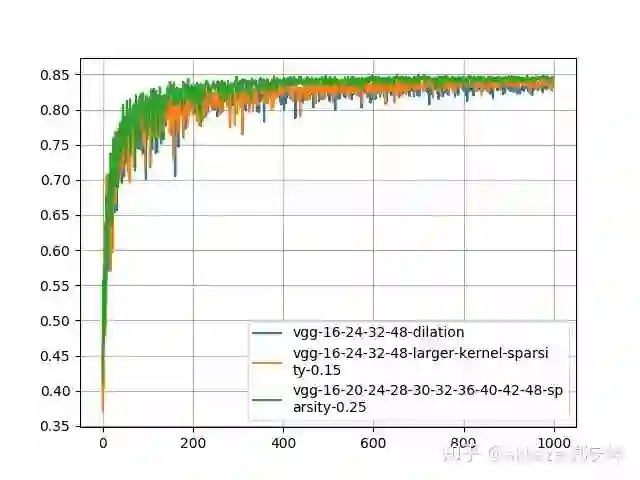
这个时候级联3x3网络的性能已经远超其他两个网络了(对于cifar100上的baseline取多少合适,大家可以参阅一些文章或博客)。
稀疏化极限的思考
我们上面的讨论基本就是,只要能保住某个感受野,稀疏化也是可行的,但是又不禁想知道稀疏化的极限在哪里,对于3x3的卷积核,在保住感受野的情况下,最少必须有两个非零元素,但是这样一来卷积核就退化了,从各向同性退化为各向异性,
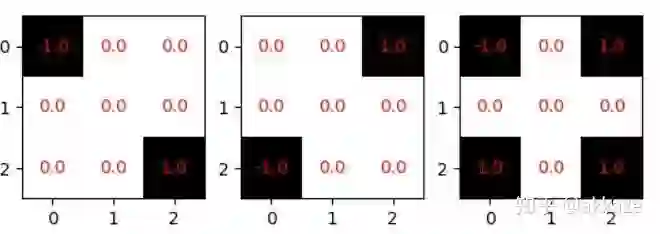
前面两个卷积核只有一个方向性(对角线方向),最后一个有两个方向性
学过线性代数的同学都知道,在二维线性空间至少有两个基底向量,才能合成各种方向的梯度。如果卷积核退化成前面两个的情况下,卷积核的二维性质也许就损失掉了,但是同一层中只要有多个卷积核具有不同的方向性,那么这一层依然可能是各向同性的,方向性也许也是感受野的一个重要描述。关于感受野的方向性,一个来自视觉皮层实验的启示如下:
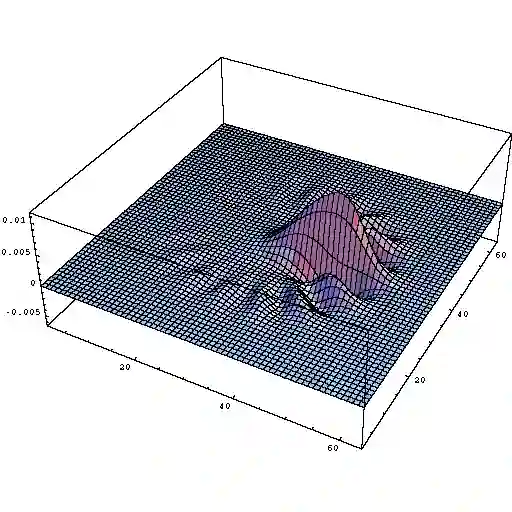
人类视觉皮层中不同方位调谐的感受野分布
感受野的意义。只有大感受野才能感受到尺寸比较大的物体。感受野,深度和通道数,共同决定了cnn某一层的性能,一个衡量cnn性能的正确表述应该是网络在某一层有多大的深度和感受野,同时有多少通道。深度决定了网络的抽象能力或者说学习能力,感受野和通道决定了网络学到了多少东西
maxpooling的额外讨论

分割网络的设计

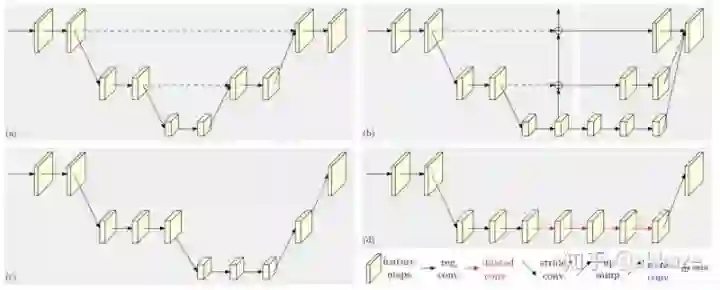
后续讨论,对网络设计的可能影响
Input-->Conv(dilate_rate=1)-->Conv(dilate_rate=2)-->Conv(dilate_rate=4)-->Conv(dilate_rate=8)-->GAP-->Conv1x1-->Softmax-->Output
Input-->Conv(dilate_rate=1)-->Conv(dilate_rate=2)-->Conv(dilate_rate=4)-->Conv(dilate_rate=8)-->Conv(dilate_rate=16)-->Conv(dilate_rate=32)-->Softmax-->Output
对跨层连接的思考
对目标检测的可能影响
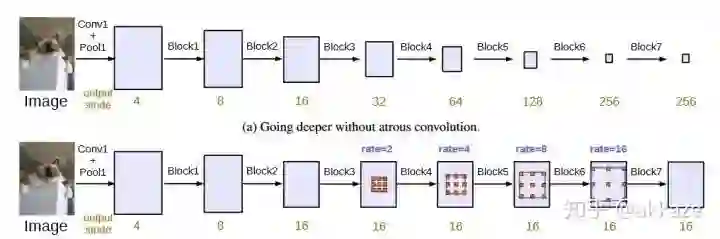
总结
一句话说来,CNN一种利用卷积实现二维泛函空间到二维泛函空间映射的神经网络。
-End-
CV细分方向交流群
添加极市小助手微信(ID : cv-mart),备注:研究方向-姓名-学校/公司-城市(如:目标检测-小极-北大-深圳),即可申请加入目标检测、目标跟踪、人脸、工业检测、医学影像、三维&SLAM、图像分割、姿态估计、超分辨率、嵌入式视觉、OCR 等极市技术交流群(已经添加小助手的好友直接私信),更有每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流,一起来让思想之光照的更远吧~

△长按添加极市小助手

△长按关注极市平台
觉得有用麻烦给个在看啦~



